
llama2.🔥
你有没有想过在纯粹的Mojo中推断一个baby Llama 2模型?没有?好吧,现在你可以了!
支持的版本:Mojo 24.3
随着Mojo 的发布,我受启发将我的Python移植版
llama2.py转移到Mojo。结果?一个利用
Mojo的SIMD和矢量化原语的版本,将Python性能提升了近250倍。
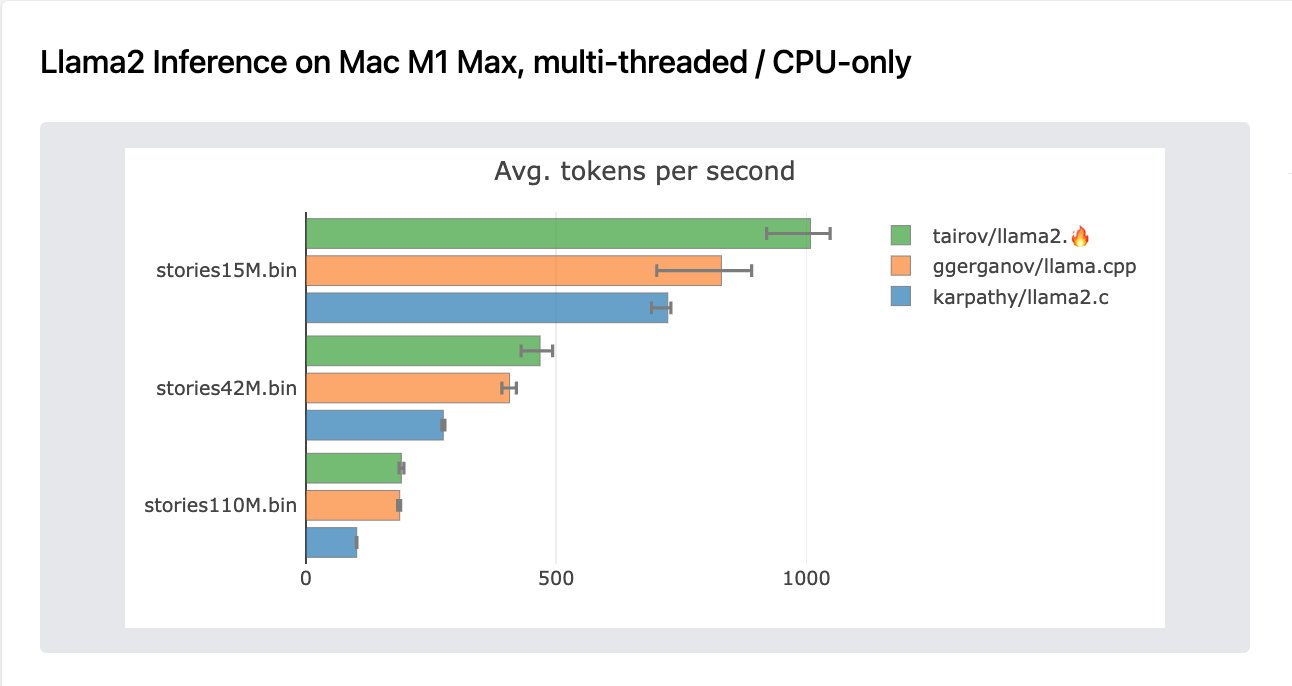
令人印象深刻的是,在经过少量原生改进后,Mojo版本在多线程推理中比原始llama2.c高出30%。此外,它在CPU上的baby-llama推理方面,比llama.cpp高出20%。
这展示了通过Mojo的高级功能进行硬件级优化的潜力。
支持的模型
目前,通过llama2.mojo成功执行的模型有:
| 模型 |
|---|
| stories 260K, 15M, 42M, 110M |
| Tinyllama-1.1B-Chat-v0.2 |
在Apple M1 Max上的广泛基准测试
基准测试(更新)
Mac M1 Max(6线程)
| 模型 | llama2.c (OMP/并行化版) | llama2.mojo (并行化版) | llama.cpp (CPU, 6线程) | llama2.py |
|---|---|---|---|---|
| stories15M.bin | 730 tok/s | 1025 tok/s | 890 tok/s | 38 tok/s (pypi) |
| stories42M.bin | 270 tok/s | 490 tok/s | 420 tok/s | - |
| stories110M.bin | 102 tok/s | 195 tok/s | 187 tok/s | - |
| TinyLlama-1.1B | - | 23 tok/s | - | - |
Ubuntu 20.04, Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz, 6核, 12线程
| 模型 | llama2.c (OMP/并行化版) | llama2.mojo (并行化版) | llama2.mojo (naive matmul) | llama2.py |
|---|---|---|---|---|
| stories15M.bin | 435 tok/s | 440 tok/s | 67.26 tok/s | 1.3 tok/s |
| stories110M.bin | 64 tok/s | 63 tok/s | 9.20 tok/s | - |
| TinyLlama-1.1B | 7.25 tok/s | 7.25 tok/s | - | - |
先决条件
确保你已经安装并配置了你的环境中的mojo
或者你可以使用mojo playground来运行此模型。
试一试🔥魔法
HuggingFace - https://huggingface.co/spaces/radames/Gradio-llama2.mojo
感受🔥魔法
首先,导航到存放项目的文件夹,并将此存储库克隆到该文件夹:
git clone https://github.com/tairov/llama2.mojo.git
然后,打开存储库文件夹:
cd llama2.mojo
现在,让我们下载模型
wget https://huggingface.co/karpathy/tinyllamas/resolve/main/stories15M.bin
然后,只需运行Mojo
mojo llama2.mojo stories15M.bin -s 100 -n 256 -t 0.5 -i "Mojo is a language"
示例输出
num hardware threads: 6
SIMD vector width: 16
checkpoint size: 60816028 [ 57 MB ]
n layers: 6
vocab size: 32000
Mojo is a language that people like to talk. Hephones are very different from other people. He has a big book with many pictures and words. He likes to look at the pictures and learn new things.
One day, Mojo was playing with his friends in the park. They were running and laughing and having fun. Mojo told them about his book and his friends. They listened and looked at the pictures. Then, they saw a picture of a big, scary monster. They were very scared and ran away.
Mojo was sad that his book was gone. He told his friends about the monster and they all felt very sad. Mojo's friends tried to make him feel better, but nothing worked. Mojo never learned his language again.
achieved tok/s: 440.21739130434781
通过Docker运行
docker build --build-arg AUTH_KEY=<your-modular-auth-key> -t llama2.mojo .
docker run -it llama2.mojo
使用Gradio界面:
# 取消注释dockerfile中的最后一行 CMD ["python", "gradio_app.py"]
docker run -it -p 0.0.0.0:7860:7860 llama2.mojo
引用llama2.🔥
如果你在学术研究中使用或讨论llama2.mojo,请引用该项目以帮助传播:
@misc{llama2.mojo,
author = {Aydyn Tairov},
title = {Inference Llama2 in one file of pure Mojo},
year = {2023},
month = {09},
howpublished = {\url{https://github.com/tairov/llama2.mojo}},
note = {Llama2 Mojo, MIT License}
}
我们恳请你在已发表的论文中包含指向GitHub存储库的链接。这将使感兴趣的读者能够轻松找到该项目的最新更新和扩展。
llama2.mojo旨在鼓励对transformer架构、llama模型以及mojo编程语言应用的高效实现的学术研究。引用该项目有助于知识社区在这些主题周围增长。我们感谢你通过提及llama2.mojo给予的支持!
玩玩Tinyllama-1.1B-Chat-v0.2
TinyLlama 是一个1.1B的Llama模型,训练用的token达3万亿。 其紧凑性使其能够满足多种需要有限计算和内存占用的应用。 这也是我们选择它作为第一个支持的模型的原因。
首先,导航到保存你项目的文件夹,并克隆此存储库到该文件夹:
git clone https://github.com/tairov/llama2.mojo.git
然后,打开存储库文件夹:
cd llama2.mojo
现在,让我们下载模型和tokenizer
wget https://huggingface.co/kirp/TinyLlama-1.1B-Chat-v0.2-bin/resolve/main/tok_tl-chat.bin
wget https://huggingface.co/kirp/TinyLlama-1.1B-Chat-v0.2-bin/resolve/main/tl-chat.bin
然后,只需运行Mojo
mojo llama2.mojo tl-chat.bin \
-z tok_tl-chat.bin \
-n 256 -t 0 -s 100 -i "











