
 访问官网
访问官网 Github
Github 文档
文档Indexify

示例 | Indexify 提取器 | Python 客户端 | TypeScript 客户端
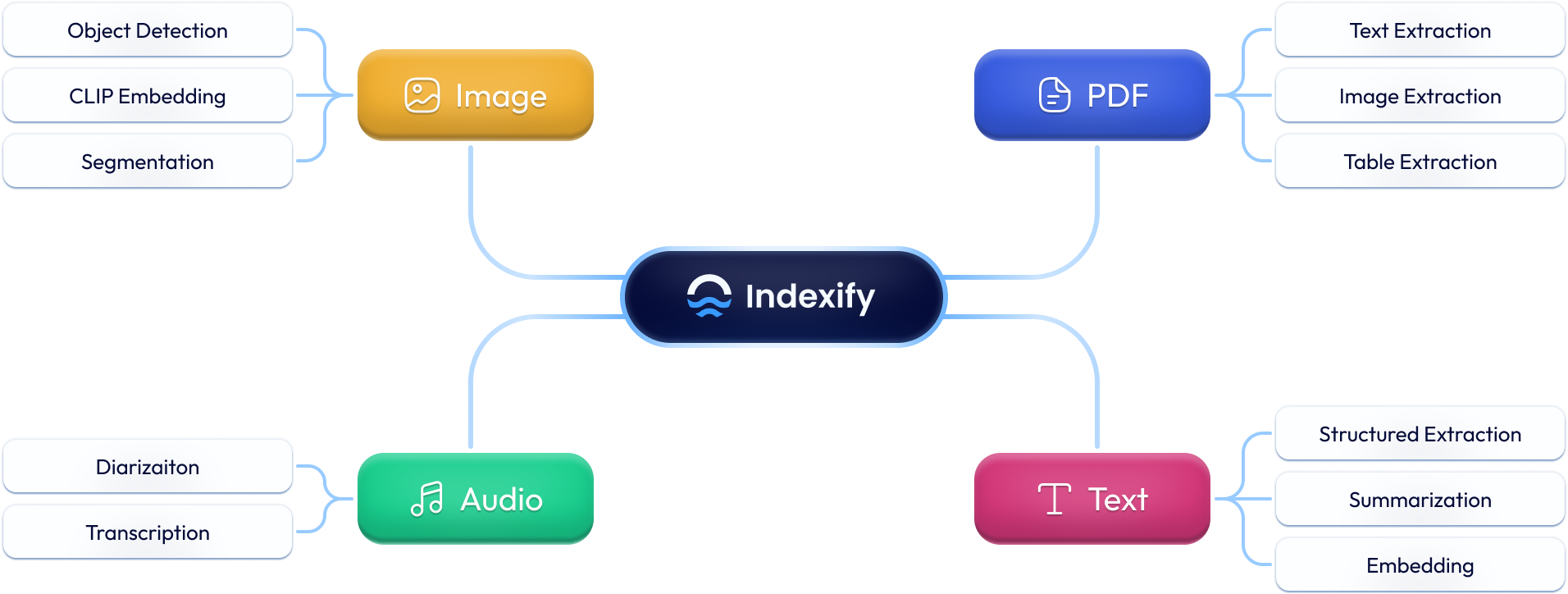
基于 Indexify 的 LLM 应用程序永远不会回答过时的信息。
Indexify 是一个开源引擎,用于构建快速的非结构化数据(视频、音频、图像和文档)处理管道,使用可重用的提取器进行嵌入、转换和特征提取。当管道生成嵌入或结构化数据时,Indexify 会自动更新向量数据库和结构化数据库(Postgres)。
应用程序可以使用语义搜索和 SQL 查询来查询索引和数据库。
与批处理/ETL 系统的区别
基于 ETL 的摄取系统以批处理方式处理文件,适用于数据更新不频繁的离线用例。相比之下,Indexify 的管道作为实时 API 运行,像任何在线系统一样,在摄取时立即处理文件或文本。Indexify 可以高效地在数千台机器上调度数据处理任务,为需要最新索引的 RAG 应用程序或代理提供实时提取功能。
更多酷炫功能!
- 内容更新时进行增量提取。当文档、视频或音频更新时,Indexify 只处理变更的部分。
- 提取器 SDK 允许在管道中插入任何自定义模型或 API。
- 许多预构建的提取器用于嵌入和处理 PDF、图像和视频。
- 适用于任何 LLM 框架。内置支持 Langchain、DSPy 等。
- 无需任何外部依赖即可在本地运行,便于原型设计。
- 支持多种Blob 存储、向量存储和结构化数据库。
- 自动化部署到生产环境的 Kubernetes。
详细入门指南
请按照我们的文档开始使用。
快速入门
下载并启动 Indexify | 终端1
curl https://getindexify.ai | sh
./indexify server -d
安装 Indexify 提取器和客户端 SDK | 终端2
virtualenv ve
source ve/bin/activate
pip install indexify indexify-extractor-sdk requests
下载一些提取器 | 终端2
indexify-extractor download tensorlake/minilm-l6
indexify-extractor download tensorlake/pdfextractor
indexify-extractor download tensorlake/yolo-extractor
indexify-extractor download tensorlake/chunk-extractor
indexify-extractor download tensorlake/summarization
indexify-extractor download tensorlake/whisper-asr
indexify-extractor join-server
文本嵌入管道
这个例子展示了如何在文本上实现 RAG
创建提取图
from indexify import IndexifyClient, ExtractionGraph
client = IndexifyClient()
extraction_graph_spec = """
name: 'sportsknowledgebase'
extraction_policies:
- extractor: 'tensorlake/minilm-l6'
name: 'minilml6'
"""
extraction_graph = ExtractionGraph.from_yaml(extraction_graph_spec)
client.create_extraction_graph(extraction_graph)
print("indexes", client.indexes())
添加文本
content_ids = client.add_documents("sportsknowledgebase", ["Adam Silver 是 NBA 总裁", "Roger Goodell 是 NFL 总裁"])
检索
client.wait_for_extraction(content_ids)
context = client.search_index(name="sportsknowledgebase.minilml6.embedding", query="NBA 总裁", top_k=1)
wait_for_extraction 方法会阻塞客户端,直到 Indexify 完成对摄入内容的提取。在生产应用中,您很可能不会阻塞应用程序,而是让提取异步进行。
PDF 提取和检索
这个例子展示了如何创建一个从 PDF 文档提取的管道。 更多信息请参见 - https://docs.getindexify.ai/usecases/pdf_extraction/
创建提取图
from indexify import IndexifyClient, ExtractionGraph
import requests
client = IndexifyClient()
extraction_graph_spec = """
name: 'pdfqa'
extraction_policies:
- extractor: 'tensorlake/pdfextractor'
name: 'docextractor'
"""
extraction_graph = ExtractionGraph.from_yaml(extraction_graph_spec)
client.create_extraction_graph(extraction_graph)
上传文档
with open("sample.pdf", 'wb') as file:
file.write((requests.get("https://extractor-files.diptanu-6d5.workers.dev/scientific-paper-example.pdf")).content)
content_id = client.upload_file("pdfqa", "sample.pdf")
获取文本、图像和表格
client.wait_for_extraction(content_id)
print(client.get_extracted_content(content_id, "pdfqa", "docextractor"))
音频转录和摘要
此示例展示如何转录音频,并创建一个嵌入转录内容的流程 更多关于音频用例的详情 - https://docs.getindexify.ai/usecases/audio_extraction/
创建提取图
from indexify import IndexifyClient, ExtractionGraph
import requests
client = IndexifyClient()
extraction_graph_spec = """
name: 'audiosummary'
extraction_policies:
- extractor: 'tensorlake/whisper-asr'
name: 'transcription'
- extractor: 'tensorlake/summarization'
name: 'summarizer'
input_params:
max_length: 400
min_length: 300
chunk_method: str = 'recursive'
content_source: 'transcription'
- extractor: 'tensorlake/minilm-l6'
name: 'minilml6'
content_source: 'summarizer'
"""
extraction_graph = ExtractionGraph.from_yaml(extraction_graph_spec)
client.create_extraction_graph(extraction_graph)
上传音频
with open("sample.mp3", 'wb') as file:
file.write((requests.get("https://extractor-files.diptanu-6d5.workers.dev/sample-000009.mp3")).content)
content_id = client.upload_file("audiosummary", "sample.mp3")
添加文本和文件可能是一个耗时的过程,默认情况下我们允许异步摄取以进行并行操作。但是,在提取完成之前,以下代码可能会失败。要使其成为阻塞调用,请在获取上述content_id后使用
client.wait_for_extraction(content_id)。
获取摘要
client.wait_for_extraction(content_id)
print("transcription ----")
print(client.get_extracted_content(content_id, "audiosummary", "transcription"))
print("summary ----")
print(client.get_extracted_content(content_id, "audiosummary", "summarizer"))
搜索转录索引
context = client.search_index(name="audiosummary.minilml6.embedding", query="President of America", top_k=1)
图像对象检测
此示例展示如何创建一个使用Yolo提取器对图像进行对象检测的流程。 更多关于图像理解和检索的详情 - https://docs.getindexify.ai/usecases/image_retrieval/
创建提取图
from indexify import IndexifyClient, ExtractionGraph
import requests
client = IndexifyClient()
extraction_graph_spec = """
name: 'imageknowledgebase'
extraction_policies:
- extractor: 'tensorlake/yolo-extractor'
name: 'object_detection'
"""
extraction_graph = ExtractionGraph.from_yaml(extraction_graph_spec)
client.create_extraction_graph(extraction_graph)
上传图像
with open("sample.jpg", 'wb') as file:
file.write((requests.get("https://extractor-files.diptanu-6d5.workers.dev/people-standing.jpg")).content)
content_id = client.upload_file("imageknowledgebase", "sample.jpg")
获取图像特征
client.wait_for_extraction(content_id)
client.get_extracted_content(content_id, "imageknowledgebase", "object_detection")
Yolo提取器将检测到的图像中的对象添加到数据库中。表名与提取图名称相同
使用SQL查询
print(client.sql_query("select * from imageknowledgebase where object_name='person';"))
LLM框架集成
Indexify可以与任何LLM框架或直接与您的应用程序一起工作。我们有一个Langchain应用示例在这里和DSPy在这里。
尝试其他提取器
我们还有很多其他提取器,您可以列出并尝试它们 -
indexify-extractor list
自定义提取器
任何提取或转换算法都可以表示为Indexify提取器。我们提供了一个SDK来编写您自己的提取器。请按照这里的文档获取说明。
结构化数据
从内容中生成结构化数据的提取器,如边界框和对象类型,或发票的行项目,都存储在结构化存储中。您可以使用Indexify的SQL接口查询提取的结构化数据。
我们有一个示例在这里
贡献
请开一个issue来讨论新功能,或加入我们的Discord群组。欢迎贡献,我们有一些开放的任务需要帮助!
如果您想为Rust代码库做出贡献,请阅读开发者自述文件。











