

自我对弈微调 (SPIN)
本仓库包含论文“自我对弈微调将弱语言模型转换为强语言模型”的官方代码。
[网页] [Huggingface]
🔔 新闻
- [2024年5月1日] SPIN已被ICML2024接受!
- [2024年4月6日] 我们发布了训练脚本以重现我们的结果。
- [2024年4月4日] ❗ 我们发现之前上传的数据集不正确,已经重新上传了修正的数据集。
- [2024年2月13日] 我们更新了arXiv v2:https://arxiv.org/abs/2401.01335。
- [2024年2月9日] 代码已开源!
- [2024年1月2日] 论文已在arXiv发布:https://arxiv.org/abs/2401.01335。
❗ 注意:我们注意到Alignment Handbook在我们的实验后更新了配置和SFT检查点。我们在数据生成和微调实验中使用的Alignment Handbook配置和SFT模型是旧版本(配置,模型)。Hugging Face上的模型检查点(alignment-handbook/zephyr-7b-sft-full)已使用新配置更新一次。如果您希望使用最新的SFT模型,需要使用revision=ac6e600eefcce74f5e8bae1035d4f66019e93190加载检查点或自行生成数据,而不是使用我们在Hugging Face上提供的数据集(datasets)。
目录
🌀 关于SPIN
SPIN利用了一种自我对弈机制,使得LLM在无需额外的人类标注优选数据的情况下,通过与其之前的迭代版本进行对弈来提升自身性能。更具体地说,LLM从其先前迭代版本生成自己的训练数据,通过从原始SFT数据中辨别这些自生成的响应来优化其策略。
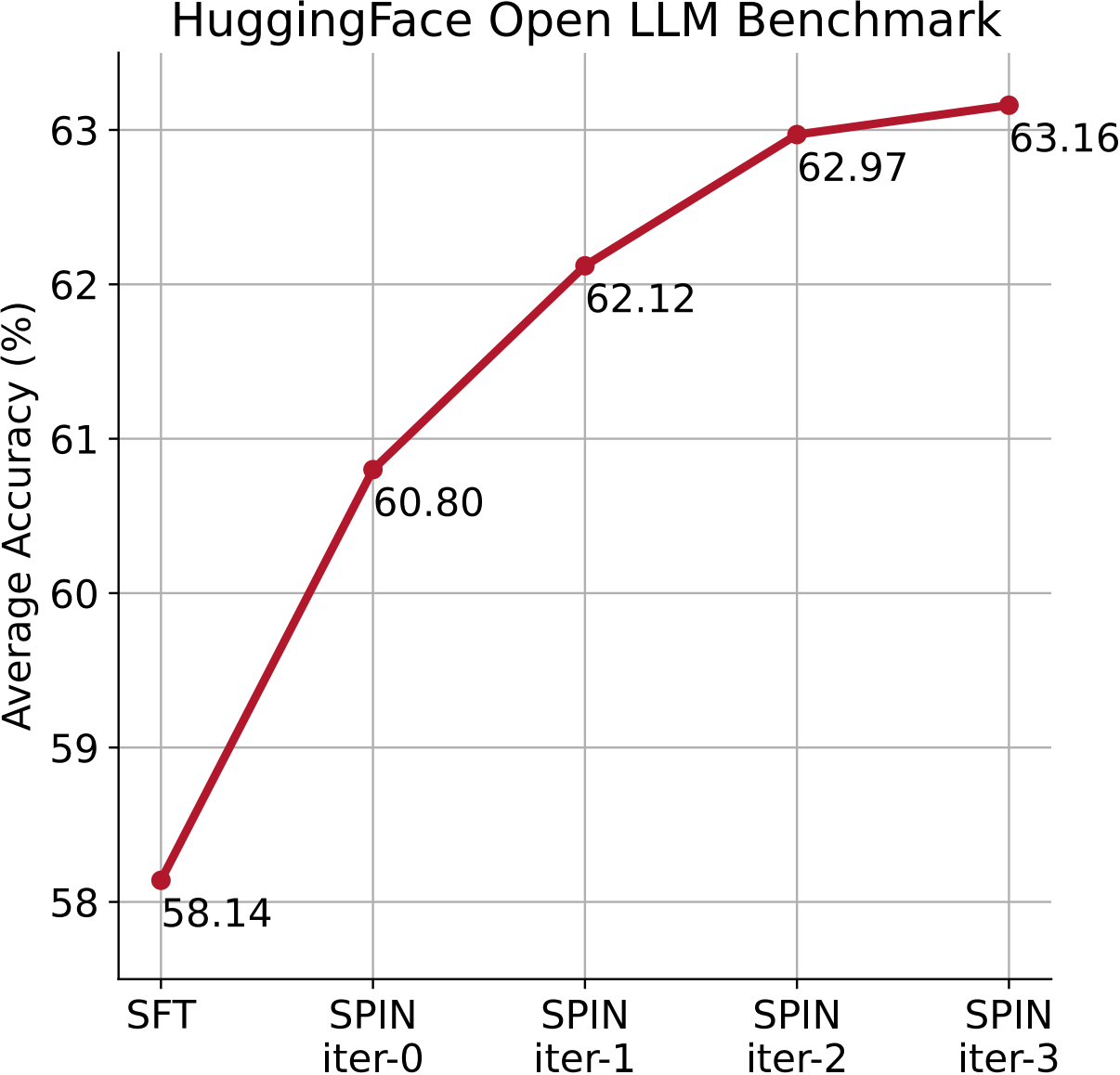
SPIN在不同迭代中在HuggingFace开放LLM排行榜上的平均分。
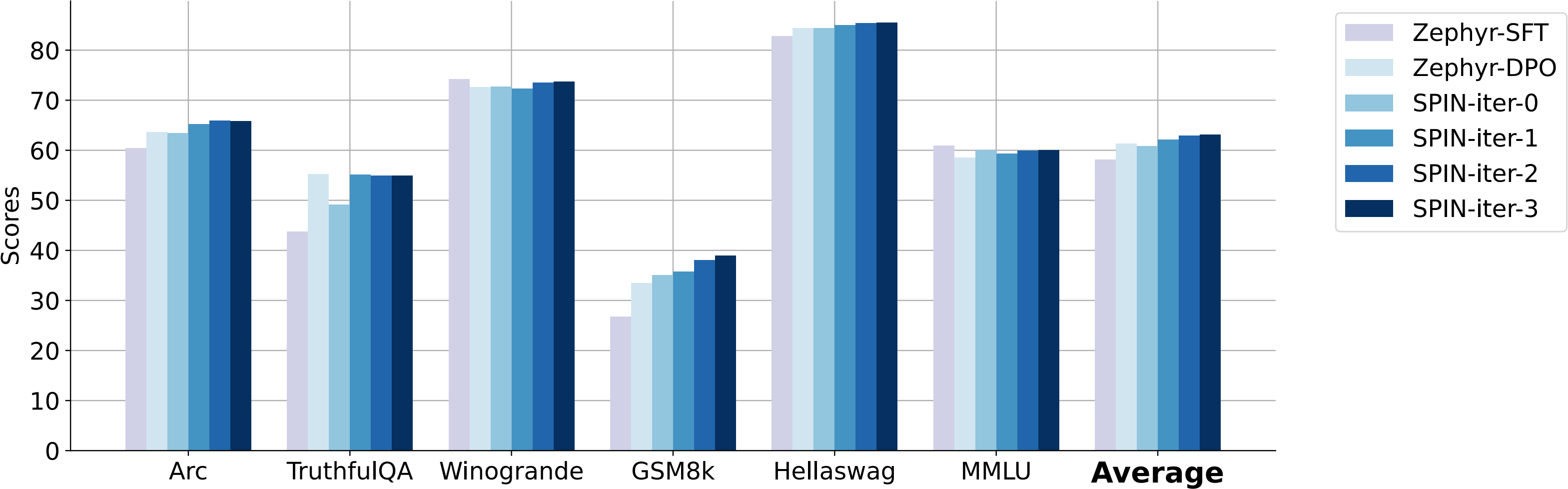
在六个基准数据集上与DPO训练的性能比较。在迭代0时,SPIN实现了与DPO训练使用62k新数据时相当的性能。在迭代1时,SPIN已经在大多数数据集中超越了DPO训练。
了解更多细节,请点击我们的论文这里。
设置
以下步骤提供了运行我们代码所需的设置。
- 使用Conda创建Python虚拟环境:
conda create -n myenv python=3.10
conda activate myenv
- 安装运行代码所需的Python依赖。
python -m pip install .
python -m pip install flash-attn --no-build-isolation
- 登录您的Huggingface账户以下载模型
huggingface-cli login --token "${your_access_token}"
数据
我们在此仓库和HuggingFace上提供了实验中使用的数据以及我们生成的合成数据。这些数据已转换为.parquet格式用于微调。
❗ 自2024年4月4日起,我们发现之前上传的数据集不正确,已经重新上传了修正的数据集。
| 数据集 | 下载 |
|---|---|
| SPIN_iter0 | 🤗 HuggingFace |
| SPIN_iter1 | 🤗 HuggingFace |
| SPIN_iter2 | 🤗 HuggingFace |
| SPIN_iter3 | 🤗 HuggingFace |
运行代码所需的输入数据需要包含以下属性,与HuggingFaceH4/ultrafeedback_binarized类似:
{
"real": [{"role": "user", "content": <prompt>},
{"role": "assistant", "content": <ground truth>}],
"generated": [{"role": "user", "content": <prompt>},
{"role": "assistant", "content": <generation>}]
}
🔍 注意:在数据生成过程中,生成响应的内容可以为空,因为我们只使用提示来生成模型响应。
模型
我们还在HuggingFace上提供了迭代0、1、2、3的模型检查点。
| 模型 | 下载 |
|---|---|
| zephyr-7b-sft-full-SPIN-iter0 | 🤗 HuggingFace |
| zephyr-7b-sft-full-SPIN-iter1 | 🤗 HuggingFace |
| zephyr-7b-sft-full-SPIN-iter2 | 🤗 HuggingFace |
| zephyr-7b-sft-full-SPIN-iter3 | 🤗 HuggingFace |
🔍 注意:通过提供的数据,您可以直接跳到步骤2:微调而无需自行生成数据。您也可以从任何迭代开始,通过我们的开源模型检查点重现我们的结果。
使用
对于SPIN,我们一次性生成整个迭代的所有合成数据,并根据真实和合成数据对对LLM进行微调。
步骤0(可选):重新格式化SFT数据集
python spin/reformat.py [options]
选项
--data: SFT数据集的目录(本地或Huggingface)- 默认:
HuggingFaceH4/ultrachat_200k
- 默认:
--output_dir: 重新格式化的数据文件的本地目录- 默认:
UCLA-AGI/SPIN_iter0
- 默认:
🔍 注意:如果选择使用整个数据集HuggingFaceH4/ultrachat_200k而非我
第一步:生成
accelerate launch spin/generate.py [options]
选项
--model: 加载用于生成的模型检查点。- 默认值:
alignment-handbook/zephyr-7b-sft-full
- 默认值:
--input_dir: 包含生成提示数据文件的目录- 代码基于下面给出的格式生成数据。
- 默认值:
UCLA-AGI/SPIN_iter0
--output_dir: 保存生成数据的目录。--batch_size: 每个设备的批处理大小- 默认值:16
--data_frac: 将数据分成部分,以便在服务器上生成。--frac_len: 数据部分长度。默认值为0,使用整个数据集进行生成。将frac_len设为正数以仅生成部分数据。注意:我们建议使用较小的frac_len(例如800)通过小批量生成数据,以避免意外崩溃,因为数据生成可能非常耗时。- 将
data_frac设置为0,1,2...以生成长度为frac_len的不同部分。 - 注意:在使用
data_frac进行生成时,保持相同的frac_len。建议将较小的frac_len设置为800。
--split: 选择用于数据生成的分割- 默认值:
train
- 默认值:
生成的数据为json格式,每条数据包含以下属性:
{
"real": [{"role": "user", "content": <prompt>},
{"role": "assistant", "content": <ground truth>}],
"generated": [{"role": "user", "content": <prompt>},
{"role": "assistant", "content": <generation>}]
}
注意:数据生成的迭代次数完全取决于用于生成的模型(例如,使用初始SFT模型进行iter0数据生成,使用SPIN iter0模型进行iter1数据生成)。generate.py脚本将仅使用数据模型的提示/问题。
示例。 以下代码生成8k的合成数据,供迭代0使用。
bash scripts/generate.sh
🚀 使用vLLM更快的生成
或者,你可以使用以下示例脚本,通过加速生成LLM响应。可以与vLLM一起使用较大的frac_len。
bash scripts/generate_vllm.sh
感谢@sumo43实现了用于生成的vLLM。
第一步.5:收集生成结果并转换数据类型
python spin/convert_data.py [options]
选项
--num_fracs: 需要加载的文件数量。--input_dir: 生成数据文件的目录。--output_dir: 用于微调的统一数据目录。
该代码将生成两个最终数据文件,包括train_prefs-00000-of-00001.parquet和test_prefs-00000-of-00001.parquet,这些文件将用于微调。
注意:确保将生成的数据文件收集到--input_dir的目录中。
示例。
python spin/convert_data.py --output_dir new_data/iter0 --input_dir generated/iter0 --num_fracs 63
第二步:微调
accelerate launch --config_file configs/multi_gpu.yaml --num_processes=8 --main_process_port 29500 spin/run_spin.py configs/config.yaml
你可能需要更改configs/config.yaml中的配置。以下是一些你可能需要自定义的关键配置:
model_name_or_path: 加载用于微调的模型检查点。- 默认值:
alignment-handbook/zephyr-7b-sft-full
- 默认值:
dataset_mixer: 选择用于微调的数据混合。- 默认值:
UCLA-AGI/SPIN_iter0: 1.0 - 对于SPIN在第1和第2次迭代中,我们包含了当前迭代和前一次迭代的数据(例如,对于第1次迭代我们包含了
UCLA-AGI/SPIN_iter0: 1.0和UCLA-AGI/SPIN_iter1: 1.0,总共100k数据)。
- 默认值:
output_dir: 微调模型和检查点的输出目录。- 默认值:
outputs
- 默认值:
per_device_train_batch_size: 每个GPU上的批处理大小。- 默认值:16
gradient_accumulation_steps: 确保per_device_train_batch_size\*num_processes\*gradient_accumulation_steps的乘积等于你的实际批处理大小。num_train_epochs: 这次迭代的训练周期。- 默认值:3
beta: SPIN中的beta。- 默认值:0.1
在我们的实验中,我们在使用DeepSpeed ZeRO-3的多GPU机器上进行完整的微调(需要A100(80GB))。
示例。
bash scripts/finetune.sh
复现我们的结果
为了帮助您复现我们的结果,我们提供了与我们研究的四次迭代相对应的脚本。这些脚本已预先配置了我们论文中使用的确切参数和模型版本。对于每次迭代,基础模型初始化为🤗 HuggingFace发布的版本,可以在以下链接找到:
| 数据集 | 下载链接 |
|---|---|
| SPIN_iter0 | 🤗 HuggingFace |
| SPIN_iter1 | 🤗 HuggingFace |
| SPIN_iter2 | 🤗 HuggingFace |
| SPIN_iter3 | 🤗 HuggingFace |
要使用本地训练的模型作为基础模型执行完整的流程,请在配置文件中将model_name_or_path参数修改为指向你的模型路径。
要启动完整的微调过程,从终端运行相应的脚本:
bash scripts/finetune.sh
bash scripts/finetune_iter1.sh
bash scripts/finetune_iter2.sh
bash scripts/finetune_iter3.sh
通过这些步骤,你应该能够复现我们的结果。
评估
对于我们在Open LLM排行榜上的评估,请使用这个lm-evaluation-harness,其版本号为v0.4.0。另外,请注意我们将小样本示例的数量设置为与排行榜上的指示相同。不同的评估版本会导致不同的分数,但趋势将保持一致。
星历史
引用
如果您发现本仓库对您的研究有用,请考虑引用本文
@misc{chen2024selfplay,
title={Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models},
author={Zixiang Chen and Yihe Deng and Huizhuo Yuan and Kaixuan Ji and Quanquan Gu},
year={2024},
eprint={2401.01335},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
致谢
本仓库建立在The Alignment Handbook的基础上。我们感谢作者的伟大工作。









