
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文 zhlint
zhlint
一个用于中文文本内容的检查工具。
如何安装
你可以通过 npm 或 yarn 轻松安装 zhlint:
# 通过 npm 安装
npm install zhlint -g
# 或通过 yarn 安装
yarn global add zhlint
# 或通过 pnpm 安装
pnpm add zhlint -g
使用方法
作为命令行工具
# 使用通配符匹配文件,对其进行检查,并打印验证报告,
# 如果发现任何错误,则以代码 `1` 退出。
zhlint <文件模式>
# 使用通配符匹配文件并修复所有可能发现的错误。
zhlint <文件模式> --fix
# 检查文件并将修复后的内容输出到另一个文件
zhlint <输入文件路径> --output=<输出文件路径>
# 打印使用说明
zhlint --help
验证报告可能看起来像这样:

高级用法
zhlint 还支持 rc 和 ignore 配置文件来自定义规则:
# 默认为 .zhlintrc
zhlint --config <文件路径>
# 默认为 .zhlintignore
zhlint --ignore <文件路径>
zhlint --file-ignore <文件路径>
# 默认为 .zhlintcaseignore
zhlint --case-ignore <文件路径>
# 默认为当前目录
zhlint --dir <路径>
在 rc 配置文件中,你可以编写如下 JSON:
{
"preset": "default",
"rules": {
"adjustedFullwidthPunctuation": ""
}
}
更多详细信息,请参阅支持的规则。
在 file-ignore 文件中,你可以使用 .gitignore 语法编写一些行来忽略文件:
在 case-ignore 文件中,你可以编写一些被忽略的情况,如:
( , )
更多详细信息,请参阅设置忽略的情况。
作为 Node.js 包
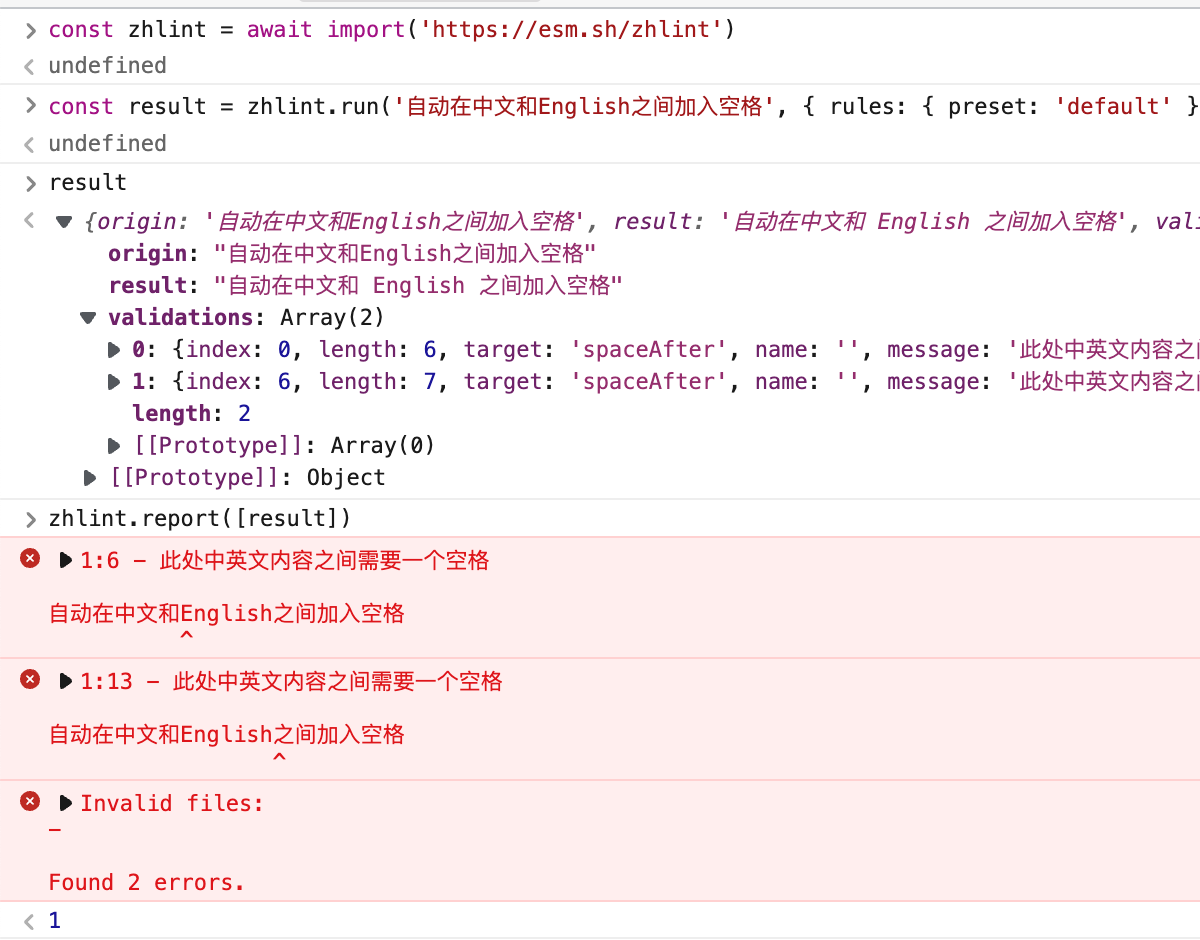
const { run, report } = require('zhlint')
const value = '自动在中文和English之间加入空格'
const options = { rules: { preset: 'default' } }
const output = run(value, options)
// 打印 '自动在中文和 English 之间加入空格''
console.log(output.result)
// 打印验证报告
report([output])
验证报告的格式更像这样:
1:6 - 此处中英文内容之间需要一个空格
自动在中文和English之间加入空格
^
1:13 - 此处中英文内容之间需要一个空格
自动在中文和English之间加入空格
^
无效文件:
- foo.md
发现 2 个错误。
高级用法
zhlint 还支持 rc 和 ignore 配置文件来自定义规则:
const { readRc, runWithConfig } = require('zhlint')
const value = '自动在中文和English之间加入空格'
const dir = '...' // 目标目录路径
const configPath = '...' // 配置文件路径
const fileIgnorePath = '...' // file-ignore 文件路径
const caseIgnorePath = '...' // case-ignore 文件路径
const config = readRc(dir, configPath, fileIgnorePath, caseIgnorePath)
const output = runWithConfig(value, config)
// ... 进一步操作
作为独立包
你可以在 dist/zhlint.js 中找到一个独立版本的 JavaScript 文件。例如,你可以直接将其作为 <script> 标签添加到你的浏览器中。然后就会有一个全局变量 zhlint 供你使用。
API
run(str: string, options?: Options): Result:检查特定内容。- 参数:
str:你想要检查的文本内容。options:一些配置选项。
- 返回:
- 单个输入字符串的结果。它包含修复后的文本内容作为
value以及所有validations的信息。
- 单个输入字符串的结果。它包含修复后的文本内容作为
- 参数:
report(results: Result[], logger?: Console): void:打印每个文件的验证报告。- 参数:
results:所有已检查结果的数组。logger:日志记录器实例,默认在 Node.js/浏览器中是console。
- 参数:
readRc: (dir: string, config: string, fileIgnore: string, caseIgnore: string, logger?: Console) => Config:从 rc 和 ignore 文件读取配置。runWithConfig(str: string, config: Config): Result:使用 rc 配置检查特定内容。
选项
自定义你自己的检查配置和其他高级选项。
type Options = {
rules?: RuleOptions
hyperParse?: string[]
ignoredCases?: IgnoredCase[]
logger?: Console
}
rules:自定义检查配置。它可以是undefined,表示不进行任何检查。它可以是{ preset: 'default' },表示使用默认配置。有关RuleOptions的更多详细信息,请参阅支持的规则。hyperParse:通过名称自定义超级解析器。它可以是undefined,表示仅使用默认的忽略情况解析器、Markdown 解析器和 Hexo 标签解析器。ignoredCases:提供你想要跳过的例外情况。IgnoredCase:{ prefix?, textStart, textEnd?, suffix? }- 遵循特定格式
[prefix-,]textStart[,textEnd][,-suffix],灵感来自 W3C Scroll To Text Fragment 提案。
- 遵循特定格式
logger:与report(...)中的参数相同。
RC 配置
preset:string(可选)rules:不包含preset字段的RuleOptions。(可选)hyperParsers:string[](可选)caseIgnores:string[],优先级低于.zhlintcaseignore。(可选)
输出
type Result = {
// 文件的基本信息和可用性
file?: string
disabled: boolean
// 文件的原始内容
origin: string
// 所有错误消息
validations: Validation[]
}
type Validation = {
message: string
index: number
length: number
}
Resultfile:文件名。这是一个可选字段,仅在命令行界面中使用。origin:原始文本内容。result:最终修正后的文本内容。validations:所有验证信息。
Validationindex:目标标记在输入字符串中的索引。length:目标标记在输入字符串中的长度。message:以自然语言描述的验证信息。
功能
支持 Markdown 语法
我们默认支持对 Markdown 语法的文本内容进行检查。例如:
run('自动在_中文_和**English**之间加入空格', options)
它会先分析 Markdown 语法并提取纯文本内容进行检查。之后,修正后的纯文本内容会被替换回原始的 Markdown 字符串,并作为结果中的 value 输出。
支持 Hexo 标签语法
特别地,我们支持 Hexo 标签语法,因为在使用 Hexo 构建 Vue.js 网站时,markdown 源文件多多少少会包含这些特殊标签,从而导致意外的结果。
因此,我们默认额外跳过 Hexo 风格的标签。例如:
run(
'现在过滤器只能用在插入文本中 (`{% raw %}{{ }}{% endraw %}` tags)。',
options
)
设置忽略情况
在某些实际情况下,我们有特殊的文本内容因故意不遵循规则。因此,我们可以使用 ignoredCases 选项来配置。例如,我们想保留括号内的空格,这在默认情况下是无效的。那么我们可以在文件中的任何位置添加一行 HTML 注释:
<!-- 正确的情况 -->
前面的文本 (里面的文本) 后面的文本
<!-- 错误的情况 -->
vm.$on( event, callback )
<!-- 然后我们可以在下面写这行来使其生效 -->
<!-- zhlint ignore: ( , ) -->
或者直接作为选项传递:
run(str, { ignoredCases: { textStart: '( ', textEnd: ' )' } })
如果你想忽略整个文件,你也可以添加这个 HTML 注释:
<!-- zhlint disabled -->
支持的预处理器(超级解析器)
ignore:通过 HTML 注释<!-- zhlint ignore: ... -->查找所有被忽略的部分。hexo:查找所有 Hexo 标签以避免它们被解析。markdown:解析 markdown 语法并查找所有块级文本和内联级标记。
支持的规则
大多数规则来自于过去在 W3C 中文文字排版需求、W3C HTML 中文兴趣小组 和 Vue.js 中文文档站点 的翻译经验。
... 这部分可能会有争议。因此,如果你对某些地方感到不适,我们非常乐意了解并改进。随时欢迎提出 issue。然后我们可以讨论可能的更好选择或决定。
type RuleOptions = {
/* 预设 */
// 自定义预设,目前仅支持:
// - `'default'`
preset?: string
/* 标点符号 */
// 将这些标点符号转换为半角。
// 默认预设:`()`
// 例如:`(文字)` -> `(文字)`
halfwidthPunctuation?: string
// 将这些标点符号转换为全角。
// 默认预设:`,。:;?!""''`
// 例如:`文字,文字.` -> `文字,文字。`
fullwidthPunctuation?: string
// 在处理它们周围的空格问题时,将这些全角标点符号视为半全角标点符号。
// 因为像引号这样的东西在现代中文字体中只以半角形式呈现。
// 默认预设:`""''`
adjustedFullwidthPunctuation?: string
// 将繁体中文标点符号转换为简体或反之。
// 默认预设:`simplified`
// 例如:`「文字」` -> `"文字"`
//
// 除此之外,我们还统一了一些常见的标点符号:
//
// // U+2047 双问号,U+203C 双叹号
// // U+2048 问号叹号,U+2049 叹号问号
// '??': ['⁇'],
// '!!': ['‼'],
// '?!': ['⁈'],
// '!?': ['⁉'],
//
// // U+002F 斜线,U+FF0F 全角斜线
// '/': ['/', '/'],
//
// // U+FF5E 全角波浪线
// '~': ['~', '~'],
//
// // U+2026 水平省略号,U+22EF 中线水平省略号
// '…': ['…', '⋯'],
//
// // U+25CF 黑圆圈,U+2022 项目符号,U+00B7 中点,
// // U+2027 连字点,U+30FB 片假名中点
// '·': ['●', '•', '·', '‧', '・'],
//
// 高级用法:你也可以指定一个更详细的映射,如:
//
// ```
// {
// default: true, // 遵循所有默认预设
// '「': ['"', '【'], // 将 `"` 或 `【` 转换为 `「`
// '」': ['"', '】'], // 将 `"` 或 `】` 转换为 `」`
// '…': true, // 遵循此字符的默认预设
// '·': false, // 不统一这些字符中的任何一个
// }
// ```
unifiedPunctuation?:
| 'traditional'
| 'simplified'
| (Record<string, boolean | string[]> & { default: boolean })
// 特殊情况:对缩写跳过 `fullWidthPunctuation`。
// 默认预设:
// `['Mr.','Mrs.','Dr.','Jr.','Sr.','vs.','etc.','i.e.','e.g.','a.k.a']`
skipAbbrs?: string[]
/* 字母周围的空格 */
// 默认预设:`true`
// - `true`:一个空格
// - `undefined`:不做任何处理
// 例如:`foo bar` -> `foo bar`
spaceBetweenHalfwidthContent?: boolean
// 默认预设:`true`
// - `true`:零个空格
// - `undefined`:不做任何处理
// 例如:`文 字` -> `文字`
noSpaceBetweenFullwidthContent?: boolean
// 默认预设:`true`
// - `true`:一个空格
// - `false`:零个空格
// - `undefined`:不做任何处理
// 例如:`文字 foo文字` -> `文字 foo 文字`(`true`)
// 例如:`文字foo 文字` -> `文字foo文字`(`false`)
spaceBetweenMixedwidthContent?: boolean
// 特殊情况:跳过数字与中文单位之间的`spaceBetweenMixedWidthContent`
// 默认预设:`年月日天号时分秒`
skipZhUnits?: string
/* 标点符号周围的空格 */
// 默认预设:`true`
// - `true`:零空格
// - `undefined`:不做处理
// 例如:`文字 ,文字` -> `文字,文字`
noSpaceBeforePauseOrStop?: boolean
// 默认预设:`true`
// - `true`:一个空格
// - `false`:零空格
// - `undefined`:不做处理
// 例如:`文字,文字` -> `文字, 文字`(`true`)
// 例如:`文字, 文字` -> `文字,文字`(`false`)
spaceAfterHalfwidthPauseOrStop?: boolean
// 默认预设:`true`
// - `true`:零空格
// - `undefined`:不做处理
// 例如:`文字, 文字` -> `文字,文字`
noSpaceAfterFullwidthPauseOrStop?: boolean
/* 引号周围的空格 */
// 默认预设:`true`
// - `true`:一个空格
// - `false`:零空格
// - `undefined`:不做处理
// 例如:`文字 "文字"文字` -> `文字 "文字" 文字`(`true`)
// 例如:`文字"文字" 文字` -> `文字"文字"文字`(`false`)
spaceOutsideHalfwidthQuotation?: boolean
// 默认预设:`true`
// - `true`:零空格
// - `undefined`:不做处理
// 例如:`文字 "文字" 文字` -> `文字"文字"文字`
noSpaceOutsideFullwidthQuotation?: boolean
// 默认预设:`true`
// - `true`:零空格
// - `undefined`:不做处理
// 例如:`文字" 文字 "文字` -> `文字"文字"文字`
noSpaceInsideQuotation?: boolean
/* 括号周围的空格 */
// 默认预设:`true`
// - `true`:一个空格
// - `false`:零空格
// - `undefined`:不做处理
spaceOutsideHalfwidthBracket?: boolean
// 默认预设:`true`
// - `true`:零空格
// - `undefined`:不做处理
noSpaceOutsideFullwidthBracket?: boolean
// 默认预设:`true`
// - `true`:零空格
// - `undefined`:不做处理
noSpaceInsideBracket?: boolean
/* 代码周围的空格 */
// 默认预设:`true`
// - `true`:一个空格
// - `false`:零空格
// - `undefined`:不做处理
// 例如:'文字 `code`文字' -> '文字 `code` 文字'('true')
// 例如:'文字`code` 文字' -> '文字`code`文字'('false')
spaceOutsideCode?: boolean
/* Markdown/HTML包裹符周围的空格 */
// 默认为`true`
// - `true`:零空格
// - `undefined`:不做处理
// 例如:`文字** foo **文字` -> `文字 **foo** 文字`
noSpaceInsideHyperMark?: boolean
/* 开头/结尾的空格 */
// 默认为`true`
// 例如:` 文字 ` -> `文字`
trimSpace?: boolean
/* 跳过纯西文句子 */
// 默认为`true`
skipPureWestern?: boolean
}











