
 访问官网
访问官网 Github
Github Huggingface
Huggingface 文档
文档 论文
论文Markdowner ⚡📝
一款快速将任何网站转换为LLM就绪的Markdown数据的工具。
👀 为什么?
我正在开发一款名为Supermemory的AI应用 - https://git.new/memory。用户可以在应用中存储网站内容,然后使用AI进行查询。我注意到一件事:当数据结构化且可预测(采用Markdown格式)时,LLM的响应会好得多。
虽然已有其他解决方案可用 - https://r.jina.ai, https://firecrawl.dev 等。但它们要么:
- 太贵/专有
- 功能有限
- 部署困难
以下是我朋友@nexxeln的一段话

所以,我们自然而然地要自己解决这个问题 ⚡
特性 🚀
- 将任何网站转换为Markdown
- LLM过滤
- 详细的Markdown模式
- 自动爬虫(无需站点地图!)
- 文本和JSON响应
- 易于自托管
- ... 所有这些功能,而且完全免费!
使用方法
要使用API,只需向https://md.dhr.wtf发送GET请求
使用示例:
$ curl 'https://md.dhr.wtf/?url=https://example.com'
必需参数
url(字符串) -> 要转换为Markdown的网站URL。
可选参数
enableDetailedResponse(布尔值:false) -> 切换详细响应,包含完整HTML内容。
crawlSubpages(布尔值:false) -> 爬取并返回最多10个子页面的Markdown。
llmFilter(布尔值:false) -> 使用LLM过滤掉不必要的信息。
响应类型
在请求头中添加Content-Type: text/plain以获取纯文本响应。
在请求头中添加Content-Type: application/json以获取JSON响应。
技术
在底层,Markdowner利用Cloudflare的浏览器渲染和持久对象来启动浏览器实例,然后使用Turndown将其转换为Markdown。
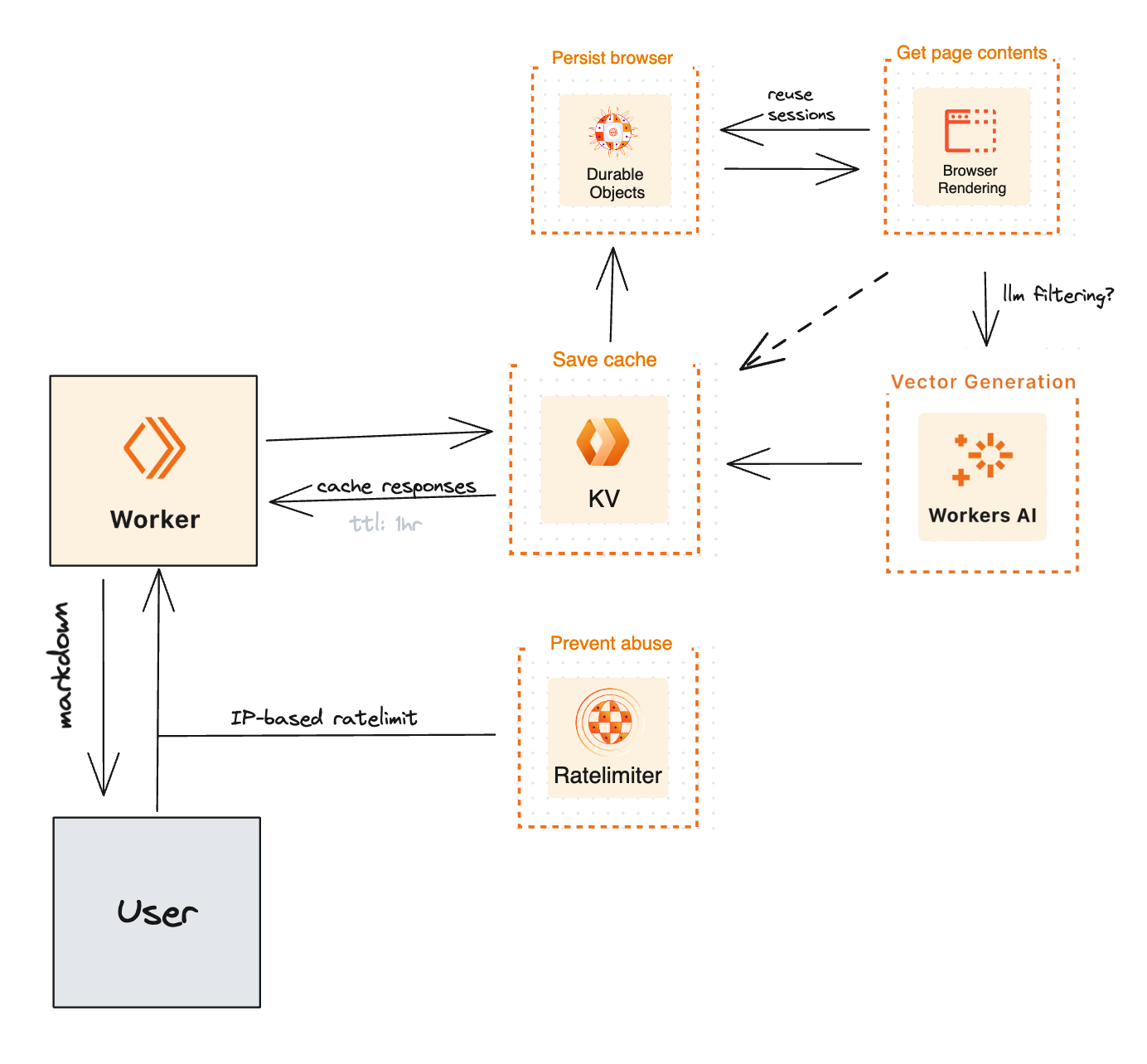
自托管
您可以轻松地自托管此项目。要使用浏览器渲染和持久对象,您需要Workers付费计划
- 克隆仓库并下载依赖
git clone https://github.com/dhravya/markdowner
npm i
- 运行此命令:
npx wrangler kv:namespace create md_cache - 打开Wrangler.toml并相应更改ID
- 运行
npm run deploy - 就这样 👍
支持
通过给这个仓库加星来支持我! ⭐











