
 Github
Github Huggingface
Huggingface 论文
论文MetaFormer视觉基线 (TPAMI 2024)


这是我们论文"MetaFormer视觉基线"中提出的几个MetaFormer基线的PyTorch实现,包括IdentityFormer、RandFormer、ConvFormer和CAFormer。
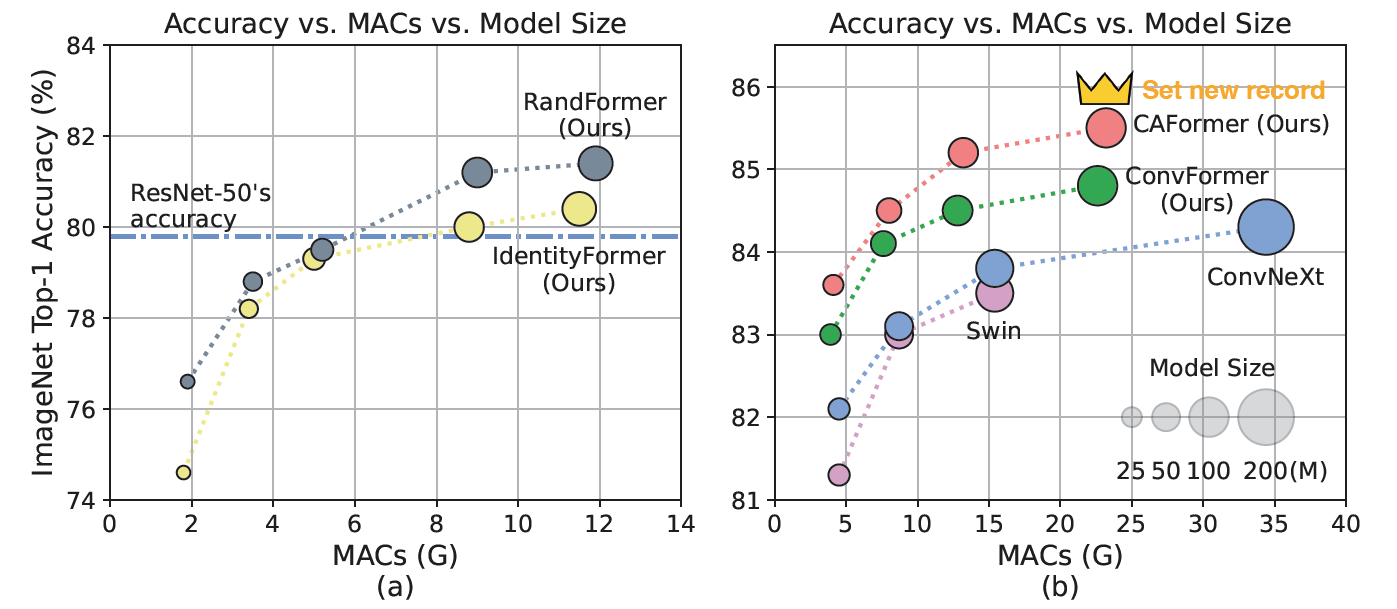 图1: MetaFormer基线和其他最先进模型在ImageNet-1K上224x224分辨率的性能。 我们提出的模型架构如图2所示。(a) IdentityFormer/RandFormer达到超过80%/81%的准确率,表明MetaFormer具有坚实的性能下限,并且在任意token混合器上都能很好地工作。训练良好的ResNet-50的准确率来自"ResNet strikes back"。(b) 没有新颖的token混合器,纯CNN-based的ConvFormer优于ConvNeXt,而CAFormer在正常监督训练下,不使用外部数据或蒸馏的情况下,在ImageNet-1K上224x224分辨率达到了85.5%的新记录准确率。
图1: MetaFormer基线和其他最先进模型在ImageNet-1K上224x224分辨率的性能。 我们提出的模型架构如图2所示。(a) IdentityFormer/RandFormer达到超过80%/81%的准确率,表明MetaFormer具有坚实的性能下限,并且在任意token混合器上都能很好地工作。训练良好的ResNet-50的准确率来自"ResNet strikes back"。(b) 没有新颖的token混合器,纯CNN-based的ConvFormer优于ConvNeXt,而CAFormer在正常监督训练下,不使用外部数据或蒸馏的情况下,在ImageNet-1K上224x224分辨率达到了85.5%的新记录准确率。
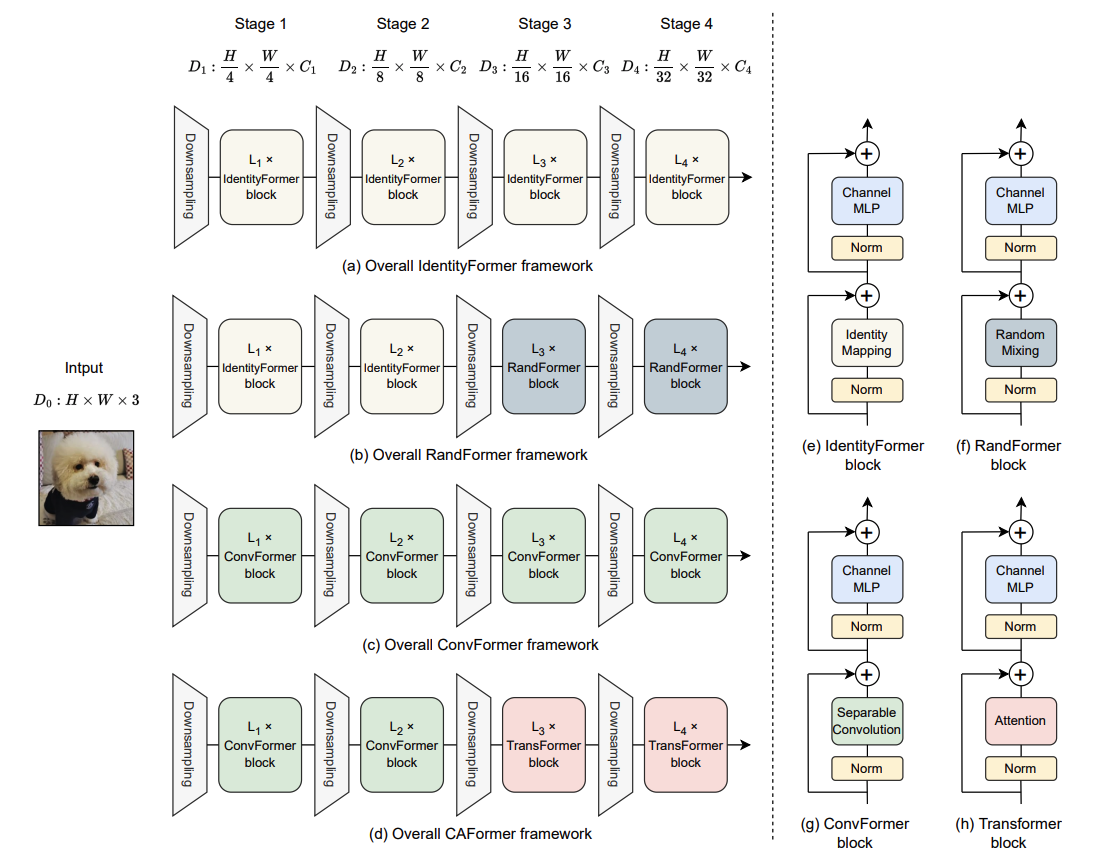 图2: (a-d) IdentityFormer、RandFormer、ConvFormer和CAFormer的整体框架。 与ResNet类似,这些模型采用4个阶段的层次架构,第$i$阶段有$L_i$个块,特征维度为$D_i$。每个下采样模块由一层卷积实现。第一个下采样的核大小为7,步幅为4,而最后三个下采样的核大小为3,步幅为2。(e-h) IdentityFormer、RandFormer、ConvFormer和Transformer块的架构,它们分别具有恒等映射、全局随机混合、可分离深度卷积或普通自注意力的token混合器。
图2: (a-d) IdentityFormer、RandFormer、ConvFormer和CAFormer的整体框架。 与ResNet类似,这些模型采用4个阶段的层次架构,第$i$阶段有$L_i$个块,特征维度为$D_i$。每个下采样模块由一层卷积实现。第一个下采样的核大小为7,步幅为4,而最后三个下采样的核大小为3,步幅为2。(e-h) IdentityFormer、RandFormer、ConvFormer和Transformer块的架构,它们分别具有恒等映射、全局随机混合、可分离深度卷积或普通自注意力的token混合器。
新闻
MetaFormer基线的模型现已由Fredo Guan和Ross Wightman集成到timm中。非常感谢!
要求
torch>=1.7.0; torchvision>=0.8.0; pyyaml; timm (pip install timm==0.6.11)
数据准备:ImageNet的文件夹结构如下,你可以使用这个脚本提取ImageNet。
│imagenet/
├──train/
│ ├── n01440764
│ │ ├── n01440764_10026.JPEG
│ │ ├── n01440764_10027.JPEG
│ │ ├── ......
│ ├── ......
├──val/
│ ├── n01440764
│ │ ├── ILSVRC2012_val_00000293.JPEG
│ │ ├── ILSVRC2012_val_00002138.JPEG
│ │ ├── ......
│ ├── ......
MetaFormer基线
在ImageNet-1K上训练的具有常见token混合器的模型
| 模型 | 分辨率 | 参数 | MACs | Top1准确率 | 下载 |
|---|---|---|---|---|---|
| caformer_s18 | 224 | 26M | 4.1G | 83.6 | 这里 |
| caformer_s18_384 | 384 | 26M | 13.4G | 85.0 | 这里 |
| caformer_s36 | 224 | 39M | 8.0G | 84.5 | 这里 |
| caformer_s36_384 | 384 | 39M | 26.0G | 85.7 | 这里 |
| caformer_m36 | 224 | 56M | 13.2G | 85.2 | 这里 |
| caformer_m36_384 | 384 | 56M | 42.0G | 86.2 | 这里 |
| caformer_b36 | 224 | 99M | 23.2G | 85.5* | 这里 |
| caformer_b36_384 | 384 | 99M | 72.2G | 86.4 | 这里 |
| convformer_s18 | 224 | 27M | 3.9G | 83.0 | 这里 |
| convformer_s18_384 | 384 | 27M | 11.6G | 84.4 | 这里 |
| convformer_s36 | 224 | 40M | 7.6G | 84.1 | 这里 |
| convformer_s36_384 | 384 | 40M | 22.4G | 85.4 | 这里 |
| convformer_m36 | 224 | 57M | 12.8G | 84.5 | 这里 |
| convformer_m36_384 | 384 | 57M | 37.7G | 85.6 | 这里 |
| convformer_b36 | 224 | 100M | 22.6G | 84.8 | 这里 |
| convformer_b36_384 | 384 | 100M | 66.5G | 85.7 | 这里 |
:astonished: :astonished: * 据我们所知,该模型在正常监督设置下(无外部数据或蒸馏)在ImageNet-1K上224x224分辨率达到了85.5%的新准确率记录。
在ImageNet-21K上预训练并在ImageNet-1K上微调的具有常见token混合器的模型
| 模型 | 分辨率 | 参数 | MACs | Top1准确率 | 下载 |
|---|---|---|---|---|---|
| caformer_s18_in21ft1k | 224 | 26M | 4.1G | 84.1 | 这里 |
| caformer_s18_384_in21ft1k | 384 | 26M | 13.4G | 85.4 | 这里 |
| caformer_s36_in21ft1k | 224 | 39M | 8.0G | 85.8 | 这里 |
| caformer_s36_384_in21ft1k | 384 | 39M | 26.0G | 86.9 | 这里 |
| caformer_m36_in21ft1k | 224 | 56M | 13.2G | 86.6 | 这里 |
| caformer_m36_384_in21ft1k | 384 | 56M | 42.0G | 87.5 | 这里 |
| caformer_b36_in21ft1k | 224 | 99M | 23.2G | 87.4 | 这里 |
| caformer_b36_384_in21ft1k | 384 | 99M | 72.2G | 88.1 | 这里 |
| convformer_s18_in21ft1k | 224 | 27M | 3.9G | 83.7 | 这里 |
| convformer_s18_384_in21ft1k | 384 | 27M | 11.6G | 85.0 | 这里 |
| convformer_s36_in21ft1k | 224 | 40M | 7.6G | 85.4 | 这里 |
| convformer_s36_384_in21ft1k | 384 | 40M | 22.4G | 86.4 | 这里 |
| convformer_m36_in21ft1k | 224 | 57M | 12.8G | 86.1 | 这里 |
| convformer_m36_384_in21ft1k | 384 | 57M | 37.7G | 86.9 | 这里 |
| convformer_b36_in21ft1k | 224 | 100M | 22.6G | 87.0 | 这里 |
| convformer_b36_384_in21kft1k | 384 | 100M | 66.5G | 87.6 | 这里 |
在ImageNet-21K上预训练的具有常见令牌混合器的模型
| 模型 | 分辨率 | 下载 |
|---|---|---|
| caformer_s18_in21k | 224 | 这里 |
| caformer_s36_in21k | 224 | 这里 |
| caformer_m36_in21k | 224 | 这里 |
| caformer_b36_in21k | 224 | 这里 |
| convformer_s18_in21k | 224 | 这里 |
| convformer_s36_in21k | 224 | 这里 |
| convformer_m36_in21k | 224 | 这里 |
| convformer_b36_in21k | 224 | 这里 |
在ImageNet-1K上训练的具有基本令牌混合器的模型
| 模型 | 分辨率 | 参数 | MACs | Top1 准确率 | 下载 |
|---|---|---|---|---|---|
| identityformer_s12 | 224 | 11.9M | 1.8G | 74.6 | 这里 |
| identityformer_s24 | 224 | 21.3M | 3.4G | 78.2 | 这里 |
| identityformer_s36 | 224 | 30.8M | 5.0G | 79.3 | 这里 |
| identityformer_m36 | 224 | 56.1M | 8.8G | 80.0 | 这里 |
| identityformer_m48 | 224 | 73.3M | 11.5G | 80.4 | 这里 |
| randformer_s12 | 224 | 11.9 + 0.2M | 1.9G | 76.6 | 这里 |
| randformer_s24 | 224 | 21.3 + 0.5M | 3.5G | 78.2 | 这里 |
| randformer_s36 | 224 | 30.8 + 0.7M | 5.2G | 79.5 | 这里 |
| randformer_m36 | 224 | 56.1 + 0.7M | 9.0G | 81.2 | 这里 |
| randformer_m48 | 224 | 73.3 + 0.9M | 11.9G | 81.4 | 这里 |
| poolformerv2_s12 | 224 | 11.9M | 1.8G | 78.0 | 这里 |
| poolformerv2_s24 | 224 | 21.3M | 3.4G | 80.7 | 这里 |
| poolformerv2_s36 | 224 | 30.8M | 5.0G | 81.6 | 这里 |
| poolformerv2_m36 | 224 | 56.1M | 8.8G | 82.2 | 这里 |
| poolformerv2_m48 | 224 | 73.3M | 11.5G | 82.6 | 这里 |
带下划线的数字表示随机初始化后冻结的参数数量。
这些检查点也可以在百度网盘中找到。
使用方法
我们还提供了一个Colab笔记本,其中包含使用MetaFormer基线进行推理的步骤:
验证
要评估我们的CAFormer-S18模型,运行:
MODEL=caformer_s18
python3 validate.py /path/to/imagenet --model $MODEL -b 128 \
--checkpoint /path/to/checkpoint
训练
我们默认使用4096的批量大小,我们展示了如何使用8个GPU进行训练。对于多节点训练,请根据您的情况调整--grad-accum-steps。
DATA_PATH=/path/to/imagenet
CODE_PATH=/path/to/code/metaformer # 在此修改代码路径
ALL_BATCH_SIZE=4096
NUM_GPU=8
GRAD_ACCUM_STEPS=4 # 根据您的GPU数量和内存大小进行调整。
let BATCH_SIZE=ALL_BATCH_SIZE/NUM_GPU/GRAD_ACCUM_STEPS
cd $CODE_PATH && sh distributed_train.sh $NUM_GPU $DATA_PATH \
--model convformer_s18 --opt adamw --lr 4e-3 --warmup-epochs 20 \
-b $BATCH_SIZE --grad-accum-steps $GRAD_ACCUM_STEPS \
--drop-path 0.2 --head-dropout 0.0
其他模型的训练(微调)脚本显示在scripts中。
致谢
Weihao Yu感谢TRC计划和GCP研究积分对部分计算资源的支持。我们的实现基于wonderful pytorch-image-models代码库。
Bibtex
@article{yu2024metaformer,
author={Yu, Weihao and Si, Chenyang and Zhou, Pan and Luo, Mi and Zhou, Yichen and Feng, Jiashi and Yan, Shuicheng and Wang, Xinchao},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
title={MetaFormer Baselines for Vision},
year={2024},
volume={46},
number={2},
pages={896-912},
doi={10.1109/TPAMI.2023.3329173}}
}











