
 访问官网
访问官网 Github
Github 文档
文档Collaborative Diffusion (CVPR 2023)


此存储库包含以下论文的实现:
用于多模态人脸生成和编辑的协同扩散
黄子琦、陈志康、蒋毓明、刘子维
IEEE/CVF国际计算机视觉会议(CVPR),2023年
来自南洋理工大学的MMLab,隶属于智星实验室
:open_book: 概述
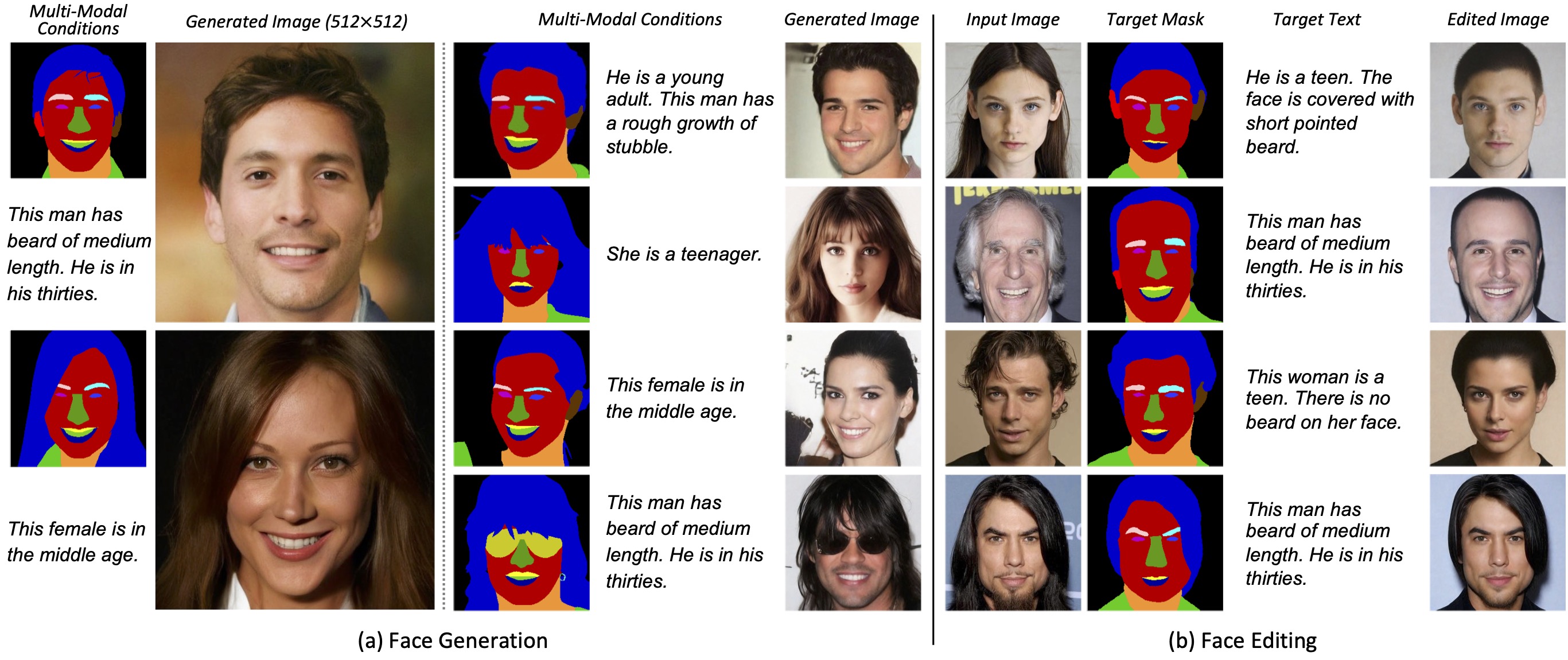
我们提出了协同扩散,用户可以使用多种模态对人脸生成和编辑进行控制。 (a) 面部生成。在给定多模态控制的情况下,我们的框架可以合成与输入条件一致的高质量图像。 (b) 面部编辑。协同扩散还支持对真实图像进行多模态编辑,并具有良好的身份保留能力。
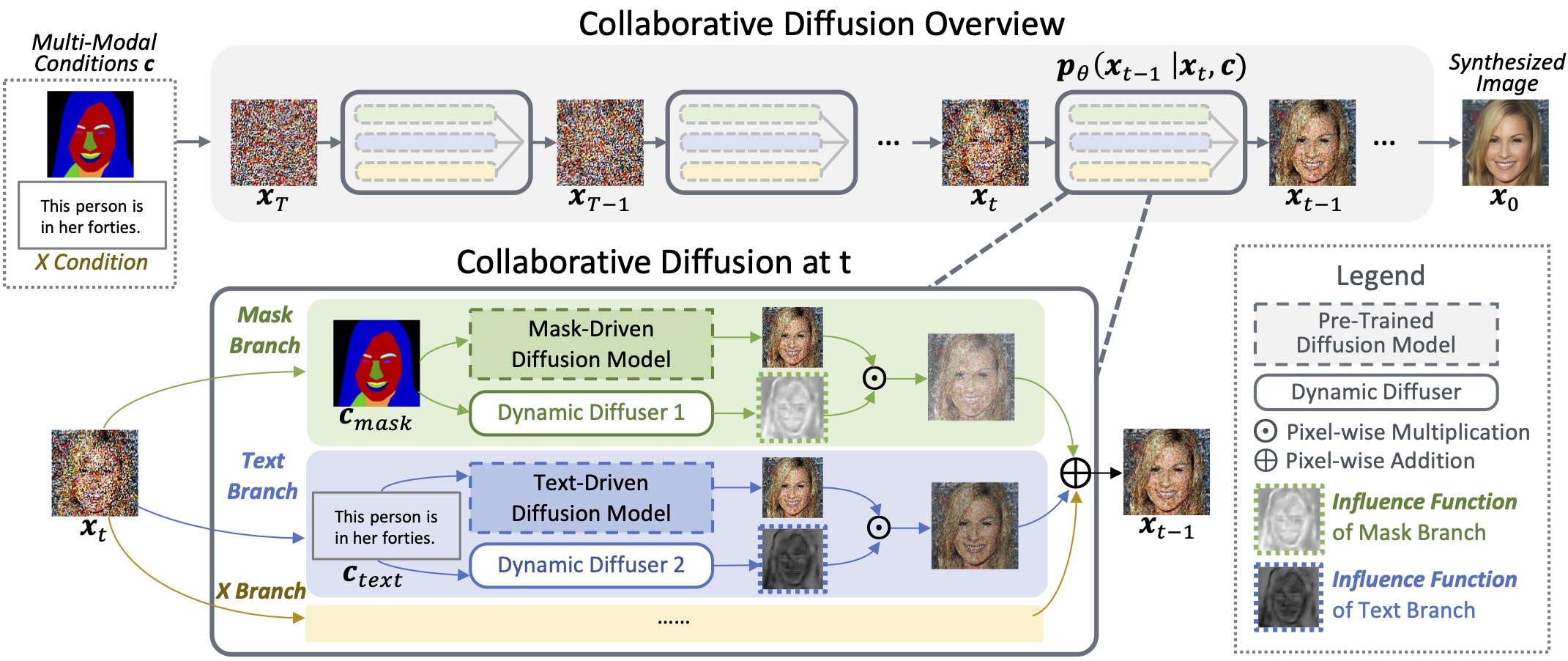
我们使用预训练的单模态扩散模型进行多模态引导的人脸生成和编辑。在逆过程(即从t时刻到t-1时刻)的每一步中,动态扩散器预测空间和时间变化的影响函数,以选择性地增强或抑制给定模态的贡献。
:heavy_check_mark: 更新
- [10/2023] 协同扩散现在可以支持FreeU。请参阅此处了解如何运行协同扩散+FreeU。
- [09/2023] 我们提供了单一模态驱动的人脸生成的推理脚本,以及256x256分辨率的脚本和检查点。
- [09/2023] 编辑代码 已发布。
- [06/2023] 我们提供了预处理的多模态注释此处。
- [05/2023] 协同扩散的训练代码(512x512)发布。
- [04/2023] 项目页面 和视频可用。
- [04/2023] Arxiv论文可用。
- [04/2023] 多模态人脸生成(512x512)的检查点发布。
- [04/2023] 多模态人脸生成(512x512)的推理代码发布。
:hammer: 安装
-
克隆仓库
git clone https://github.com/ziqihuangg/Collaborative-Diffusion cd Collaborative-Diffusion -
创建conda环境。
如果您已经根据LDM安装了ldm环境,则不需要执行此步骤(即步骤2)。您可以直接conda activate ldm并跳到步骤3。conda env create -f environment.yaml conda activate codiff -
安装依赖项
pip install transformers==4.19.2 scann kornia==0.6.4 torchmetrics==0.6.0 conda install -c anaconda git pip install git+https://github.com/arogozhnikov/einops.git
:arrow_down: 下载
下载检查点
-
从Google Drive或OneDrive下载预训练模型。
-
将模型放在
pretrained目录下,如下所示:Collaborative-Diffusion └── pretrained ├── 256_codiff_mask_text.ckpt ├── 256_mask.ckpt ├── 256_text.ckpt ├── 256_vae.ckpt ├── 512_codiff_mask_text.ckpt ├── 512_mask.ckpt ├── 512_text.ckpt └── 512_vae.ckpt
下载数据集
我们提供了本项目中使用的预处理数据(请参见鸣谢部分的数据来源)。只有在您希望重新生成协同扩散的训练时,才需要下载它们。如果您只想使用我们预训练的模型进行推理,可以跳过此步骤。
-
从此处下载预处理的训练数据。
-
将数据集放在
dataset目录下,如下所示:Collaborative-Diffusion └── dataset ├── image | └──image_512_downsampled_from_hq_1024 ├── text | └──captions_hq_beard_and_age_2022-08-19.json ├── mask | └──CelebAMask-HQ-mask-color-palette_32_nearest_downsampled_from_hq_512_one_hot_2d_tensor └── sketch └──sketch_1x1024_tensor
关于注释的更多详细信息,请参阅CelebA-Dialog。
:framed_picture: 生成
多模态驱动生成
您可以使用文本和分割掩码来控制人脸生成。
-
mask_path是分割掩码的路径,input_text是文本条件。python generate.py \ --mask_path test_data/512_masks/27007.png \ --input_text "这个男人留着中等长度的胡子。他三十多岁。"python generate.py \ --mask_path test_data/512_masks/29980.png \ --input_text "这个女人四十多岁。" -
您可以通过将标志设置为
1来查看不同类型的中间输出。例如,要查看影响函数,可以将return_influence_function设置为1。
python generate.py \
--mask_path test_data/512_masks/27007.png \
--input_text "This man has beard of medium length. He is in his thirties." \
--ddim_steps 10 \
--batch_size 1 \
--save_z 1 \
--return_influence_function 1 \
--display_x_inter 1 \
--save_mixed 1
```
请注意,生成中间结果可能会消耗大量的GPU内存,因此我们建议将`batch_size`设置为`1`,并将`ddim_steps`设置为较小的值(例如,`10`)以节省内存和计算时间。
3. 我们的脚本默认合成512x512分辨率的图像。您可以通过更改配置和ckpt文件生成256x256的图像:
```bash
python generate.py \
--mask_path test_data/256_masks/29980.png \
--input_text "This woman is in her forties." \
--config_path "configs/256_codiff_mask_text.yaml" \
--ckpt_path "pretrained/256_codiff_mask_text.ckpt" \
--save_folder "outputs/inference_256_codiff_mask_text"
```
### 文本到人脸生成
1. 给出文本提示并生成人脸图像:
```bash
python text2image.py \
--input_text "This man has beard of medium length. He is in his thirties."
```
```bash
python text2image.py \
--input_text "This woman is in her forties."
```
2. 我们的脚本默认合成512x512分辨率的图像。您可以通过更改配置和ckpt文件生成256x256的图像:
```bash
python text2image.py \
--input_text "This man has beard of medium length. He is in his thirties." \
--config_path "configs/256_text.yaml" \
--ckpt_path "pretrained/256_text.ckpt" \
--save_folder "outputs/256_text2image"
```
### 掩码到人脸生成
1. 提供面部分割掩码并生成人脸图像:
```bash
python mask2image.py \
--mask_path "test_data/512_masks/29980.png"
```
```bash
python mask2image.py \
--mask_path "test_data/512_masks/27007.png"
```
2. 我们的脚本默认合成512x512分辨率的图像。您可以通过更改配置和ckpt文件生成256x256的图像:
```bash
python mask2image.py \
--mask_path "test_data/256_masks/29980.png" \
--config_path "configs/256_mask.yaml" \
--ckpt_path "pretrained/256_mask.ckpt" \
--save_folder "outputs/256_mask2image"
```
## :art: 编辑
您可以根据目标掩码和目标文本编辑面部图像。我们通过协作多个单模态编辑来实现这一点。我们使用[Imagic](https://imagic-editing.github.io/)来执行单模态编辑。
1. 执行基于文本的编辑。
```bash
python editing/imagic_edit_text.py
```
1. 执行基于掩码的编辑。请注意,我们将Imagic(基于文本的方法)改编为基于掩码的编辑。
```bash
python editing/imagic_edit_mask.py
```
3. 使用协作扩散协作文本编辑和掩码编辑。
```bash
python editing/collaborative_edit.py
```
## :runner: 训练
我们提供了完整的训练管道,包括训练VAE、单模态扩散模型和我们提出的动态扩散器。
如果您只对训练动态扩散器感兴趣,您可以使用我们提供的VAE和单模态扩散模型的检查点。只需跳过步骤1和2,直接查看步骤3。
1. **训练VAE。**
LDM将图像压缩到VAE潜在空间,以节省计算成本,随后在VAE潜在空间上训练UNet扩散模型。此步骤用来重新生成`pretrained/512_vae.ckpt`。
```bash
python main.py \
--logdir 'outputs/512_vae' \
--base 'configs/512_vae.yaml' \
-t --gpus 0,1,2,3,
```
2. **训练单模态扩散模型。**
(1) 训练文本到图像模型。此步骤用来重新生成`pretrained/512_text.ckpt`。
```bash
python main.py \
--logdir 'outputs/512_text' \
--base 'configs/512_text.yaml' \
-t --gpus 0,1,2,3,
```
(2) 训练掩码到图像模型。此步骤用来重新生成`pretrained/512_mask.ckpt`。
```bash
python main.py \
--logdir 'outputs/512_mask' \
--base 'configs/512_mask.yaml' \
-t --gpus 0,1,2,3,
```
3. **训练动态扩散器。**
动态扩散器是确定单模态扩散模型如何协作的元网络。此步骤用来重新生成`pretrained/512_codiff_mask_text.ckpt`。
```bash
python main.py \
--logdir 'outputs/512_codiff_mask_text' \
--base 'configs/512_codiff_mask_text.yaml' \
-t --gpus 0,1,2,3,
```
## :fountain_pen: 引用
如果您发现我们的代码库对您的研究有用,请考虑引用我们的论文:
```bibtex
@InProceedings{huang2023collaborative,
author = {Huang, Ziqi and Chan, Kelvin C.K. and Jiang, Yuming and Liu, Ziwei},
title = {Collaborative Diffusion for Multi-Modal Face Generation and Editing},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year = {2023},
}
:purple_heart: 致谢
代码库由Ziqi Huang维护。
该项目构建在LDM的基础上。我们在CelebA-HQ,CelebA-Dialog,CelebAMask-HQ,和MM-CelebA-HQ-Dataset提供的数据上进行训练。我们还使用了Imagic implementation。











