

开源持续机器学习平台
仅使用Python构建ML流水线,在笔记本电脑或云端运行。

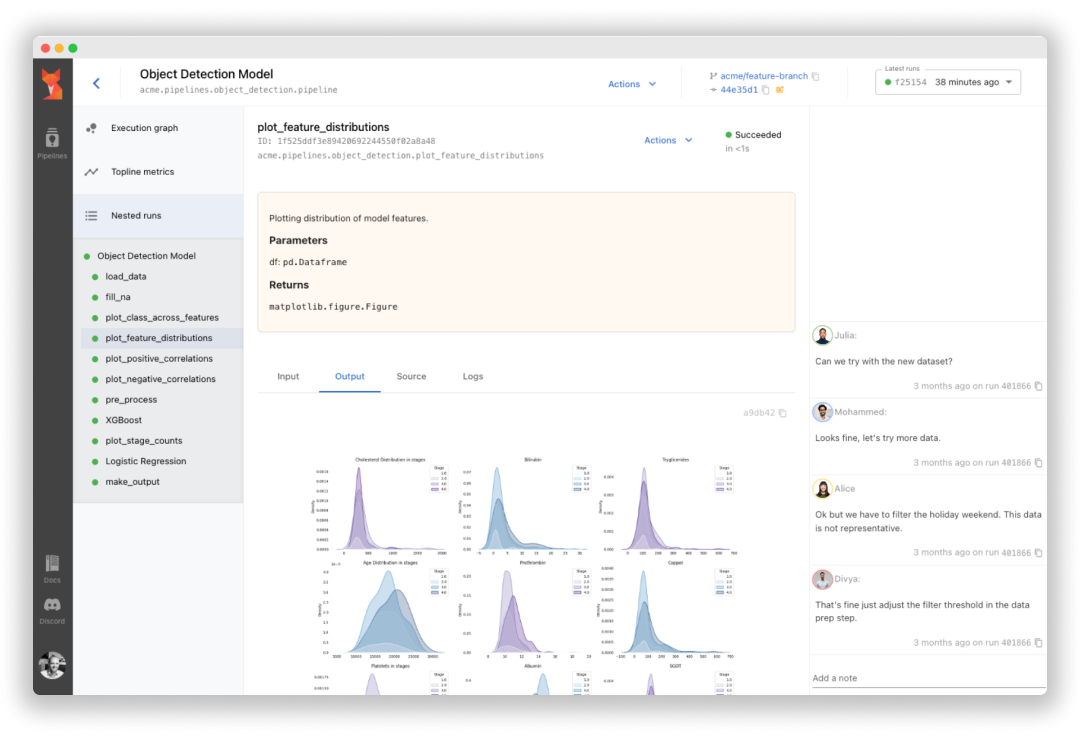
Sematic是一个开源的ML开发平台。它允许ML工程师和数据科学家使用简单的Python编写任意复杂的端到端流水线,并在本地机器、云端虚拟机或Kubernetes集群上执行,以利用云资源。
Sematic基于顶级自动驾驶汽车公司积累的经验。它能够将数据处理作业(如Apache Spark)与模型训练(如PyTorch、Tensorflow)或任何其他任意Python业务逻辑链接成类型安全、可追踪、可重现的端到端流水线,可在现代Web仪表板中进行监控和可视化。
为什么选择Sematic
- 轻松上手 – 无需部署或基础设施即可开始,只需在本地安装Sematic并开始探索。
- 本地到云端的一致性 – 在本地笔记本电脑和Kubernetes集群上运行相同的代码。
- 端到端可追溯性 – 所有流水线工件都被持久化、跟踪,并可在Web仪表板中可视化。
- 访问异构计算资源 – 为每个流水线步骤自定义所需资源,以优化性能和云端占用(CPU、内存、GPU、Spark集群等)。
- 可重现性 – 从UI重新运行流水线,保证结果的可重现性。
入门
要在本地开始使用,只需在Python环境中安装Sematic:
$ pip install sematic
启动本地Web仪表板:
$ sematic start
运行示例流水线:
$ sematic run examples/mnist/pytorch
创建新的样板项目:
$ sematic new my_new_project
或从现有示例创建:
$ sematic new my_new_project --from examples/mnist/pytorch
然后运行它:
$ python3 -m my_new_project
要将Sematic部署到Kubernetes并利用云资源,请参阅我们的文档。
功能
- 轻量级Python SDK – 定义任意复杂的端到端流水线
- 流水线嵌套 – 任意将流水线嵌套到更大的流水线中
- 动态图 – Python定义的图允许迭代、条件分支等
- 血缘跟踪 – 所有步骤的所有输入和输出都被持久化和跟踪
- 运行时类型检查 – 通过运行时类型检查及早失败
- Web仪表板 – 在现代Web UI中监控、跟踪和可视化流水线
- 工件可视化 – 在Web仪表板中可视化所有步骤的所有输入和输出
- 本地执行 – 无需任何部署即可在本地机器上运行流水线
- 云端编排 – 在Kubernetes上运行流水线以访问GPU和其他云资源
- 异构计算资源 – 在不同的机器上运行不同的步骤(如CPU、内存、GPU、Spark等)
- Helm chart部署 – 在Kubernetes集群上安装Sematic
- 流水线重新运行 – 从UI中从图的任意点重新运行流水线
- 步骤缓存 – 缓存昂贵的流水线步骤以加快迭代速度
- 步骤重试 – 通过步骤重试从暂时性故障中恢复
- 元数据和协作 – 标签、源代码可视化、文档字符串、笔记等
- 众多集成 – 见下文
集成
- Apache Spark – 按需集群内Spark集群
- Ray – 按需集群内Ray资源
- Snowflake – 轻松查询您的数据仓库(也支持其他数据仓库)
- Plotly, Matplotlib – 在Web仪表板中可视化绘图工件
- Pandas – 在仪表板中可视化数据框工件
- Grafana – 在Web仪表板中嵌入Grafana面板
- Bazel – 与您的Bazel构建系统集成
- Helm chart – 使用我们的Helm chart部署到Kubernetes
- Git – 在Web仪表板中跟踪git信息
社区和资源
通过以下资源了解更多关于Sematic的信息并与我们联系:
贡献!
要为Sematic做出贡献,请查看标记为"good first issue"的开放问题,并在Discord上与我们联系。 您可以在我们的开发者文档中找到如何设置开发环境的说明。如果您想添加示例,您可能还会发现这个指南很有帮助。












