
 Github
Github 文档
文档 论文
论文InceptionNeXt:当Inception遇上ConvNeXt


这是我们论文"InceptionNeXt:当Inception遇上ConvNeXt"中提出的InceptionNeXt的PyTorch实现。非常感谢Ross Wightman,InceptionNeXt已被整合到timm中。
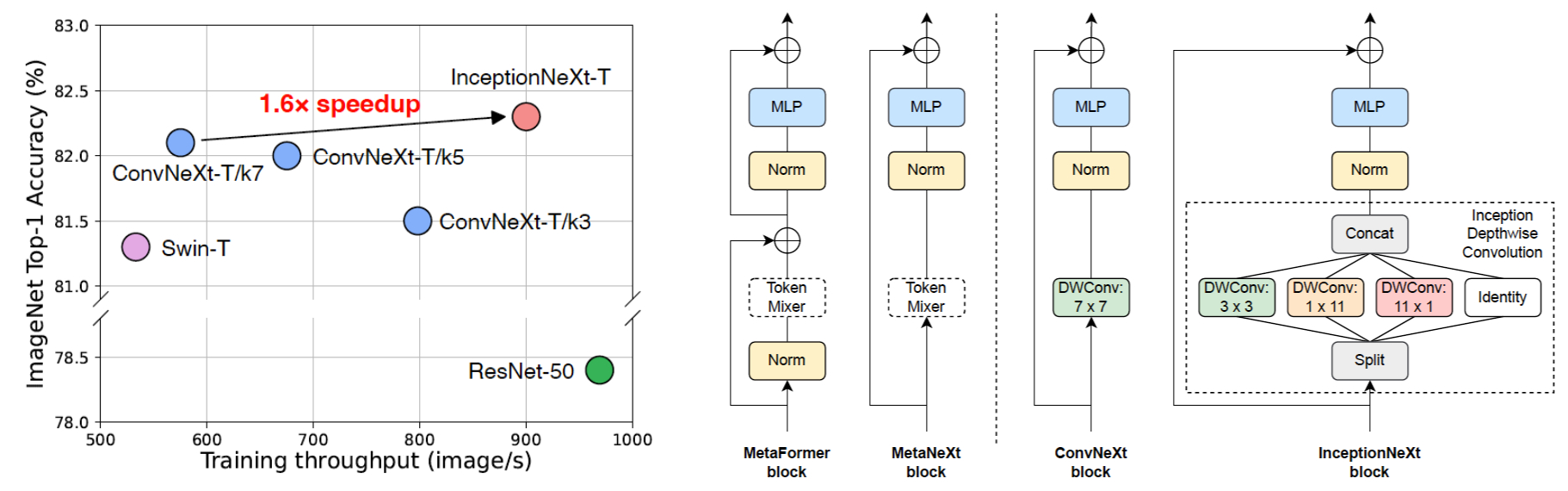 简述:为了加速ConvNeXt,我们通过以Inception风格分解大型深度卷积核来构建InceptionNeXt。我们的InceptionNeXt-T同时兼具ResNet-50的速度和ConvNeXt-T的准确性。
简述:为了加速ConvNeXt,我们通过以Inception风格分解大型深度卷积核来构建InceptionNeXt。我们的InceptionNeXt-T同时兼具ResNet-50的速度和ConvNeXt-T的准确性。
环境要求
我们的模型在PyTorch 1.13、NVIDIA CUDA 11.7.1和timm 0.6.11(pip install timm==0.6.11)环境中训练和测试。如果使用Docker,请查看我们使用的Dockerfile。
数据准备:ImageNet数据集应具有以下文件夹结构,你可以使用这个脚本提取ImageNet。
│imagenet/
├──train/
│ ├── n01440764
│ │ ├── n01440764_10026.JPEG
│ │ ├── n01440764_10027.JPEG
│ │ ├── ......
│ ├── ......
├──val/
│ ├── n01440764
│ │ ├── ILSVRC2012_val_00000293.JPEG
│ │ ├── ILSVRC2012_val_00002138.JPEG
│ │ ├── ......
│ ├── ......
模型
在ImageNet-1K上训练的InceptionNeXt
| 模型 | 分辨率 | 参数量 | MACs | 训练吞吐量 | 推理吞吐量 | Top1准确率 |
|---|---|---|---|---|---|---|
| resnet50 | 224 | 26M | 4.1G | 969 | 3149 | 78.4 |
| convnext_tiny | 224 | 29M | 4.5G | 575 | 2413 | 82.1 |
| inceptionnext_tiny | 224 | 28M | 4.2G | 901 | 2900 | 82.3 |
| inceptionnext_small | 224 | 49M | 8.4G | 521 | 1750 | 83.5 |
| inceptionnext_base | 224 | 87M | 14.9G | 375 | 1244 | 84.0 |
| inceptionnext_base_384 | 384 | 87M | 43.6G | 139 | 428 | 85.2 |
在ImageNet-1K上训练的ConvNeXt变体
| 模型 | 分辨率 | 参数量 | MACs | 训练吞吐量 | 推理吞吐量 | Top1准确率 |
|---|---|---|---|---|---|---|
| resnet50 | 224 | 26M | 4.1G | 969 | 3149 | 78.4 |
| convnext_tiny | 224 | 29M | 4.5G | 575 | 2413 | 82.1 |
| convnext_tiny_k5 | 224 | 29M | 4.4G | 675 | 2704 | 82.0 |
| convnext_tiny_k3 | 224 | 28M | 4.4G | 798 | 2802 | 81.5 |
| convnext_tiny_k3_par1_2 | 224 | 28M | 4.4G | 818 | 2740 | 81.4 |
| convnext_tiny_k3_par3_8 | 224 | 28M | 4.4G | 847 | 2762 | 81.4 |
| convnext_tiny_k3_par1_4 | 224 | 28M | 4.4G | 871 | 2808 | 81.3 |
| convnext_tiny_k3_par1_8 | 224 | 28M | 4.4G | 901 | 2833 | 80.8 |
| convnext_tiny_k3_par1_16 | 224 | 28M | 4.4G | 916 | 2846 | 80.1 |
吞吐量是在A100上使用全精度和128的批量大小测量的。详见吞吐量基准测试。
使用方法
我们还提供了一个Colab笔记本,其中包含使用InceptionNeXt进行推理的步骤:
验证
要评估我们的CAFormer-S18模型,请运行:
MODEL=inceptionnext_tiny
python3 validate.py /path/to/imagenet --model $MODEL -b 128 \
--pretrained
吞吐量基准测试
在上述环境中,我们在A100上使用128的批量大小进行吞吐量基准测试。报告的是"Channel First"和"Channel Last"内存布局中较好的结果。
对于Channel First:
MODEL=inceptionnext_tiny # convnext_tiny
python3 benchmark.py /path/to/imagenet --model $MODEL
对于Channel Last:
MODEL=inceptionnext_tiny # convnext_tiny
python3 benchmark.py /path/to/imagenet --model $MODEL --channel-last
训练
我们默认使用4096的批量大小,并展示如何使用8个GPU进行训练。对于多节点训练,请根据实际情况调整--grad-accum-steps。
DATA_PATH=/path/to/imagenet
CODE_PATH=/path/to/code/inceptionnext # 在此修改代码路径
ALL_BATCH_SIZE=4096
NUM_GPU=8
GRAD_ACCUM_STEPS=4 # 根据您的GPU数量和内存大小进行调整
let BATCH_SIZE=ALL_BATCH_SIZE/NUM_GPU/GRAD_ACCUM_STEPS
MODEL=inceptionnext_tiny # inceptionnext_small, inceptionnext_base
DROP_PATH=0.1 # 0.3, 0.4
cd $CODE_PATH && sh distributed_train.sh $NUM_GPU $DATA_PATH \
--model $MODEL --opt adamw --lr 4e-3 --warmup-epochs 20 \
-b $BATCH_SIZE --grad-accum-steps $GRAD_ACCUM_STEPS \
--drop-path $DROP_PATH
其他模型的训练(微调)脚本可在scripts中找到。
引用
@article{yu2023inceptionnext,
title={InceptionNeXt: when inception meets convnext},
author={Yu, Weihao and Zhou, Pan and Yan, Shuicheng and Wang, Xinchao},
journal={arXiv preprint arXiv:2303.16900},
year={2023}
}
致谢
Weihao Yu感谢TRC项目和GCP研究积分对部分计算资源的支持。我们的实现基于pytorch-image-models、poolformer、ConvNeXt和metaformer。











