
 访问官网
访问官网 Github
Github 文档
文档 论文
论文腾讯王者荣耀AI开放环境
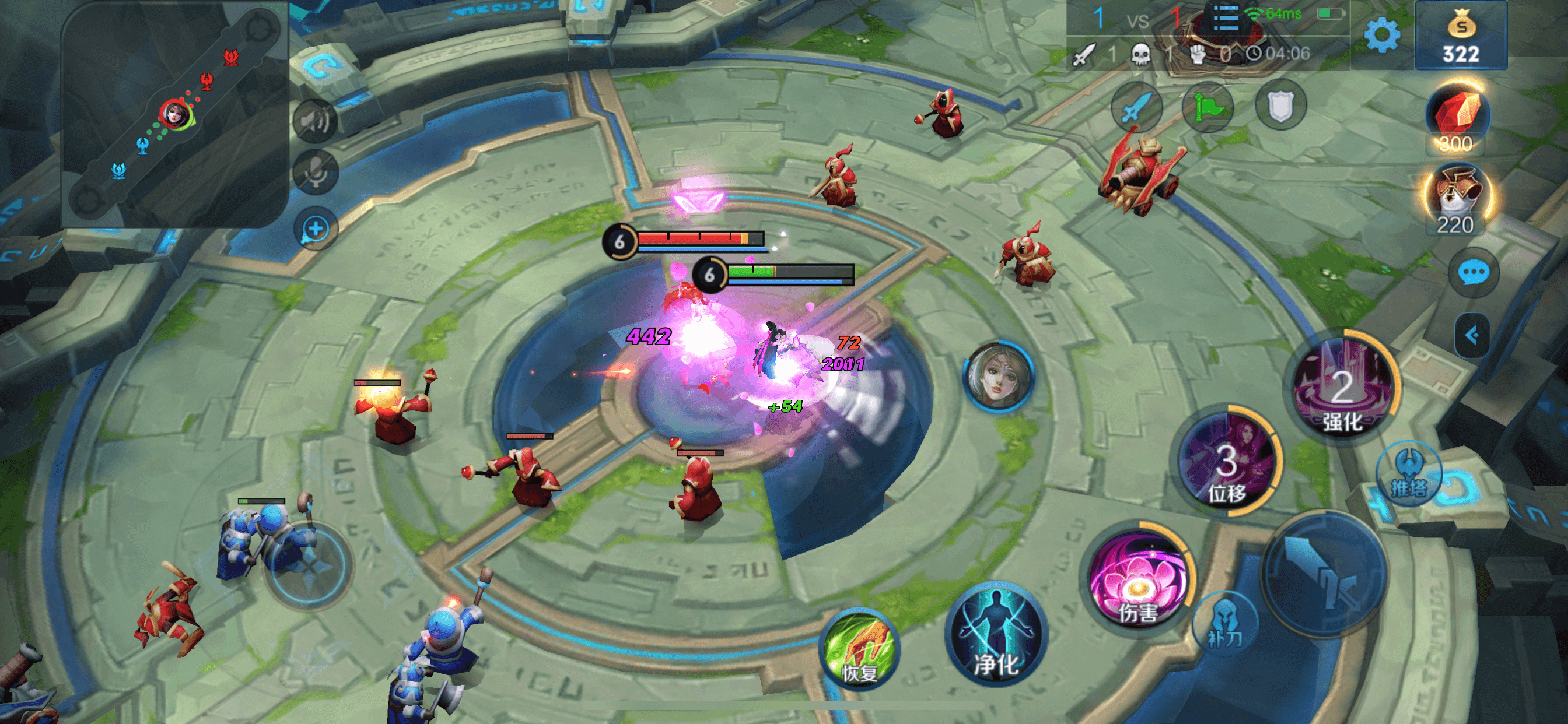
更新:3v3模式现已可用
python3.8 -c "from hok.hok3v3.unit_test.test_env import run_test; run_test()"
更多信息请参考hok3v3。
关于使用hok_env环境和集成的rl_framework进行集群训练的说明,请参阅cluster.md文档。
简介


-
本仓库主要包括Hok_env SDK、一个强化学习训练框架以及基于该训练框架的PPO算法实现。Hok_env SDK用于与王者荣耀的游戏核心进行交互。
-
本仓库还包含以下论文的实现代码:
王者荣耀竞技场:一个用于竞争性强化学习泛化的环境
Hua Wei*, Jingxiao Chen*, Xiyang Ji*, Hongyang Qin, Minwen Deng, Siqin Li, Liang Wang, Weinan Zhang, Yong Yu, Lin Liu, Lanxiao Huang, Deheng Ye, Qiang Fu, Wei Yang. (*Equal contribution)
NeurIPS数据集与基准2022
项目页面:https://github.com/tencent-ailab/hok_env
arXiv:https://arxiv.org/abs/2209.08483摘要:本文介绍了王者荣耀竞技场,这是一个基于当前世界上最受欢迎游戏之一的王者荣耀的强化学习(RL)环境。与之前大多数研究中的其他环境相比,我们的环境为竞争性强化学习带来了新的泛化挑战。它是一个多智能体问题,一个智能体与对手竞争;它需要泛化能力,因为有多样化的控制目标和多样化的竞争对手。我们描述了王者荣耀领域的观察、动作和奖励规范,并提供了一个开源的基于Python的接口用于与游戏引擎通信。我们在王者荣耀竞技场中提供了二十个目标英雄,涵盖各种任务,并展示了基于RL方法使用可行计算资源的初步基线结果。最后,我们展示了王者荣耀竞技场带来的泛化挑战以及应对这些挑战的可能方法。所有软件(包括环境类)都可以在以下网址公开获取:https://github.com/tencent-ailab/hok_env。文档可在以下网址获取:https://aiarena.tencent.com/hok/doc/。
-
hok_env当前支持的英雄:
- 鲁班七号
- 米莱狄
- 李白
- 马可波罗
- 狄仁杰
- 关羽
- 貂蝉
- 露娜
- 韩信
- 花木兰
- 不知火舞
- 橘右京
- 后羿
- 钟馗
- 干将莫邪
- 凯
- 公孙离
- 裴擒虎
- 上官婉儿
运行要求
-
Python >= 3.6, <= 3.9
-
Windows 10/11或Linux wine(用于部署Windows游戏核心服务器)
-
Docker(用于在Linux容器上部署hok_env)
- 对于Windows,需要WSL 2(Windows Subsystem for Linux Version 2.0)
hok_env的游戏核心在Windows平台上运行,而hok_env包需要部署在Linux平台上与游戏核心交互。
我们还提供了一个Docker镜像,方便您在计算机上进行训练。在未来的版本中,我们将发布一个与Linux兼容的游戏核心服务器。
要启用集群训练,这里有一个在Linux上运行Windows游戏核心的解决方法:在Linux上运行Windows游戏核心。
游戏核心安装
下载王者荣耀游戏核心
您需要在此页面申请许可证和游戏核心:https://aiarena.tencent.com/aiarena/en/open-gamecore
请将license.dat文件放在以下文件夹中:hok_env_gamecore/gamecore/core_assets。
测试游戏核心
打开CMD
cd gamecore\bin
set PATH=%PATH%;..\lib\
.\sgame_simulator_remote_zmq.exe .\sgame_simulator.common.conf
sgame_simulator_remote_zmq.exe需要一个参数:sgame_simulator.common.conf配置文件路径
你可以看到以下消息:
PlayerNum:2
AbsPath:../scene/1V1.abs
PlayerInfo [CampID:0][HeroID:199][Skill:80104][AutoAi:1][AiServer::0:100] [Symbol 0 0 0] [Request:-1]
PlayerInfo [CampID:1][HeroID:199][Skill:80104][AutoAi:1][AiServer::0:100] [Symbol 0 0 0] [Request:-1]
SGame模拟器开始
init_ret:0
种子: 3417
符号:
inHeroId: 199
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
inHeroId: 199
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
start_ret:0
英雄[0] inHeroId:199; outPlayerId:148
英雄[1] inHeroId:199; outPlayerId:149
[英雄信息] [英雄ID:199] [运行时ID:8] client_id:0.0.0.0_1658_0_20221202193534_148
[英雄信息] [英雄ID:199] [运行时ID:9] client_id:0.0.0.0_1658_0_20221202193534_149
boost_ret 完成: 8, gameover_ai_server: 0
close_ret:0
uninit_ret:0
SGame模拟器结束 [帧数:8612][用时:7580毫秒]
游戏核心已成功启动!
以下是sgame_simulator.common.conf的内容:
{
"abs_file": "../scene/1V1.abs",
"core_assets": "../core_assets",
"game_id": "kaiwu-base-35401-35400-6842-1669963820108111766-217",
"hero_conf": [
{
"hero_id": 199
},
{
"hero_id": 199
}
]
}
输出文件:
AIOSS_221202-1935_linux_1450111_1450123_1_1_20001_kaiwu-base-35401-35400-6842-1669963820108111766-217.abs
kaiwu-base-35401-35400-6842-1669963820108111766-217.json
kaiwu-base-35401-35400-6842-1669963820108111766-217.stat
kaiwu-base-35401-35400-6842-1669963820108111766-217_detail.stat
1对1
观察空间和动作空间
请参考 https://aiarena.tencent.com/hok/doc/quickstart/index.html
使用方法
请参考 hok1v1/unit_test 了解hok1v1的基本用法。
请参考 aiarena/1v1 了解hok1v1的训练代码。
在WSL中使用演示脚本测试游戏核心
你可以在wsl中使用一个简单的Python脚本来测试游戏核心。
确保你的电脑支持wsl2
关于wsl2的安装和升级,请参考以下链接:https://docs.microsoft.com/zh-cn/windows/wsl/install-manual#step-4---download-the-linux-kernel-update-package
你需要在wsl中安装python3.6和一些必要的依赖。
在wsl2中运行测试脚本
-
在wsl2外启动游戏核心服务器
cd gamecore gamecore-server.exe server --server-address :23432 -
在Python中安装hok_env
## git克隆此仓库后 cd hok_env/hok_env pip install -e . -
运行测试脚本
cd /hok_env/hok/hok1v1/unit_test python test_env.py
如果你看到以下消息,说明你已成功与Hok_env建立连接并完成了一局游戏。恭喜你!
# python test_env.py
127.0.0.1:23432 127.0.0.1
======= test_send_action
camp_config {'mode': '1v1', 'heroes': [[{'hero_id': 132}], [{'hero_id': 133}]]}
common_ai [False, True]
尝试获取第一个状态...
第一个状态: dict_keys(['observation', 'legal_action', 'reward', 'done', 'model_output_name', 'game_id', 'player_id', 'frame_no', 'sub_action_mask', 'req_pb', 'sgame_id'])
第一帧: 0
----------------------运行步骤 0
----------------------运行步骤 100
----------------------运行步骤 200
----------------------运行步骤 300
----------------------运行步骤 400
----------------------运行步骤 500
----------------------运行步骤 600
----------------------运行步骤 700
----------------------运行步骤 800
----------------------运行步骤 900
----------------------运行步骤 1000
----------------------运行步骤 1100
2023-08-23 13:13:57.782 | INFO | hok.common.log:info:85 - 游戏尚未结束,首先发送关闭游戏:当前帧号(3525)
[{
"player_id": 8,
"frame_no": 30,
"observation": array([1.00000000e00, 1.00000000e00, 0.00000000e00, 0.00000000e00, ...]),
"reward": (0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0),
"legal_action": array([1.0, 1.0, 1.0, 0.0, 0.0, ...]),
"sub_action_mask": {
0: array([1.0, 0.0, 0.0, 0.0, 0.0, 0.0]),
1: array([1.0, 0.0, 0.0, 0.0, 0.0, 0.0]),
...
11: array([1.0, 0.0, 0.0, 0.0, 0.0, 0.0]),
},
"req_pb": hok.hok1v1.lib.interface.AIFrameState,
}, ...]
修改1v1游戏配置
在运行游戏环境之前,你需要在运行路径下创建config.json文件。
示例:
{
"reward_money": "0.006",
"reward_exp": "0.006" ,
"reward_hp_point": "2.0",
"reward_ep_rate": "0.75",
"reward_kill": "-0.6",
"reward_dead": "-1.0",
"reward_tower_hp_point": "5.0",
"reward_last_hit": "0.5",
"log_level": "4"
}
此配置文件包含子奖励因子和protobuf处理部分的日志级别。
该文件仅在创建HoK1v1实例时加载,即使你调用HoK1v1.reset,任何修改也不会重新加载。
在大多数情况下,log_level应设置为4以避免无用的日志信息。
只有在使用我们的环境遇到错误时,log_level可能需要设置较低的值,以帮助我们获取更多关于你遇到的错误的信息。
3v3
观察和动作空间
更多信息请参考hok3v3。
使用方法
假设你已经在127.0.0.1:23432启动了游戏核心服务器,并且运行hok_env的IP是127.0.0.1。
以下是hok3v3环境的基本用法:
-
获取环境实例:
GC_SERVER_ADDR = os.getenv("GAMECORE_SERVER_ADDR", "127.0.0.1:23432") AI_SERVER_ADDR = os.getenv("AI_SERVER_ADDR", "127.0.0.1") reward_config = RewardConfig.default_reward_config.copy() env = get_hok3v3(GC_SERVER_ADDR, AI_SERVER_ADDR, reward_config) -
重置环境并开始新游戏
use_common_ai = [True, False] camp_config = { "mode": "3v3", "heroes": [ [{"hero_id": 190}, {"hero_id": 173}, {"hero_id": 117}], [{"hero_id": 141}, {"hero_id": 111}, {"hero_id": 107}], ], } env.reset(use_common_ai, camp_config, eval_mode=True) -
游戏循环和预测
gameover = False while not gameover: for i, is_comon_ai in enumerate(use_common_ai): if is_comon_ai: continue continue_process, features, frame_state = env.step_feature(i) gameover = frame_state.gameover # 每3帧预测一次 if not continue_process: continue probs = random_predict(features, frame_state) ok, results = env.step_action(i, probs, features, frame_state) if not ok: raise Exception("步骤动作失败") env.close_game(force=True)
你可以通过以下方式获取默认奖励配置:
reward_config = RewardConfig.default_reward_config.copy()
以下是奖励配置示例:
reward_config = {
"whether_use_zero_sum_reward": 1,
"team_spirit": 0,
"time_scaling_discount": 1,
"time_scaling_time": 4500,
"reward_policy": {
"hero_0": {
"hp_rate_sqrt_sqrt": 1,
"money": 0.001,
"exp": 0.001,
"tower": 1,
"killCnt": 1,
"deadCnt": -1,
"assistCnt": 1,
"total_hurt_to_hero": 0.1,
"atk_monster": 0.1,
"win_crystal": 1,
"atk_crystal": 1,
},
},
"policy_heroes": {
"hero_0": [169, 112, 174],
},
}
你可以通过 HERO_DICT 获取英雄名称对应的 hero_id:
from hok.common.camp import HERO_DICT
print(HERO_DICT)
完整的上述代码请参考 hok3v3/test_env。
你可以通过以下脚本运行测试代码:
python3.8 -c "from hok.hok3v3.unit_test.test_env import run_test; run_test()"
如果运行正常,你将看到以下信息:
2023-12-28 12:54:28.106 | INFO | hok.hok3v3.unit_test.test_env:get_hok3v3:14 - Init libprocessor: /usr/local/lib/python3.8/dist-packages/hok/hok3v3/config.dat
2023-12-28 12:54:28.106 | INFO | hok.hok3v3.unit_test.test_env:get_hok3v3:15 - Init reward: {'whether_use_zero_sum_reward': 1, 'team_spirit': 0.2, 'time_scaling_discount': 1, 'time_scaling_time': 4500, 'reward_policy': {'policy_name_0': {'hp_rate_sqrt': 1, 'money': 0.001, 'exp': 0.001, 'tower': 1, 'killCnt': 1, 'deadCnt': -1, 'assistCnt': 1, 'total_hurt_to_hero': 0.1, 'ep_rate': 0.1, 'win_crystal': 1}}, 'hero_policy': {1: 'policy_name_0'}, 'policy_heroes': {'policy_name_0': [1, 2]}}
2023-12-28 12:54:28.107 | INFO | hok.hok3v3.unit_test.test_env:get_hok3v3:16 - Init gamecore environment: 127.0.0.1:23432 127.0.0.1
2023-12-28 12:54:28.107 | INFO | hok.hok3v3.reward:update_reward_config:116 - Update reward config: time_scaling_time:4500, time_scaling_discount:1, team_spirit:0.2, whether_use_zero_sum_reward:1
2023-12-28 12:54:28.107 | INFO | hok.hok3v3.reward:update_reward_config:124 - Update hero reward config: 1 -> {'hp_rate_sqrt': 1, 'money': 0.001, 'exp': 0.001, 'tower': 1, 'killCnt': 1, 'deadCnt': -1, 'assistCnt': 1, 'total_hurt_to_hero': 0.1, 'ep_rate': 0.1, 'win_crystal': 1}
2023-12-28 12:54:28.107 | INFO | hok.hok3v3.reward:update_reward_config:124 - Update hero reward config: 2 -> {'hp_rate_sqrt': 1, 'money': 0.001, 'exp': 0.001, 'tower': 1, 'killCnt': 1, 'deadCnt': -1, 'assistCnt': 1, 'total_hurt_to_hero': 0.1, 'ep_rate': 0.1, 'win_crystal': 1}
2023-12-28 12:54:28.136 | INFO | hok.hok3v3.server:start:31 - Start server at tcp://0.0.0.0:35151
2023-12-28 12:54:28.139 | INFO | hok.hok3v3.env:reset:85 - Reset info: agent:0 is_common_ai:True
2023-12-28 12:54:28.139 | INFO | hok.hok3v3.env:reset:85 - Reset info: agent:1 is_common_ai:False
2023-12-28 12:54:30.212 | INFO | hok.hok3v3.unit_test.test_env:run_test:78 - ----------------------run step 0
2023-12-28 12:54:30.673 | INFO | hok.hok3v3.unit_test.test_env:run_test:78 - ----------------------run step 100
2023-12-28 12:54:30.945 | INFO | hok.hok3v3.unit_test.test_env:run_test:78 - ----------------------run step 200
集群训练
请参考 cluster.md 文档,了解如何使用 hok_env 环境和集成的 rl_framework 进行集群训练。
回放软件:ABS 解析工具(将与游戏核心一起提供)
观看游戏是直观了解代理在整场比赛中表现的方法。我们提供了一个回放工具来可视化比赛。
这是一个官方回放软件,它解析游戏核心生成的 ABS 文件,并在王者荣耀的游戏界面中输出视频。
游戏核心生成的 ABS 文件可以在游戏核心文件夹下找到。
你可以将 ABS 文件放在 Replays 文件夹下,然后运行 ABSTOOL.exe 来可视化比赛。

预构建镜像
https://hub.docker.com/r/tencentailab/hok_env
从 PyPI 安装
pip install hok
引用
如果你使用了 hok_env 的游戏核心或本仓库中的代码,请按以下方式引用我们的论文:
@inproceedings{wei2022hok_env,
title={Honor of Kings Arena: an Environment for Generalization in Competitive Reinforcement Learning},
author={Wei, Hua and Chen, Jingxiao and Ji, Xiyang and Qin, Hongyang and Deng, Minwen and Li, Siqin and Wang, Liang and Zhang, Weinan and Yu, Yong and Liu, Lin and Huang, Lanxiao and Ye, Deheng and Fu, Qiang and Yang, Wei},
booktitle={Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks},
year={2022}
}











