
 访问官网
访问官网 Github
Github 文档
文档 论文
论文CARLA-Roach
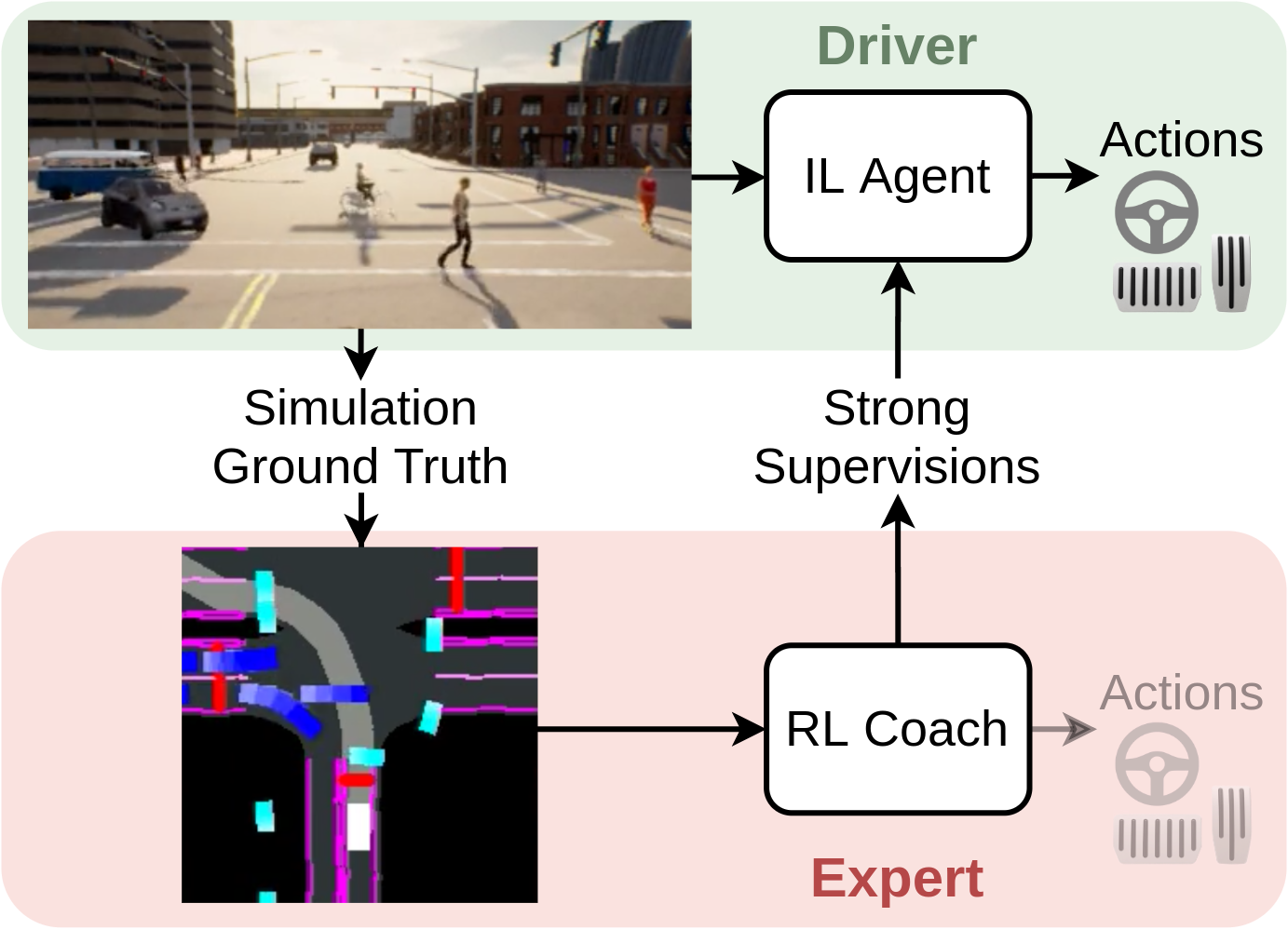
这是论文的官方代码发布
通过模仿强化学习教练实现端到端城市驾驶
作者:张哲骏、Alexander Liniger、戴登新、俞飞跃和Luc van Gool,发表于ICCV 2021。
它包含了基准测试、离线策略数据收集、在线策略数据收集、强化学习训练和使用DAGGER进行模仿学习训练的代码。 它还包含了强化学习专家和模仿学习智能体的训练模型。 补充视频可以在论文的主页上找到。
离线排行榜
我们评估的"排行榜"是CARLA排行榜的离线版本。正如在论文中进一步详述的那样,离线排行榜有以下设置
- 地图和路线:按照排行榜公开路线进行训练/测试分割。
- 指标:遵循排行榜评估和指标。
- 天气:按照NoCrash进行训练/测试分割。
- 背景交通:遵循NoCrash
如果想对方法的泛化能力进行彻底研究,可以使用离线排行榜。
在线排行榜的优缺点:
(+) 所有方法都在完全相同的条件下进行评估。
(+) 无需重新评估其他方法。
(-) 对方法的训练方式和训练数据的收集方式没有限制。
离线排行榜的优缺点:
(+) 严格规定了训练和测试环境。
(+) 对基准测试有完全的控制和观察。
(-) 如果基准测试的任何设置发生变化,例如CARLA版本等,您将不得不重新评估其他方法。
安装
请参考INSTALL.md进行安装。 我们使用AWS EC2,但您也可以在自己的计算机或集群上安装和运行所有实验。
快速开始:使用Roach收集专家数据集
Roach是一个端到端训练的智能体,比手工制作的CARLA专家驾驶得更好、更自然。 要从Roach收集数据集,请使用run/data_collect_bc.sh并修改以下参数:
save_to_wandb:如果您不想将数据集上传到W&B,请设置为False。dataset_root:保存数据集的本地目录。test_suites:默认为eu_data,在Town01中收集NoCrash-dense基准测试的数据。可用配置可在此处找到。您也可以创建自己的配置。n_episodes:要收集的episode数量,每个episode将保存到单独的h5文件中。agent/cilrs/obs_configs:观察(即传感器)配置,默认为central_rgb_wide。可用配置可在此处找到。您也可以创建自己的配置。inject_noise:默认为True。如CILRS中介绍的那样,向转向和油门注入三角形噪声,使自我车辆不总是沿车道中心行驶。对模仿学习非常有用。actors.hero.terminal.kwargs.max_time:一个episode的最大持续时间,以秒为单位。- 如果违反交通规则,提前结束episode,以便收集的数据集没有错误。
actors.hero.terminal.kwargs.no_collision:默认为True。actors.hero.terminal.kwargs.no_run_rl:默认为False。actors.hero.terminal.kwargs.no_run_stop:默认为False。
基准测试
要对检查点进行基准测试,请使用run/benchmark.sh并修改参数以选择不同的设置。
我们推荐使用g4dn.xlarge,并有50 GB的可用磁盘空间用于视频录制。
如果您想在后台运行它,请使用screen
screen -L -Logfile ~/screen.log -d -m run/benchmark.sh
训练模型
训练好的模型托管在W&B上的这里。 给定相应的W&B运行路径,我们的代码将自动下载并加载检查点和配置yaml文件。 以下是我们论文中报告结果所使用的检查点。
- 要对自动驾驶仪进行基准测试,使用
benchmark()并设置agent="roaming"。 - 要对RL专家进行基准测试,使用
benchmark()并设置agent="ppo",同时将agent.ppo.wb_run_path设置为以下之一。iccv21-roach/trained-models/1929isj0:Roachiccv21-roach/trained-models/1ch63m76:PPO+betaiccv21-roach/trained-models/10pscpih:PPO+exp
- 要对IL代理进行基准测试,使用
benchmark()并设置agent="cilrs",同时将agent.cilrs.wb_run_path设置为以下之一。- 为NoCrash基准测试训练的检查点,在DAGGER第5次迭代时:
iccv21-roach/trained-models/39o1h862:L_A(AP)iccv21-roach/trained-models/v5kqxe3i:L_Aiccv21-roach/trained-models/t3x557tv:L_Kiccv21-roach/trained-models/1w888p5d:L_K+L_Viccv21-roach/trained-models/2tfhqohp:L_K+L_Ficcv21-roach/trained-models/3vudxj38:L_K+L_V+L_Ficcv21-roach/trained-models/31u9tki7:L_K+L_F(c)iccv21-roach/trained-models/aovrm1fs:L_K+L_V+L_F(c)
- 为LeaderBoard基准测试训练的检查点,在DAGGER第5次迭代时:
iccv21-roach/trained-models/1myvm4mw:L_A(AP)iccv21-roach/trained-models/nw226h5h:L_Aiccv21-roach/trained-models/12uzu2lu:L_Kiccv21-roach/trained-models/3ar2gyqw:L_K+L_Viccv21-roach/trained-models/9rcwt5fh:L_K+L_Ficcv21-roach/trained-models/2qq2rmr1:L_K+L_V+L_Ficcv21-roach/trained-models/zwadqx9z:L_K+L_F(c)iccv21-roach/trained-models/21trg553:L_K+L_V+L_F(c)
- 为NoCrash基准测试训练的检查点,在DAGGER第5次迭代时:
可用的测试套件
将参数test_suites设置为以下之一。
- NoCrash-busy
eu_test_tt:NoCrash,繁忙交通,训练城镇和训练天气eu_test_tn:NoCrash,繁忙交通,训练城镇和新天气eu_test_nt:NoCrash,繁忙交通,新城镇和训练天气eu_test_nn:NoCrash,繁忙交通,新城镇和新天气eu_test:eu_test_tt/tn/nt/nn,一个文件中包含所有4种条件
- NoCrash-dense
nocrash_dense:NoCrash,密集交通,所有4种条件
- LeaderBoard:
lb_test_tt:LeaderBoard,繁忙交通,训练城镇和训练天气lb_test_tn:LeaderBoard,繁忙交通,训练城镇和新天气lb_test_nt:LeaderBoard,繁忙交通,新城镇和训练天气lb_test_nn:LeaderBoard,繁忙交通,新城镇和新天气lb_test:lb_test_tt/tn/nt/nn,一个文件中包含所有4种条件
- LeaderBoard-all
cc_test:LeaderBoard,繁忙交通,所有76条路线,动态天气
收集数据集
我们建议使用g4dn.xlarge来收集数据集。确保实例上有足够的磁盘空间。
收集离线策略数据集
要收集离线策略数据集,使用run/data_collect_bc.sh并修改参数以选择不同的设置。
您可以使用Roach(给定一个检查点)或自动驾驶仪来收集离线策略数据集。
在我们的论文中,在DAGGER训练之前,IL代理通过行为克隆(BC)使用以这种方式收集的离线策略数据集进行初始化。
您可能想要修改的一些参数:
- 如果不想将数据集上传到W&B,设置
save_to_wandb=False。 - 通过将参数
test_suites设置为以下之一来选择收集数据的环境eu_data:NoCrash,训练城镇和训练天气。我们为NoCrash的BC数据集收集n_episodes=80,大约75 GB和6小时的数据。lb_data:LeaderBoard,训练城镇和训练天气。我们为LeaderBoard的BC数据集收集n_episodes=160,大约150 GB和12小时的数据。cc_data:CARLA Challenge,所有六个地图(Town1-6),动态天气。我们为CARLA Challenge的BC数据集收集n_episodes=240,大约150 GB和18小时的数据。
- 对于RL专家,使用的检查点通过
agent.ppo.wb_run_path和agent.ppo.wb_ckpt_step设置。agent.ppo.wb_run_path是记录RL训练并保存检查点的W&B运行路径。agent.ppo.wb_ckpt_step是您想使用的检查点的步骤。如果是整数,脚本将找到最接近该步骤的检查点。如果为null,将使用最新的检查点。
收集在线策略数据集
要收集在线策略数据集,使用run/data_collect_dagger.sh并修改参数以选择不同的设置。
您可以使用Roach或自动驾驶仪来标记由IL代理(给定一个检查点)生成的在线策略(DAGGER)数据集。
这是通过使用IL代理作为驾驶员,Roach/自动驾驶仪作为教练来运行data_collect.py实现的。
因此,专家监督是实时生成和记录的。
大多数内容与收集离线策略BC数据集相同。以下是一些变化:
- 将
agent.cilrs.wb_run_path设置为记录IL训练并保存检查点的W&B运行路径。 - 通过调整
n_episodes,我们确保每次迭代的DAGGER数据集大小约为BC数据集大小的20%。- 对于RL专家,我们使用的
n_episodes是BC数据集n_episodes的一半。 - 对于自动驾驶仪,我们使用的
n_episodes与BC数据集的n_episodes相同。
- 对于RL专家,我们使用的
训练RL专家
要训练RL专家,使用run/train_rl.sh并修改参数以选择不同的设置。
我们建议使用g4dn.4xlarge来训练RL专家,您需要大约50 GB的可用磁盘空间用于视频和检查点。
我们在CARLA 0.9.10.1上训练RL专家,因为0.9.11由于未知原因更容易崩溃。
训练IL代理
要训练IL代理,请使用run/train_il.sh并修改参数以选择不同的设置。
训练IL代理不需要CARLA,这是一项GPU密集型任务。因此,我们建议使用AWS p实例或您的集群来运行IL训练。
我们的实现遵循DA-RB(论文,代码库),该方法使用DAGGER训练CILRS(论文,代码库)代理。
训练从使用离线策略数据集通过行为克隆训练基本CILRS开始。
- 收集离线策略DAGGER数据集。
- 训练IL模型。
- 对训练好的模型进行基准测试。
然后重复以下DAGGER步骤,直到模型达到理想的结果。
- 收集在线策略DAGGER数据集。
- 训练IL模型。
- 对训练好的模型进行基准测试。
对于BC训练,需要设置以下参数。
- 数据集
dagger_datasets:字符串向量,对于BC训练,它应该只包含BC数据集的路径(本地或W&B)。
- 测量向量
agent.cilrs.env_wrapper.kwargs.input_states可以是[speed,vec,cmd]的子集speed:标量自车速度vec:指向下一个GNSS航点的2D向量cmd:高级命令的独热向量
- 分支
- 对于6个分支:
agent.cilrs.policy.kwargs.number_of_branches=6agent.cilrs.training.kwargs.branch_weights=[1.0,1.0,1.0,1.0,1.0,1.0]
- 对于1个分支:
agent.cilrs.policy.kwargs.number_of_branches=1agent.cilrs.training.kwargs.branch_weights=[1.0]
- 对于6个分支:
- 动作损失
- L1动作损失
agent.cilrs.env_wrapper.kwargs.action_distribution=nullagent.cilrs.training.kwargs.action_kl=false
- KL损失
agent.cilrs.env_wrapper.kwargs.action_distribution="beta_shared"agent.cilrs.training.kwargs.action_kl=true
- L1动作损失
- 价值损失
- 禁用
agent.cilrs.env_wrapper.kwargs.value_as_supervision=falseagent.cilrs.training.kwargs.value_weight=0.0
- 启用
agent.cilrs.env_wrapper.kwargs.value_as_supervision=trueagent.cilrs.training.kwargs.value_weight=0.001
- 禁用
- 预训练的动作/价值头
agent.cilrs.rl_run_path和agent.cilrs.rl_ckpt_step用于使用Roach的动作/价值头初始化IL代理的动作/价值头。
- 特征损失
- 禁用
agent.cilrs.env_wrapper.kwargs.dim_features_supervision=0agent.cilrs.training.kwargs.features_weight=0.0
- 启用
agent.cilrs.env_wrapper.kwargs.dim_features_supervision=256agent.cilrs.training.kwargs.features_weight=0.05
- 禁用
在DAGGER训练期间,将加载已训练的IL代理,您不能再更改配置。您需要设置
agent.cilrs.wb_run_path:记录先前IL训练和保存检查点的W&B运行路径。agent.cilrs.wb_ckpt_step:您想使用的检查点的步骤。将其保留为null将加载最新的检查点。dagger_datasets:字符串向量,按时间倒序排列的DAGGER数据集和BC数据集的W&B运行路径或本地路径,例如[PATH_DAGGER_DATA_2, PATH_DAGGER_DATA_1, PATH_DAGGER_DATA_0, BC_DATA]train_epochs:如果您想训练更多轮次,可以选择更改此参数。
引用
如果您觉得我们的工作有用,请引用:
@inproceedings{zhang2021roach,
title = {End-to-End Urban Driving by Imitating a Reinforcement Learning Coach},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
author = {Zhang, Zhejun and Liniger, Alexander and Dai, Dengxin and Yu, Fisher and Van Gool, Luc},
year = {2021},
}
许可证
本软件在CC-BY-NC 4.0许可下发布,仅允许个人和研究使用。如需商业许可,请联系作者。您可以在这里查看许可证摘要。
从外部来源获取的部分源代码已注明原始文件的链接及其相应的许可证。
致谢
本工作得到了丰田欧洲汽车公司的支持,并在苏黎世联邦理工学院的TRACE实验室(丰田欧洲自动驾驶汽车研究 - 苏黎世)进行。











