
 访问官网
访问官网 Github
Github 文档
文档 论文
论文

OmniXAI:可解释人工智能库



目录
最新动态
最新版本包含一个实验性的GPT解释器。这个解释器利用SHAP和MACE产生的结果来构建ChatGPT的输入提示。随后,ChatGPT分析这些结果并生成相应的解释,为开发人员提供对模型预测背后原理的更清晰理解。
简介
OmniXAI(全称为Omni eXplainable AI)是一个用于可解释人工智能(XAI)的Python机器学习库,提供全方位的可解释AI和可解释机器学习能力,以解决实践中机器学习模型决策解释的诸多痛点。OmniXAI旨在成为一站式综合库,为数据科学家、机器学习研究人员和从业者提供便利,满足他们在机器学习过程不同阶段对各种数据类型、模型和解释方法的解释需求:
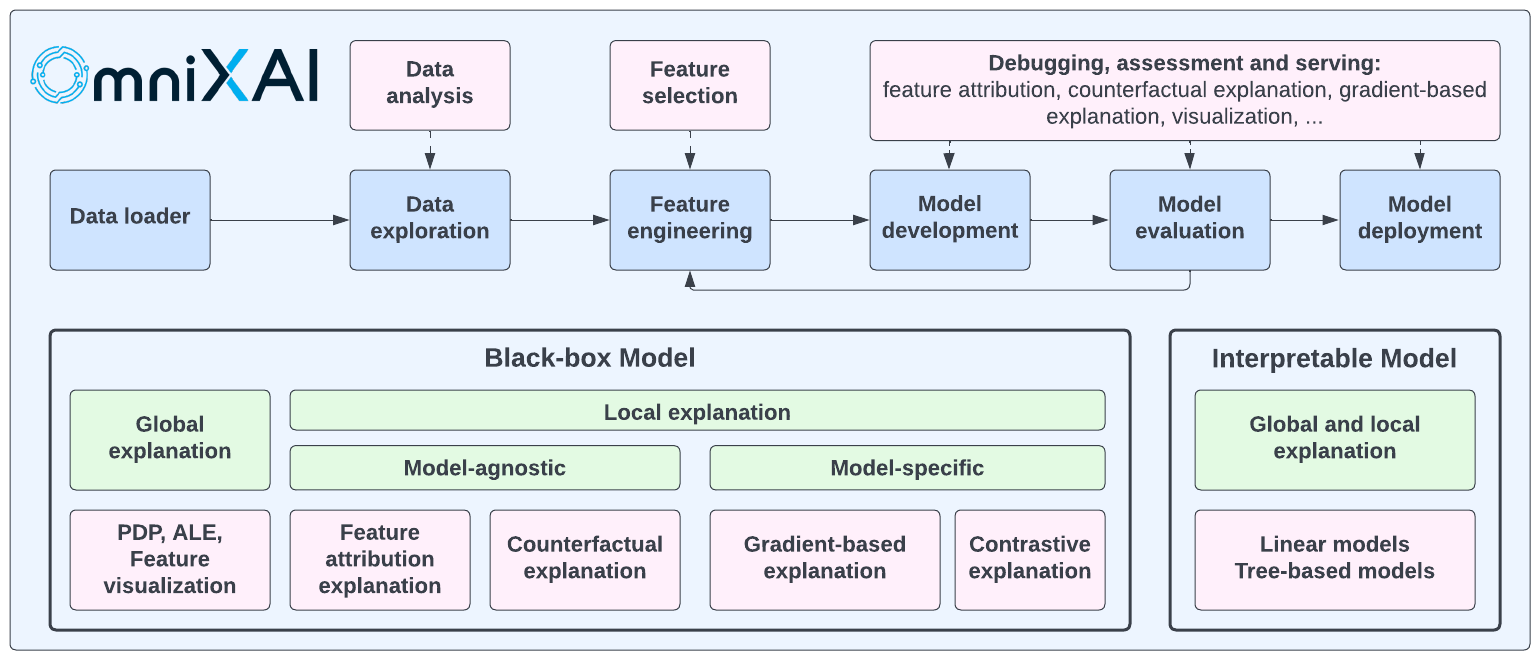
OmniXAI包含丰富的解释方法,集成在统一的接口中,支持多种数据类型(表格数据、图像、文本、时间序列),多种机器学习模型类型(Scikit-learn中的传统机器学习和PyTorch/TensorFlow中的深度学习模型),以及一系列多样化的解释方法,包括"模型特定"和"模型无关"方法(如特征归因解释、反事实解释、基于梯度的解释、特征可视化等)。对于从业者而言,OmniXAI提供了一个易于使用的统一接口,只需编写几行代码即可为他们的应用生成解释,并提供用于可视化的GUI仪表盘,以获得对决策的更多洞察。
下表显示了我们库中支持的解释方法和功能。我们将继续改进这个库,使其在未来更加全面。
| 方法 | 模型类型 | 解释类型 | 探索性数据分析 | 表格 | 图像 | 文本 | 时间序列 |
|---|---|---|---|---|---|---|---|
| 特征分析 | 不适用 | 全局 | ✅ | ||||
| 特征选择 | 不适用 | 全局 | ✅ | ||||
| 预测指标 | 黑盒 | 全局 | ✅ | ✅ | ✅ | ✅ | |
| 偏差指标 | 黑盒 | 全局 | ✅ | ||||
| 部分依赖图 | 黑盒 | 全局 | ✅ | ||||
| 累积局部效应 | 黑盒 | 全局 | ✅ | ||||
| 敏感性分析 | 黑盒 | 全局 | ✅ | ||||
| 排列重要性解释 | 黑盒 | 全局 | ✅ | ||||
| 特征可视化 | Torch或TF | 全局 | ✅ | ||||
| 特征图 | Torch或TF | 局部 | ✅ | ||||
| GPT解释器 | 黑盒 | 局部 | ✅ | ||||
| LIME | 黑盒 | 局部 | ✅ | ✅ | ✅ | ||
| SHAP | 黑盒* | 局部 | ✅ | ✅ | ✅ | ✅ | |
| 假设分析 | 黑盒 | 局部 | ✅ | ||||
| 积分梯度 | Torch或TF | 局部 | ✅ | ✅ | ✅ | ||
| 反事实 | 黑盒* | 局部 | ✅ | ✅ | ✅ | ✅ | |
| 对比解释 | Torch或TF | 局部 | ✅ | ||||
| Grad-CAM, Grad-CAM++ | Torch或TF | 局部 | ✅ | ||||
| Score-CAM | Torch或TF | 局部 | ✅ | ||||
| Layer-CAM | Torch或TF | 局部 | ✅ | ||||
| 平滑梯度 | Torch或TF | 局部 | ✅ | ||||
| 引导反向传播 | Torch或TF | 局部 | ✅ | ||||
| 学习解释 | 黑盒 | 局部 | ✅ | ✅ | ✅ | ||
| 线性模型 | 线性模型 | 全局和局部 | ✅ | ||||
| 树模型 | 树模型 | 全局和局部 | ✅ |
SHAP 接受表格数据的黑盒模型、图像数据的PyTorch/Tensorflow模型、文本数据的transformer模型。反事实接受表格、文本和时间序列数据的黑盒模型,以及图像数据的PyTorch/Tensorflow模型。
这个表格展示了我们的工具包/库与文献中其他现有XAI工具包/库的比较。
OmniXAI还集成了ChatGPT,用于为表格数据集上的分类/回归模型生成纯文本解释。 生成的结果可能不是100%准确,但值得尝试这个解释器(我们将继续改进输入提示)。
安装
你可以通过调用pip install omnixai从PyPI安装omnixai。你也可以通过克隆OmniXAI仓库,导航到根目录,并调用pip install .或pip install -e .以可编辑模式从源代码安装。你可以安装额外的依赖:
- 用于绘图和可视化:调用
pip install omnixai[plot],或从仓库根目录调用pip install .[plot]。 - 用于视觉任务:调用
pip install omnixai[vision],或从仓库根目录调用pip install .[vision]。 - 用于NLP任务:调用
pip install omnixai[nlp],或从仓库根目录调用pip install .[nlp]。 - 安装所有依赖:调用
pip install omnixai[all],或从仓库根目录调用pip install .[all]。
入门
有关示例代码和库介绍,请参阅教程中的Jupyter笔记本,以及这里的引导性演练。 一些示例:
要开始使用,我们推荐查看教程中的链接。
一般来说,我们建议分别使用TabularExplainer、VisionExplainer、NLPExplainer和TimeseriesExplainer来处理表格、视觉、自然语言处理和时间序列任务,并使用DataAnalyzer和PredictionAnalyzer进行特征分析和预测结果分析。
这些类作为OmniXAI支持的各个解释器的工厂,提供了一个更简单的接口来生成多种解释。要生成解释,你只需要指定:
- 要解释的机器学习模型:例如,一个scikit-learn模型、tensorflow模型、pytorch模型或黑盒预测函数。
- 预处理函数:即将原始输入特征转换为模型输入。
- 后处理函数(可选):例如,将模型输出转换为类别概率。
- 要应用的解释器:例如,SHAP、MACE、Grad-CAM。
除了使用这些类,你还可以创建omnixai.explainers包中定义的单个解释器,例如ShapTabular、GradCAM、IntegratedGradient或FeatureVisualizer。
让我们以收入预测任务为例。
本例中使用的数据集是用于收入预测的。
我们建议使用数据类Tabular来表示表格数据集。要根据pandas数据框创建Tabular实例,你需要指定数据框、分类特征名称(如果存在)和目标/标签列名(如果存在)。
from omnixai.data.tabular import Tabular
# 加载数据集
feature_names = [
"Age", "Workclass", "fnlwgt", "Education",
"Education-Num", "Marital Status", "Occupation",
"Relationship", "Race", "Sex", "Capital Gain",
"Capital Loss", "Hours per week", "Country", "label"
]
df = pd.DataFrame(
np.genfromtxt('adult.data', delimiter=', ', dtype=str),
columns=feature_names
)
tabular_data = Tabular(
df,
categorical_columns=[feature_names[i] for i in [1, 3, 5, 6, 7, 8, 9, 13]],
target_column='label'
)
omnixai.preprocessing包提供了几个用于Tabular实例的有用预处理函数。
TabularTransform是一种专为处理表格数据而设计的特殊转换。
默认情况下,它将分类特征转换为独热编码,并保留连续值特征。
TabularTransform的transform方法将Tabular实例转换为numpy数组。
如果Tabular实例有目标/标签列,numpy数组的最后一列将是目标/标签。
你可以应用任何自定义的预处理函数,而不是使用TabularTransform。
完成数据预处理后,让我们为这个任务训练一个XGBoost分类器。
from omnixai.preprocessing.tabular import TabularTransform
# 数据预处理
transformer = TabularTransform().fit(tabular_data)
class_names = transformer.class_names
x = transformer.transform(tabular_data)
# 分割训练集和测试集
train, test, train_labels, test_labels = \
sklearn.model_selection.train_test_split(x[:, :-1], x[:, -1], train_size=0.80)
# 训练XGBoost模型(转换后`x`的最后一列是标签列)
model = xgboost.XGBClassifier(n_estimators=300, max_depth=5)
model.fit(train, train_labels)
# 将转换后的数据转回Tabular实例
train_data = transformer.invert(train)
test_data = transformer.invert(test)
要初始化TabularExplainer,需要设置以下参数:
explainers:要应用的解释器名称,例如["lime", "shap", "mace", "pdp"]。data:用于初始化解释器的数据。data是用于训练机器学习模型的训练数据集。如果训练数据集太大,可以通过应用omnixai.sampler.tabular.Sampler.subsample来使用其子集作为data。model:要解释的机器学习模型,例如scikit-learn模型、tensorflow模型或pytorch模型。preprocess:将原始输入(一个Tabular实例)转换为model输入的预处理函数。postprocess(可选):将model的输出转换为用户特定形式的后处理函数,例如每个类别的预测概率。postprocess的输出应该是一个numpy数组。mode:任务类型,例如"classification"或"regression"。
预处理函数以Tabular实例作为输入,并输出机器学习模型所使用的处理后的特征。在这个例子中,我们只是调用transformer.transform。如果你在pandas数据框上使用一些自定义转换,预处理函数的格式应为:lambda z: some_transform(z.to_pd())。如果model的输出不是numpy数组,需要设置postprocess将其转换为numpy数组。
from omnixai.explainers.tabular import TabularExplainer
# 初始化一个TabularExplainer
explainer = TabularExplainer(
explainers=["lime", "shap", "mace", "pdp", "ale"], # 要应用的解释器
mode="classification", # 任务类型
data=train_data, # 用于初始化解释器的数据
model=model, # 要解释的机器学习模型
preprocess=lambda z: transformer.transform(z), # 将原始特征转换为模型输入
params={
"mace": {"ignored_features": ["Sex", "Race", "Relationship", "Capital Loss"]}
} # 额外参数
)
在这个例子中,LIME、SHAP和MACE生成局部解释,而PDP(部分依赖图)生成全局解释。explainer.explain方法返回由这三种方法针对测试实例生成的局部解释,而explainer.explain_global方法返回由PDP生成的全局解释。TabularExplainer隐藏了解释器背后的所有细节,因此我们可以简单地调用这两个方法来生成解释。
# 生成解释
test_instances = test_data[:5]
local_explanations = explainer.explain(X=test_instances)
global_explanations = explainer.explain_global(
params={"pdp": {"features": ["Age", "Education-Num", "Capital Gain",
"Capital Loss", "Hours per week", "Education",
"Marital Status", "Occupation"]}}
)
同样,我们创建一个PredictionAnalyzer来计算这个分类任务的性能指标。
要初始化PredictionAnalyzer,需要设置以下参数:
mode:任务类型,例如"classification"或"regression"。test_data:测试数据集,应该是一个Tabular实例。test_targets:测试标签或目标。对于分类,test_targets应该是整数(经过LabelEncoder处理),并与机器学习模型返回的类别概率相匹配。preprocess:预处理函数,将原始数据(Tabular实例)转换为model的输入。postprocess(可选):后处理函数,将model的输出转换为用户特定的形式,例如每个类别的预测概率。postprocess的输出应该是一个numpy数组。
from omnixai.explainers.prediction import PredictionAnalyzer
analyzer = PredictionAnalyzer(
mode="classification",
test_data=test_data, # 测试数据集(`Tabular`实例)
test_targets=test_labels, # 测试标签(numpy数组)
model=model, # 机器学习模型
preprocess=lambda z: transformer.transform(z) # 将原始特征转换为模型输入
)
prediction_explanations = analyzer.explain()
有了生成的解释,我们可以通过设置测试实例、局部解释、全局解释、预测指标、类别名称和可视化的额外参数(可选)来启动一个仪表板(Dash应用)进行可视化。如果你想进行"假设分析",可以在初始化仪表板时设置explainer参数。对于"假设分析",OmniXAI还允许你设置第二个解释器,以便比较不同的模型。
from omnixai.visualization.dashboard import Dashboard
# 启动仪表板进行可视化
dashboard = Dashboard(
instances=test_instances, # 要解释的实例
local_explanations=local_explanations, # 设置局部解释
global_explanations=global_explanations, # 设置全局解释
prediction_explanations=prediction_explanations, # 设置预测指标
class_names=class_names, # 设置类别名称
explainer=explainer # 创建的TabularExplainer,用于假设分析
)
dashboard.show() # 启动仪表板
在浏览器中打开Dash应用后,我们将看到一个显示解释的仪表板:
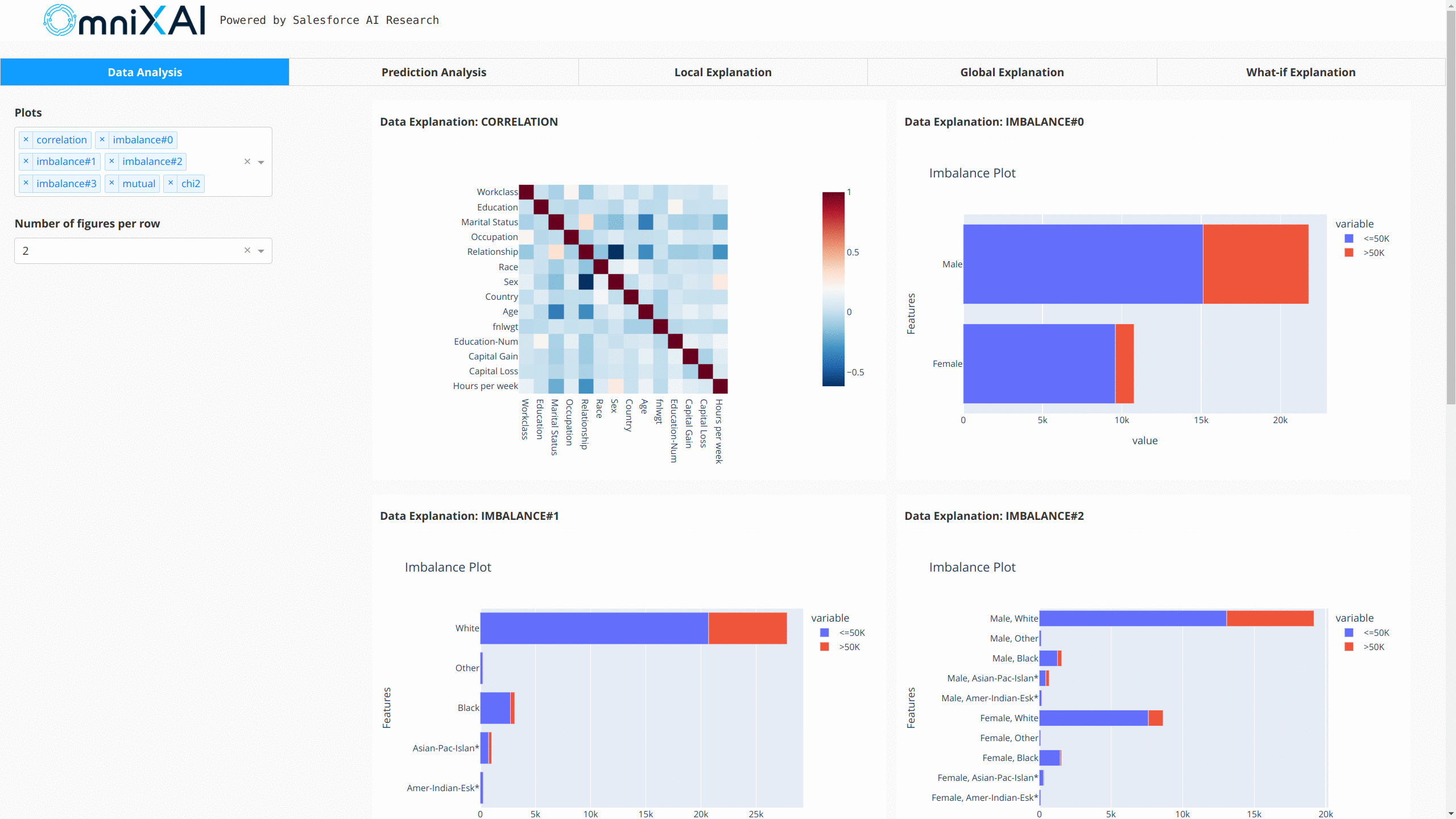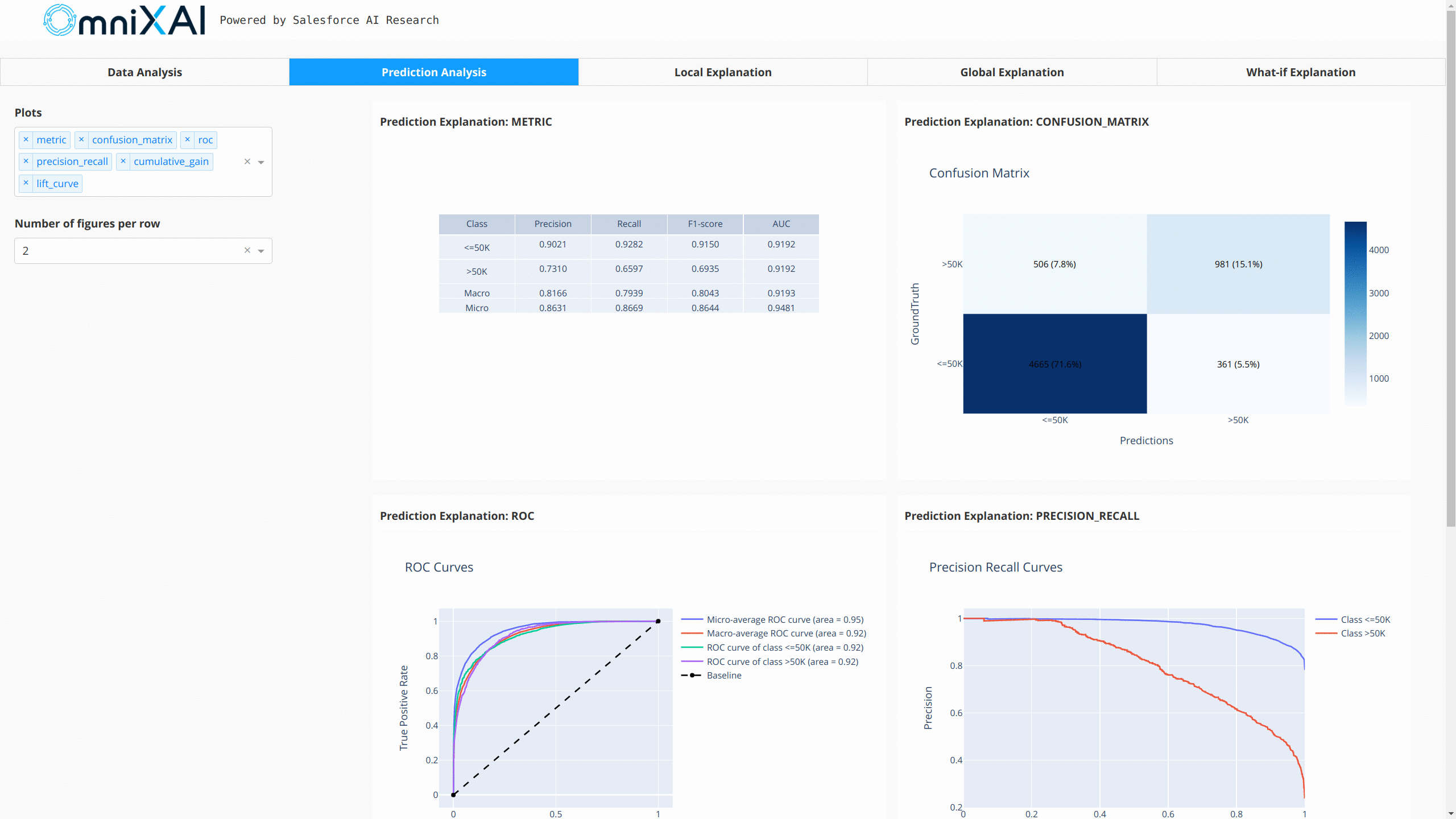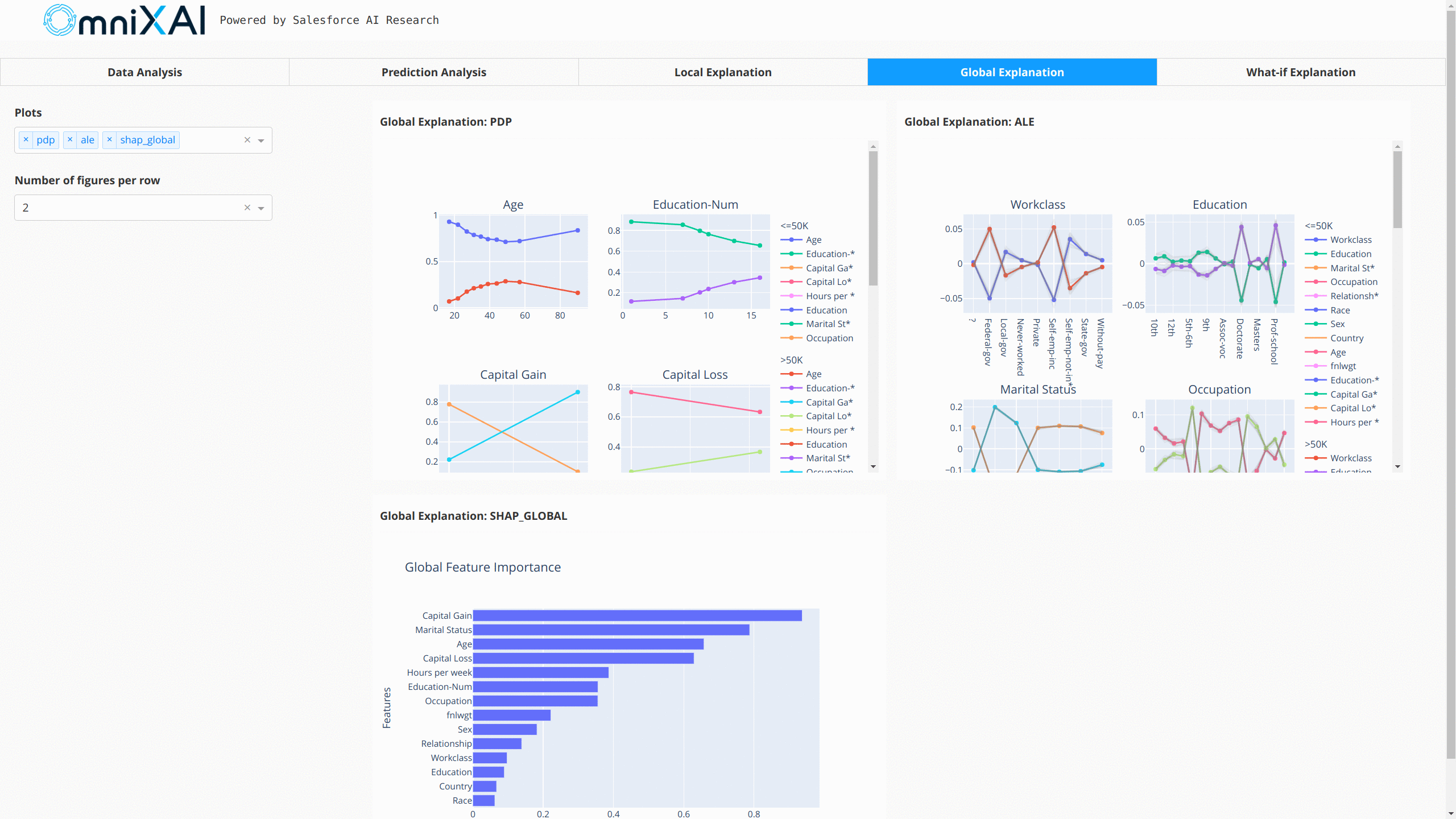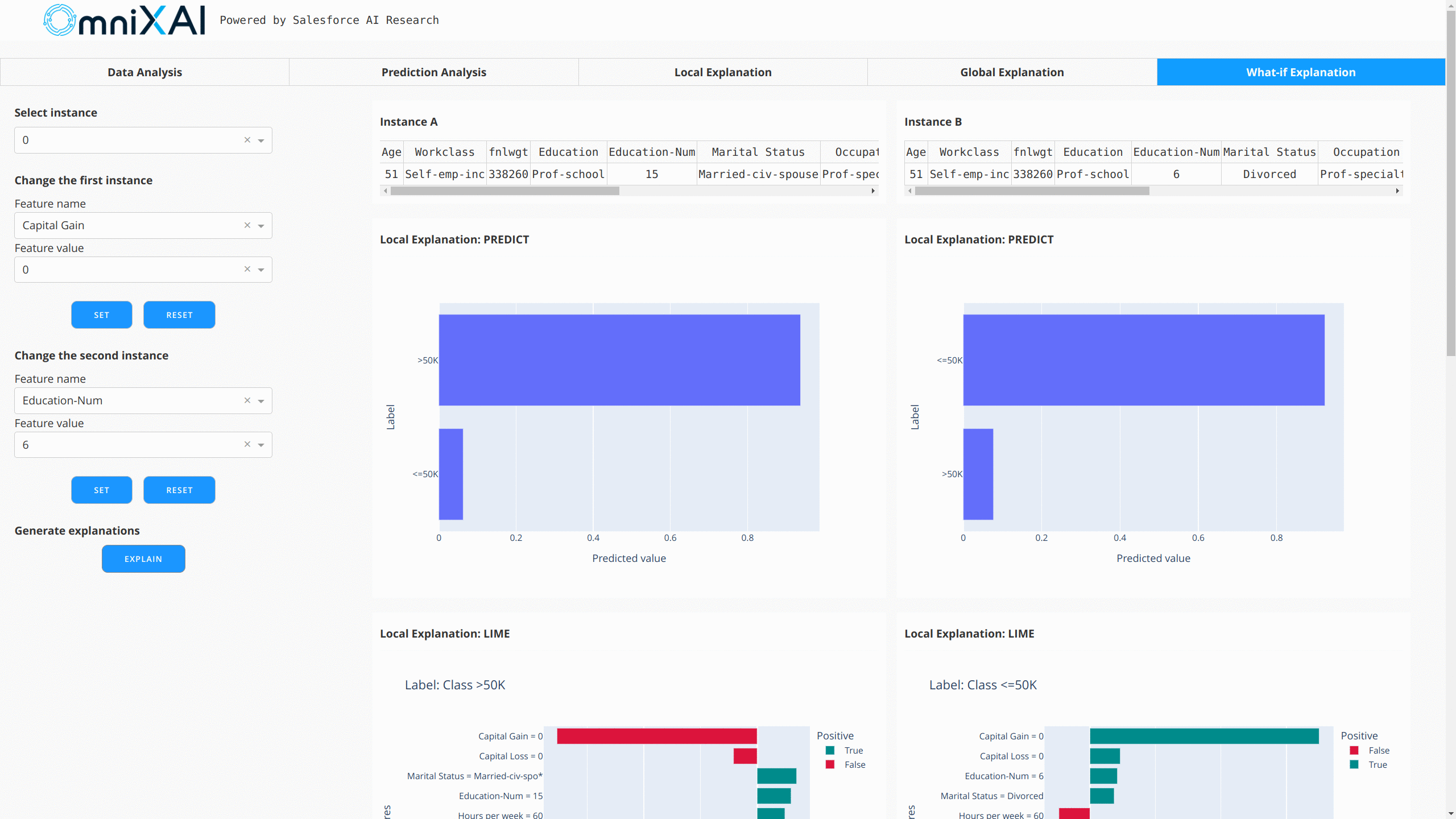
你也可以使用GPT解释器为表格模型生成文本形式的解释:
explainer = TabularExplainer(
explainers=["gpt"], # 要应用的GPT解释器
mode="classification", # 任务类型
data=train_data, # 用于初始化解释器的数据
model=model, # 要解释的机器学习模型
preprocess=lambda z: transformer.transform(z), # 将原始特征转换为模型输入
params={
"gpt": {"apikey": "xxxx"}
} # 设置OpenAI API密钥
)
local_explanations = explainer.explain(X=test_instances)
对于视觉任务,使用相同的接口来创建解释器和生成解释。 让我们以图像分类模型为例。
from omnixai.explainers.vision import VisionExplainer
from omnixai.visualization.dashboard import Dashboard
explainer = VisionExplainer(
explainers=["gradcam", "lime", "ig", "ce", "feature_visualization"],
mode="classification",
model=model, # 图像分类模型,如ResNet50
preprocess=preprocess, # 预处理函数
postprocess=postprocess, # 后处理函数
params={
# 为GradCAM设置目标层
"gradcam": {"target_layer": model.layer4[-1]},
# 为特征可视化设置目标
"feature_visualization":
{"objectives": [{"layer": model.layer4[-3], "type": "channel", "index": list(range(6))}]}
},
)
# 生成GradCAM、LIME、IG和CE的解释
local_explanations = explainer.explain(test_img)
# 生成特征可视化的解释
global_explanations = explainer.explain_global()
# 启动仪表板
dashboard = Dashboard(
instances=test_img,
local_explanations=local_explanations,
global_explanations=global_explanations
)
dashboard.show()
下图显示了这些解释的仪表板:
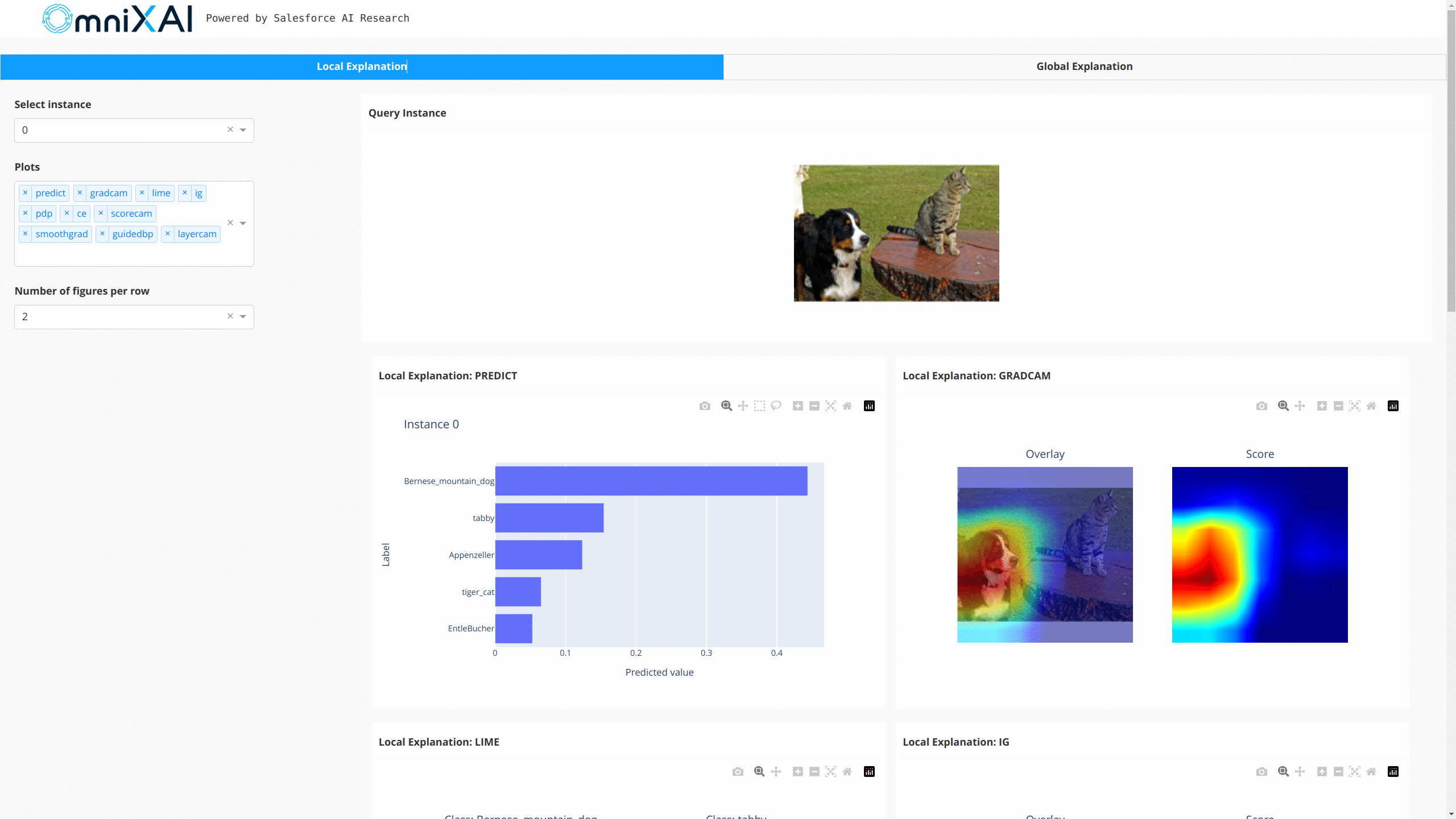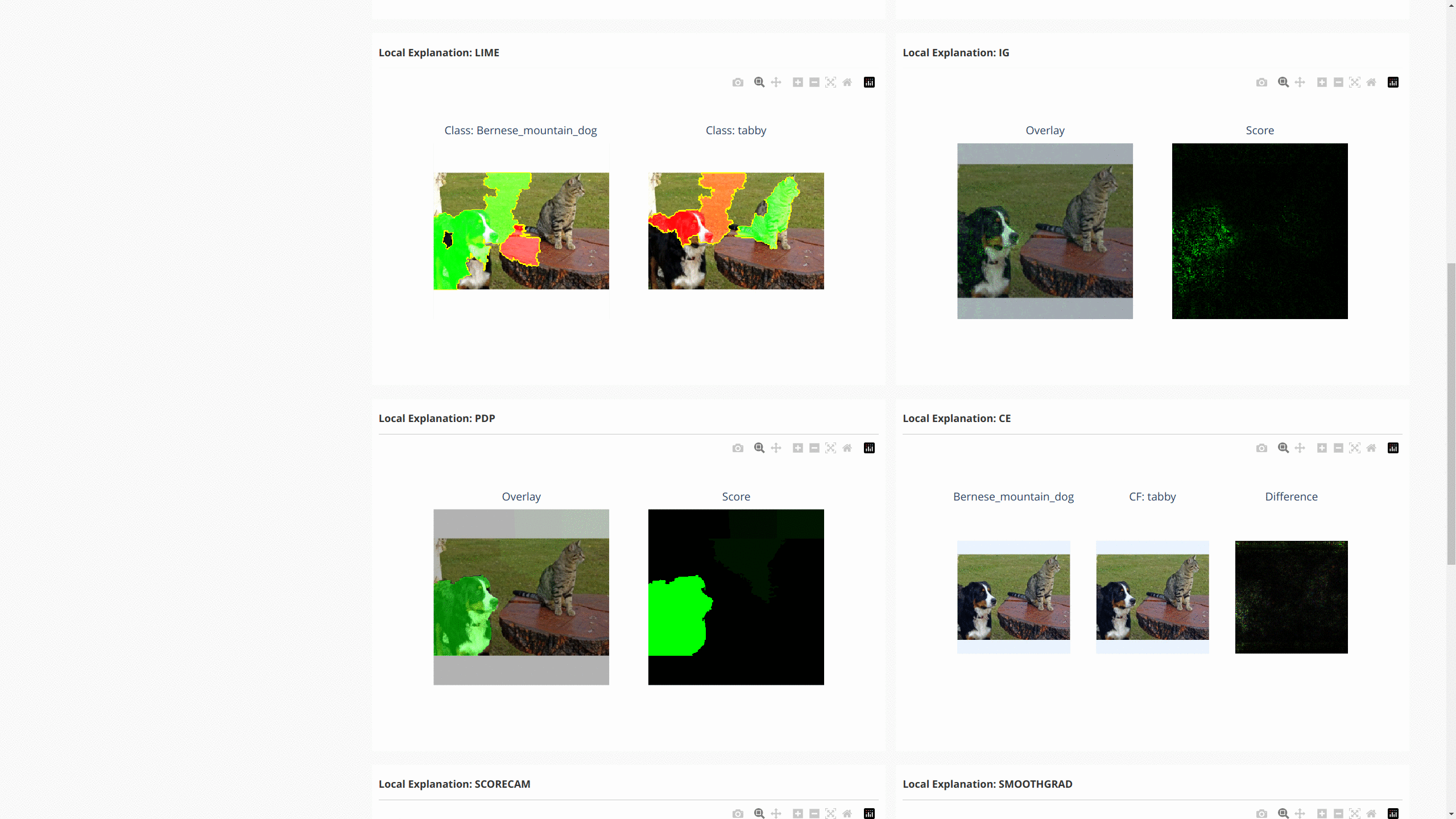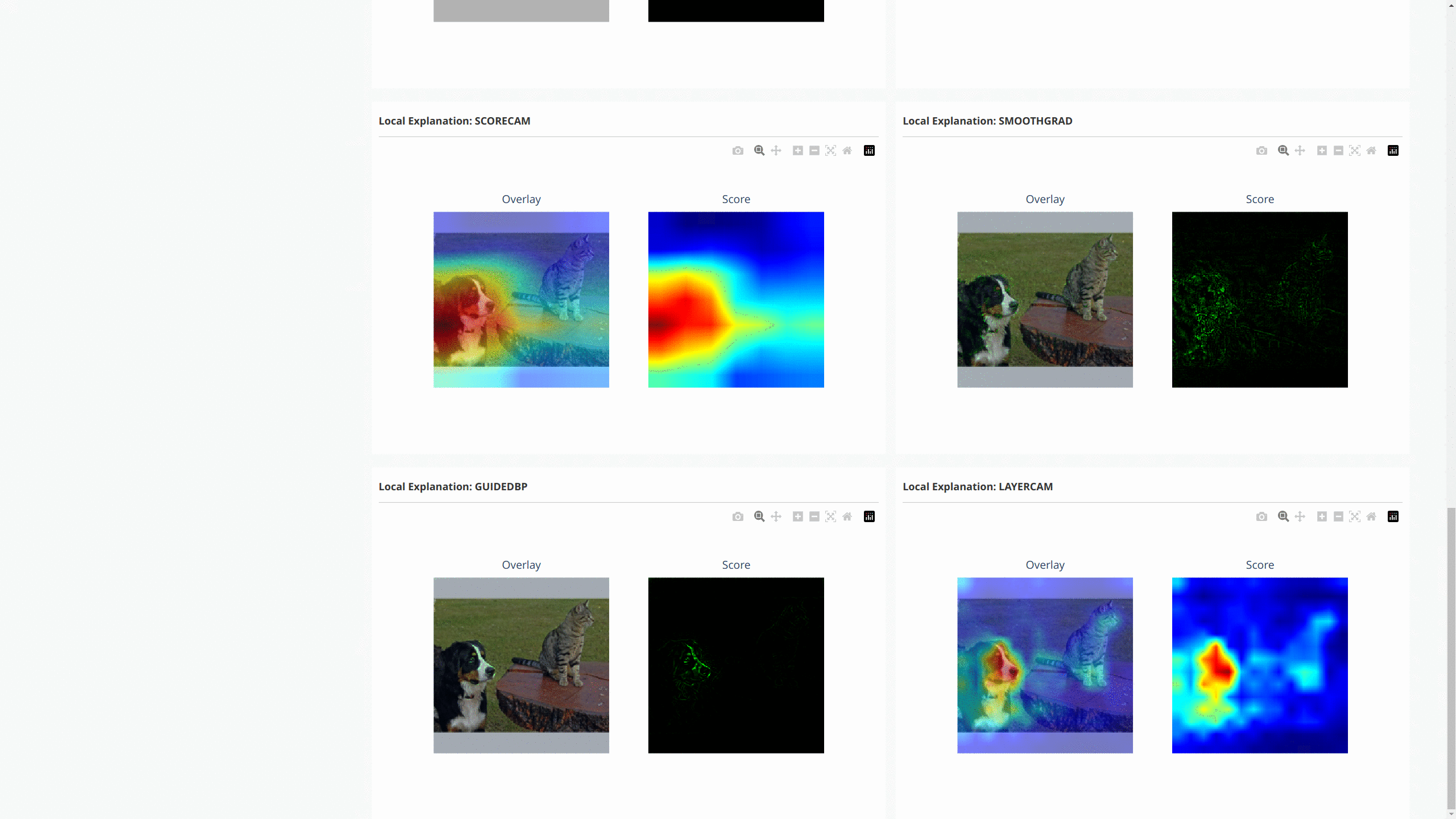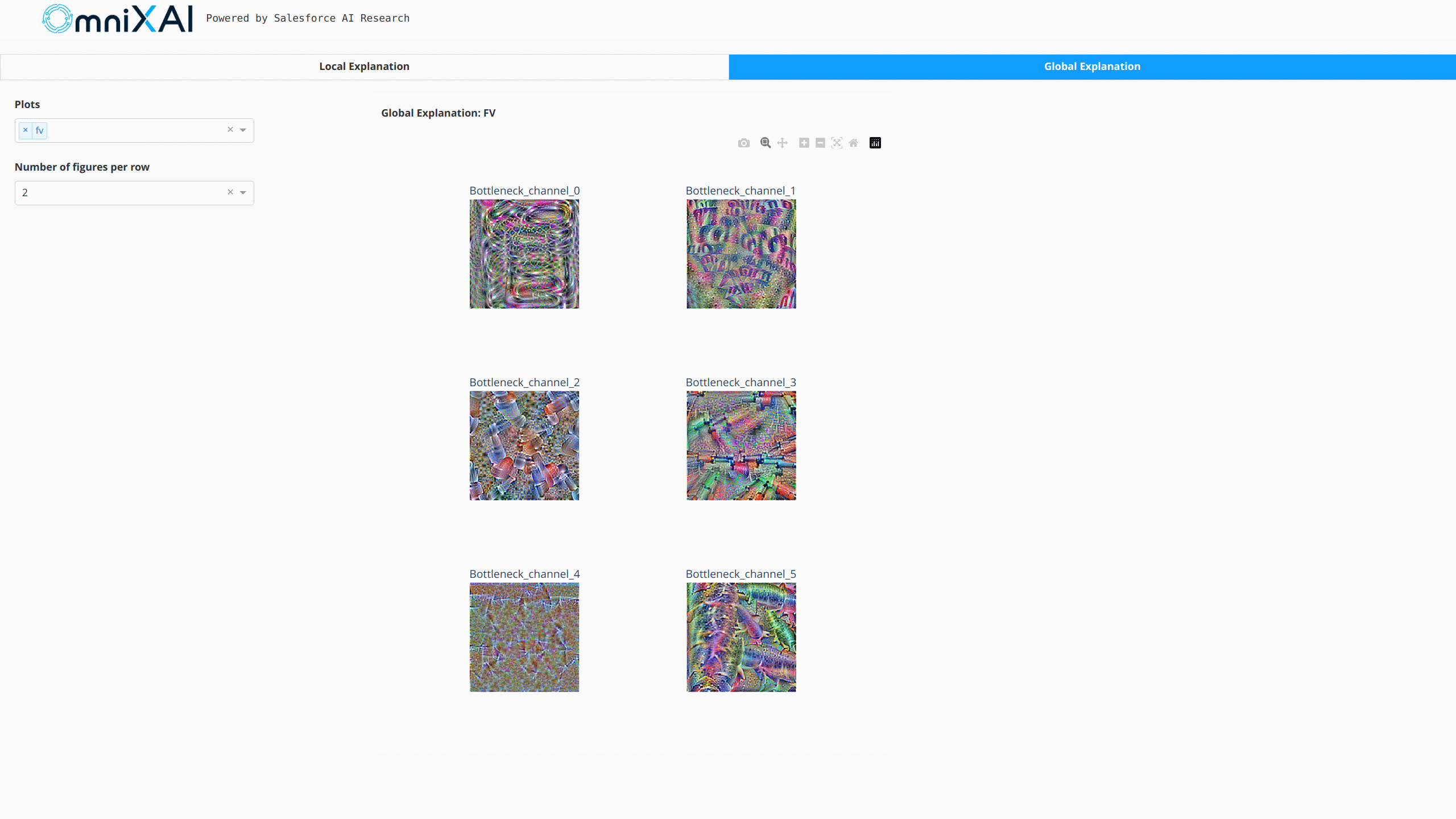
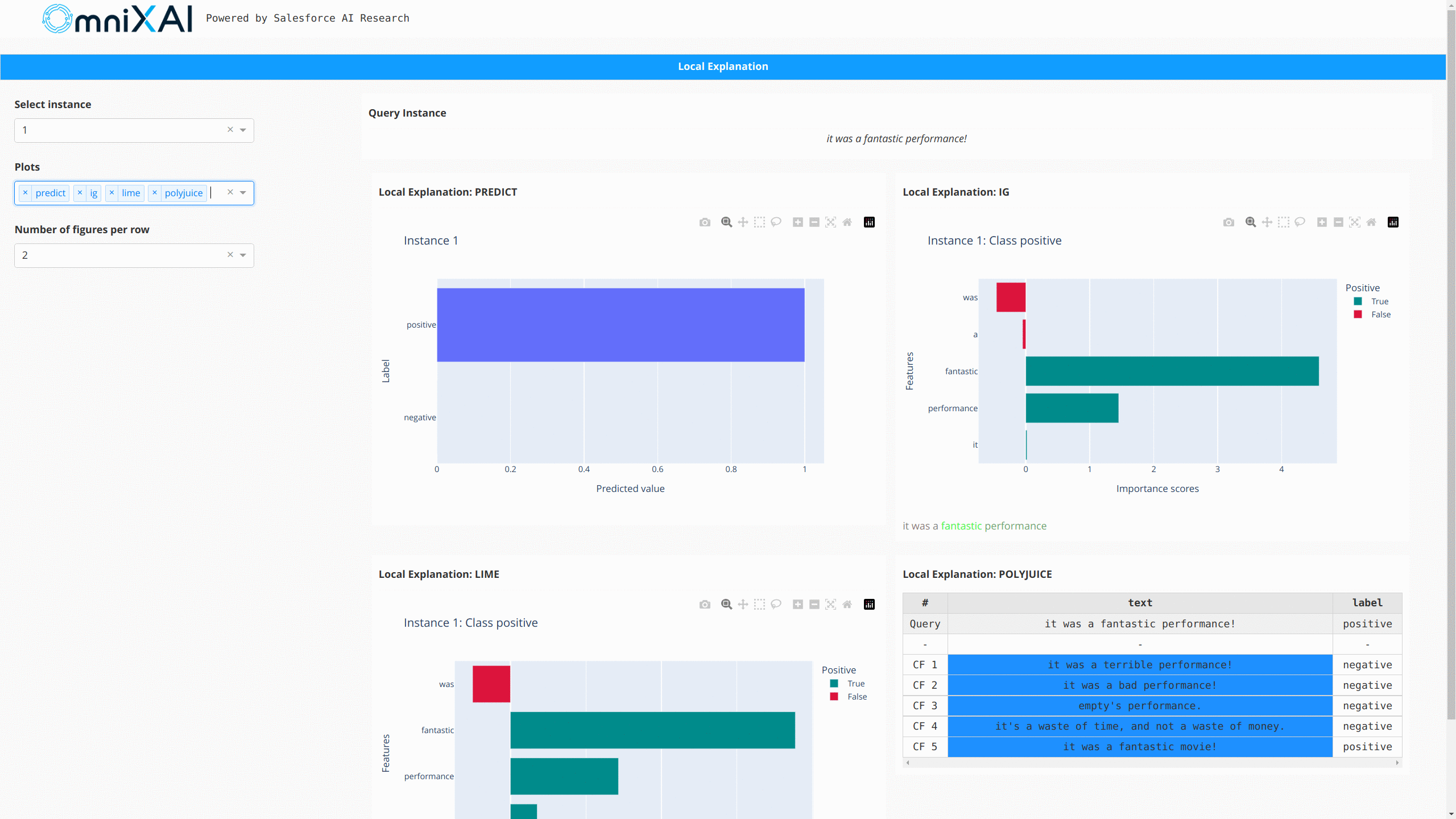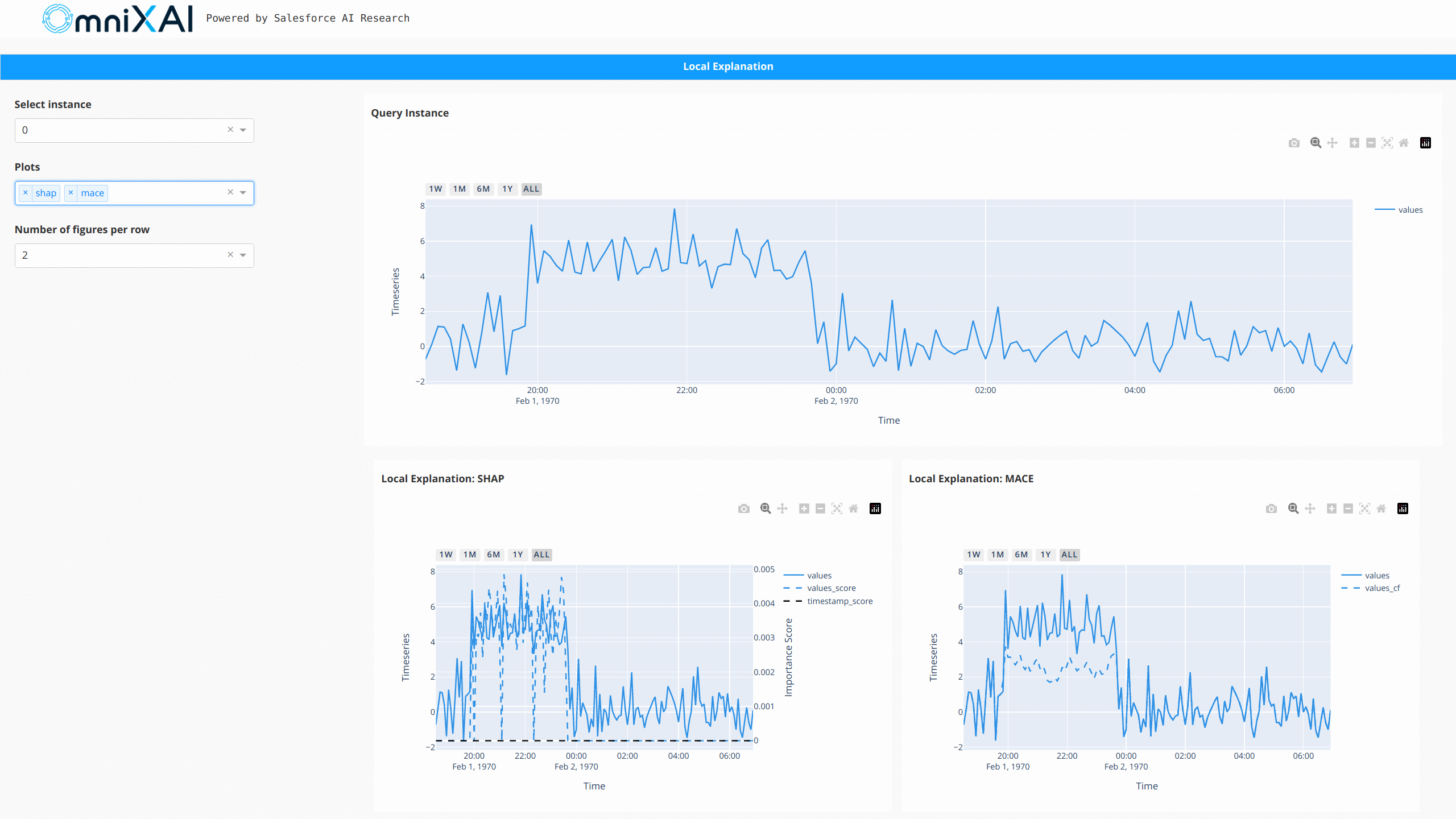
对于NLP任务和时间序列预测/异常检测,OmniXAI也提供了相同的接口来生成和可视化解释。这张图展示了文本分类和时间序列异常检测的仪表板示例:
部署
OmniXAI中的解释器可以通过BentoML轻松部署。BentoML是一个流行的开源统一模型服务框架,支持多个平台,包括AWS、GCP、Heroku等。我们为OmniXAI实现了BentoML格式的接口,使用户只需几行代码就能部署他们选择的解释器。
让我们以收入预测任务为例。给定训练好的模型和初始化的解释器,你只需将解释器保存在BentoML本地模型存储中:
from omnixai.explainers.tabular import TabularExplainer
from omnixai.deployment.bentoml.omnixai import save_model
explainer = TabularExplainer(
explainers=["lime", "shap", "mace", "pdp", "ale"],
mode="classification",
data=train_data,
model=model,
preprocess=lambda z: transformer.transform(z),
params={
"mace": {"ignored_features": ["Sex", "Race", "Relationship", "Capital Loss"]}
}
)
save_model("tabular_explainer", explainer)
然后为ML服务代码创建一个文件(例如service.py):
from omnixai.deployment.bentoml.omnixai import init_service
svc = init_service(
model_tag="tabular_explainer:latest",
task_type="tabular",
service_name="tabular_explainer"
)
init_service函数定义了两个API端点,即/predict用于模型预测,/explain用于生成解释。你可以在本地启动API服务器来测试上述服务代码:
bentoml serve service:svc --reload
可以在本地访问这些端点:
import requests
from requests_toolbelt.multipart.encoder import MultipartEncoder
data = '["39", "State-gov", "77516", "Bachelors", "13", "Never-married", ' \
'"Adm-clerical", "Not-in-family", "White", "Male", "2174", "0", "40", "United-States"]'
# 测试预测端点
prediction = requests.post(
"http://0.0.0.0:3000/predict",
headers={"content-type": "application/json"},
data=data
).text
# 测试解释端点
m = MultipartEncoder(
fields={
"data": data,
"params": '{"lime": {"y": [0]}}',
}
)
result = requests.post(
"http://0.0.0.0:3000/explain",
headers={"Content-Type": m.content_type},
data=m
).text
# 解析结果
from omnixai.explainers.base import AutoExplainerBase
exp = AutoExplainerBase.parse_explanations_from_json(result)
for name, explanation in exp.items():
explanation.ipython_plot()
你可以按照BentoML仓库中显示的步骤构建Bento进行部署。更多示例请查看表格数据、视觉、自然语言处理。
如何贡献
我们欢迎开源社区的贡献来改进这个库!
要将新的解释方法/功能添加到库中,请遵循此文档中演示的模板和步骤。
技术报告和引用OmniXAI
你可以在我们的技术报告中找到更多详细信息:https://arxiv.org/abs/2206.01612
如果你在研究或应用中使用OmniXAI,请使用以下BibTeX进行引用:
@article{wenzhuo2022-omnixai,
author = {Wenzhuo Yang and Hung Le and Silvio Savarese and Steven Hoi},
title = {OmniXAI: A Library for Explainable AI},
year = {2022},
doi = {10.48550/ARXIV.2206.01612},
url = {https://arxiv.org/abs/2206.01612},
archivePrefix = {arXiv},
eprint = {206.01612},
}
联系我们
如果你有任何问题、评论或建议,请随时通过omnixai@salesforce.com与我们联系。











