
 访问官网
访问官网 Github
Github Huggingface
HuggingfaceComfyUI-AnimateAnyone-Evolved
改进的AnimateAnyone实现,允许你使用姿势图像序列和参考图像来生成风格化视频。
本项目当前的目标是在性能等于或优于RTX 3080的GPU上实现1+FPS的理想姿势到视频生成效果!🚀
当前支持
- 请查看**示例工作流程**了解使用方法。你可以使用测试输入来生成与我在此展示的完全相同的结果。(我从civitai获得了春丽的图像)
- 支持不同的采样器和调度器:
- DDIM
- 24帧姿势图像序列,
steps=20,context_frames=24;在RTX3080 GPU上生成需要835.67秒 - 24帧姿势图像序列,
steps=20,context_frames=12;在RTX3080 GPU上生成需要425.65秒
- 24帧姿势图像序列,
- DPM++ 2M Karras
- 24帧姿势图像序列,
steps=20,context_frames=12;在RTX3080 GPU上生成需要407.48秒
- 24帧姿势图像序列,
- LCM
- 24帧姿势图像序列,
steps=20,context_frames=24;在RTX3080 GPU上生成需要606.56秒 - 注意:
SD1.5的预训练LCM Lora在这里效果不佳,因为模型从SD1.5检查点经过了相当长的时间步骤重新训练,但重新训练一个新的lcm lora是可行的
- 24帧姿势图像序列,
- Euler
- 24帧姿势图像序列,
steps=20,context_frames=12;在RTX3080 GPU上生成需要450.66秒
- 24帧姿势图像序列,
- Euler Ancestral
- LMS
- PNDM
- DDIM
- 支持添加Lora
- 我这样做是为了插入lcm lora
- 支持相当长的姿势图像序列
- 在我的RTX3080 GPU上测试,可以处理120+帧的姿势图像序列,
context_frames=24 - 只要系统能够将所有姿势图像序列放入单个张量中而不会导致GPU内存泄漏,那么决定GPU使用率的主要参数就是
context_frames,它与姿势图像序列的长度无关。
- 在我的RTX3080 GPU上测试,可以处理120+帧的姿势图像序列,
- 当前实现采用自Moore-AnimateAnyone,
- 我尝试将其分解为尽可能多的模块,因此ComfyUI中的工作流程将与AnimateAnyone论文中的原始流程非常相似:
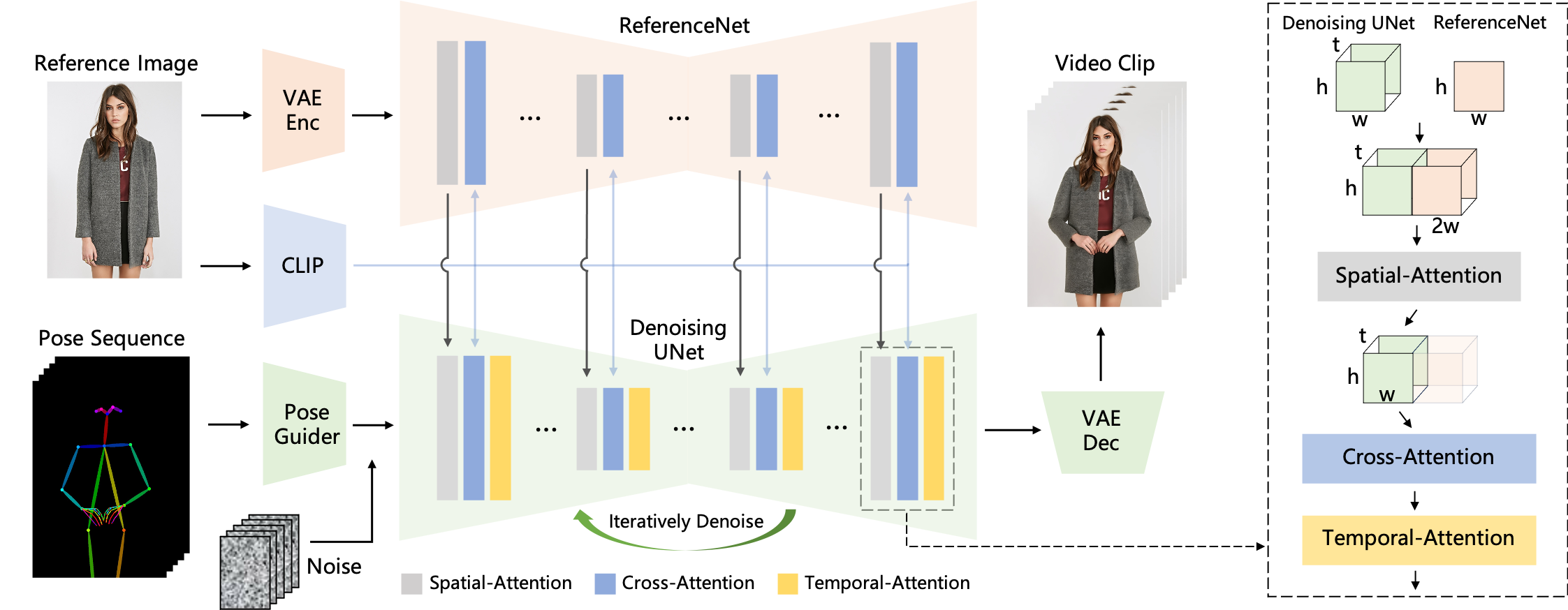
- 我尝试将其分解为尽可能多的模块,因此ComfyUI中的工作流程将与AnimateAnyone论文中的原始流程非常相似:
路线图
- 实现StreamDiffusion中提出的组件(残差CFG)(预计加速:2倍)
- 结果:
使用DDIM调度器和RCFG一起生成的结果不够好,尽管它将生成过程加速了约4倍。
在StreamDiffusion中,RCFG与LCM配合使用,这里可能也是这种情况,所以暂时将其保留在另一个分支中。
- 结果:
- 一旦Open-AnimateAnyone和AnimateAnyone发布,就整合它们的实现和预训练模型
- 使用stable-fast转换模型(预计加速:2倍)
- 为去噪unet训练LCM Lora(预计加速:5倍)
- 使用更好的数据集训练新模型以提高结果质量(可选,我们将看看是否有必要让我来做这个;)
- 持续研究,始终朝着更好更快的方向前进🚀
安装(你也可以使用ComfyUI管理器)
- 将此仓库克隆到
Your ComfyUI root directory\ComfyUI\custom_nodes\并安装依赖的Python包:cd Your_ComfyUI_root_directory\ComfyUI\custom_nodes\ git clone https://github.com/MrForExample/ComfyUI-AnimateAnyone-Evolved.git pip install -r requirements.txt # 如果你遇到关于diffusers的错误,请运行: pip install --force-reinstall diffusers>=0.26.1 - 下载预训练模型:
- stable-diffusion-v1-5_unet
- Moore-AnimateAnyone预训练模型
- 以上模型需要放在pretrained_weights文件夹下,如下所示:
./pretrained_weights/ |-- denoising_unet.pth |-- motion_module.pth |-- pose_guider.pth |-- reference_unet.pth `-- stable-diffusion-v1-5 |-- feature_extractor | `-- preprocessor_config.json |-- model_index.json |-- unet | |-- config.json | `-- diffusion_pytorch_model.bin `-- v1-inference.yaml- 下载clip图像编码器(例如sd-image-variations-diffusers)并将其放在
Your_ComfyUI_root_directory\ComfyUI\models\clip_vision下 - 下载vae(例如sd-vae-ft-mse)并将其放在
Your_ComfyUI_root_directory\ComfyUI\models\vae下











