
 访问官网
访问官网 Github
Github Huggingface
Huggingface 文档
文档pgvectorscale
pgvectorscale基于pgvector构建,为AI应用提供更高性能的嵌入式搜索和成本效益更高的存储。
pgvectorscale是对pgvector(PostgreSQL的开源向量数据扩展)的补充,为pgvector数据引入了以下关键创新:
- 一种名为StreamingDiskANN的新索引类型,灵感来自微软研究的DiskANN算法。
- 统计二进制量化:由Timescale研究人员开发,这种压缩方法改进了标准二进制量化。
在一个包含5000万个768维Cohere嵌入的基准数据集上,使用pgvector和pgvectorscale的PostgreSQL在99%召回率的近似最近邻查询中,相比Pinecone的存储优化(s1)索引,实现了95%百分位延迟降低28倍和查询吞吐量提高16倍,同时在AWS EC2上自托管时成本降低75%。
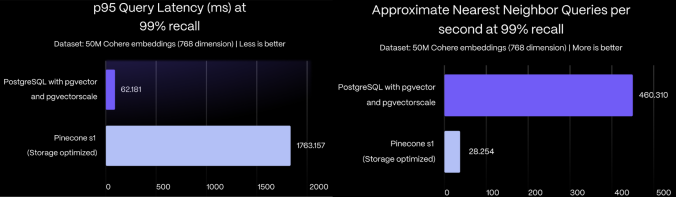
要了解更多关于pgvectorscale的性能影响,以及基准测试方法和结果的详细信息,请参阅pgvector vs Pinecone比较博客文章。
与用C语言编写的pgvector不同,pgvectorscale使用Rust和PGRX框架开发,为PostgreSQL社区提供了一种新的向量支持贡献途径。
应用程序开发人员或数据库管理员可以在其PostgreSQL数据库中使用pgvectorscale。
如果您想要贡献到这个扩展,请参阅如何在开发环境中从源代码构建pgvectorscale。
对于生产向量工作负载,在Timescale上获取带有pgvector和pgvectorscale的向量优化数据库的私有测试版访问权限。在此注册以获得优先访问权。
安装
运行带有pgvectorscale的PostgreSQL的最快方法是:
使用预构建的Docker容器
-
连接到您的数据库:
psql -d "postgres://<用户名>:<密码>@<主机>:<端口>/<数据库名>" -
创建pgvectorscale扩展:
CREATE EXTENSION IF NOT EXISTS vectorscale CASCADE;CASCADE会自动安装pgvector。
从源代码安装
您可以从源代码安装pgvectorscale并将其安装在现有的PostgreSQL服务器中
-
编译并安装扩展
# 安装先决条件 ## rust curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh ## pgrx cargo install --locked cargo-pgrx cargo pgrx init --pg16 pg_config # 下载、构建和安装pgvectorscale cd /tmp git clone --branch <版本> https://github.com/timescale/pgvectorscale cd pgvectorscale/pgvectorscale cargo pgrx install --release您也可以查看我们的扩展开发者文档以获取更完整的说明。
-
连接到您的数据库:
psql -d "postgres://<用户名>:<密码>@<主机>:<端口>/<数据库名>" -
确保pgvector扩展可用:
SELECT * FROM pg_available_extensions WHERE name = 'vector';如果pgvector不可用,请使用pgvector安装说明进行安装。
-
创建pgvectorscale扩展:
CREATE EXTENSION IF NOT EXISTS vectorscale CASCADE;CASCADE会自动安装pgvector。
在Timescale Cloud服务中启用pgvectorscale
注意:以下说明适用于Timescale的标准计算实例。对于生产向量工作负载,我们正在提供带有pgvector和pgvectorscale的向量优化数据库的私有测试版访问权限。在此注册以获得优先访问权。
要启用pgvectorscale:
-
创建一个新的Timescale服务。
如果您想使用现有服务,pgvectorscale会在pgvectorscale发布日期后的第一个维护窗口中作为可用扩展添加。
-
连接到您的Timescale服务:
psql -d "postgres://<用户名>:<密码>@<主机>:<端口>/<数据库名>" -
创建pgvectorscale扩展:
CREATE EXTENSION IF NOT EXISTS vectorscale CASCADE;CASCADE会自动安装pgvector。
开始使用pgvectorscale
-
创建一个带有嵌入列的表。例如:
CREATE TABLE IF NOT EXISTS document_embedding ( id BIGINT PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY, metadata JSONB, contents TEXT, embedding VECTOR(1536) ) -
填充表格。 有关更多信息,请参阅pgvector说明和客户端列表。
-
在嵌入列上创建StreamingDiskANN索引:
CREATE INDEX document_embedding_idx ON document_embedding USING diskann (embedding); -
使用索引查找10个最接近的嵌入。
SELECT * FROM document_embedding ORDER BY embedding <=> $1 LIMIT 10注意:pgvectorscale目前支持余弦距离(
<=>)查询。如果您需要其他距离类型,请创建一个问题。
调优
StreamingDiskANN索引具有智能默认值,同时也可以自定义其行为。有两种类型的参数:索引构建时参数(创建索引时指定)和查询时参数(可在查询索引时调整)。
我们建议为索引操作的重大更改设置索引构建时参数,而查询时参数可用于调整单个查询的准确性/性能权衡。
我们预计大多数人会调整查询时参数(如果有的话),而保持索引构建时参数为默认设置。
StreamingDiskANN索引构建时参数
这些参数可以在创建索引时设置。
| 参数名称 | 描述 | 默认值 |
|---|---|---|
storage_layout | memory_optimized使用SBQ压缩向量数据,或plain存储未压缩数据 | memory_optimized |
num_neighbors | 设置每个节点的最大邻居数。较高的值会提高准确性,但会使图遍历变慢。 | 50 |
search_list_size | 这是构建过程中贪婪搜索算法使用的S参数。较高的值可以提高图质量,但会降低索引构建速度。 | 100 |
max_alpha | 算法中的alpha参数。较高的值可以提高图质量,但会降低索引构建速度。 | 1.2 |
num_dimensions | 要索引的维度数。默认情况下,所有维度都被索引。但您也可以索引更少的维度以利用套娃嵌入 | 0(所有维度) |
num_bits_per_dimension | 使用SBQ时用于编码每个维度的位数 | 小于900维时为2,否则为1 |
以下是如何设置num_neighbors参数的示例:
CREATE INDEX document_embedding_idx ON document_embedding
USING diskann (embedding) WITH(num_neighbors=50);
StreamingDiskANN查询时参数
您还可以在查询时设置两个参数来控制准确性与查询速度的权衡。我们建议调整diskann.query_rescore来微调准确性。
| 参数名称 | 描述 | 默认值 |
|---|---|---|
diskann.query_search_list_size | 图搜索过程中考虑的额外候选项数量。 | 100 |
diskann.query_rescore | 重新评分的元素数量(0表示禁用重新评分) | 50 |
您可以在执行查询之前使用SET来设置值。例如:
SET diskann.query_rescore = 400;
注意,SET命令从执行点开始适用于整个会话(数据库连接)。您可以使用LOCAL变体来设置事务本地值,该值将在事务结束后重置:
BEGIN;
SET LOCAL diskann.query_search_list_size= 10;
SELECT * FROM document_embedding ORDER BY embedding <=> $1 LIMIT 10
COMMIT;
参与其中
pgvectorscale仍处于早期阶段。现在是帮助塑造这个项目方向的好时机;我们目前正在决定优先事项。看看我们正在考虑的功能列表。欢迎评论、扩展列表或加入讨论论坛。
关于Timescale
Timescale是一家PostgreSQL云公司。要了解更多信息,请访问timescale.com。
Timescale Cloud是一个高性能、面向开发人员的云平台,为最苛刻的AI、时间序列、分析和事件工作负载提供PostgreSQL服务。Timescale Cloud非常适合生产应用程序,提供高可用性、流式备份、随时间升级、角色和权限以及出色的安全性。











