
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文It seems that the images you uploaded are of an unsupported file type or corrupted, which is why they can't be displayed or analyzed directly. You might want to try converting them to a supported format like JPEG or PNG, or re-uploading them if they are already in these formats. If you need help with something else or have a different request, feel free to let me know! <SOURCE_TEXT>

|

|

|

|

|
| Landmark Control | ||||
引言
我们介绍了MOFA-Video,这是一种设计用来将不同领域的运动适应到冻结的视频扩散模型的方法。通过使用从稀疏到密集(S2D) 运动生成和基于流的运动适应,MOFA-Video可以有效地使用各种控制信号(包括轨迹、关键点序列及其组合)来动画化单个图像。
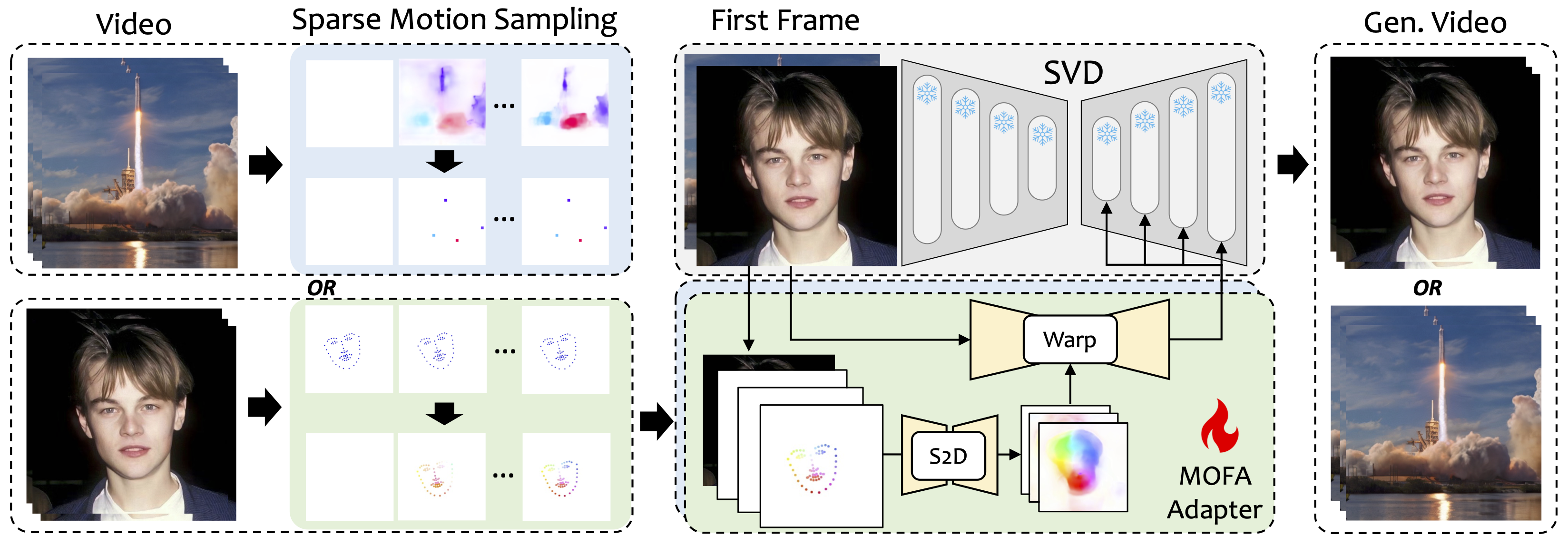
在训练阶段,我们通过稀疏运动采样生成稀疏控制信号,然后训练不同的MOFA-适配器通过预训练的SVD生成视频。在推理阶段,不同的MOFA-适配器可以组合在一起共同控制冻结的SVD。
🕹️ 使用混合控制的图像动画
1. 克隆仓库
git clone https://github.com/MyNiuuu/MOFA-Video.git
cd ./MOFA-Video
2. 环境设置
此演示已在CUDA 11.7版本上测试过。
cd ./MOFA-Video-Hybrid
conda create -n mofa python==3.10
conda activate mofa
pip install -r requirements.txt
pip install opencv-python-headless
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
重要: ⚠️⚠️⚠️ 在requirements.txt中严格遵循 4.5.0 版本的Gradio,因为其他版本可能会导致错误。
3. 下载检查点
-
从这里下载CMP的检查点并放入
./MOFA-Video-Hybrid/models/cmp/experiments/semiauto_annot/resnet50_vip+mpii_liteflow/checkpoints。 -
从huggingface仓库下载包含必要预训练检查点的
ckpts文件夹,并将其放在./MOFA-Video-Hybrid下。您可以使用git lfs下载整个ckpts文件夹:- 从https://git-lfs.github.com下载
git lfs。它通常用于从HuggingFace克隆具有大型模型检查点的仓库。 - 执行
git clone https://huggingface.co/MyNiuuu/MOFA-Video-Hybrid下载完整的HuggingFace仓库,目前仅包括ckpts文件夹。 - 将
ckpts文件夹复制或移动到GitHub仓库。
注意: 如果您在Linux上遇到
git: 'lfs' is not a git command错误,您可以尝试 这个解决方案,它在我的情况下效果很好。最后,检查点应该组织为
./MOFA-Video-Hybrid/ckpt_tree.md。 - 从https://git-lfs.github.com下载
4. 运行Gradio演示
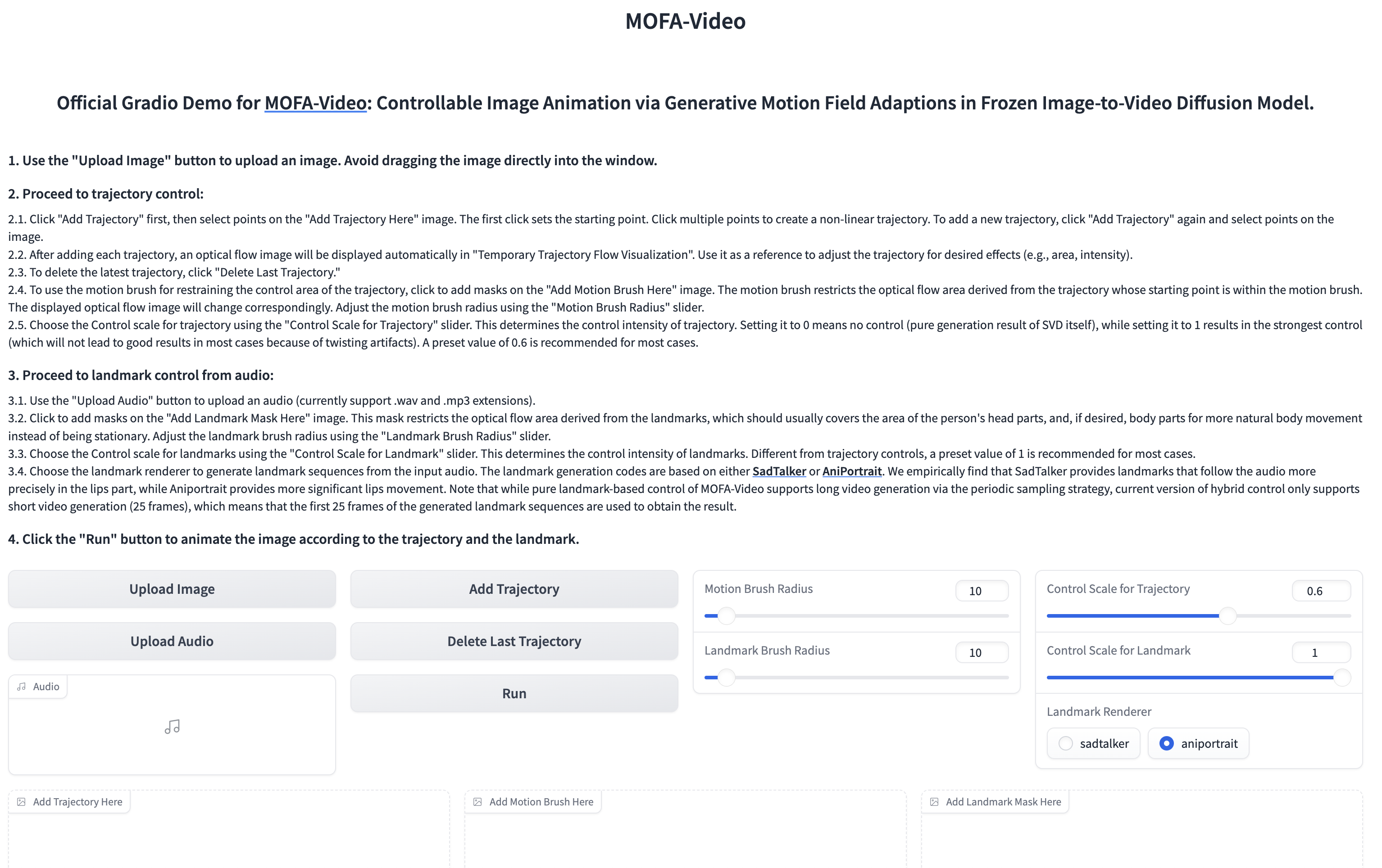
用音频动画化面部部分
cd ./MOFA-Video-Hybrid
python run_gradio_audio_driven.py
🪄🪄🪄 Gradio接口如下所示。请参照Gradio界面上的说明进行推理过程!
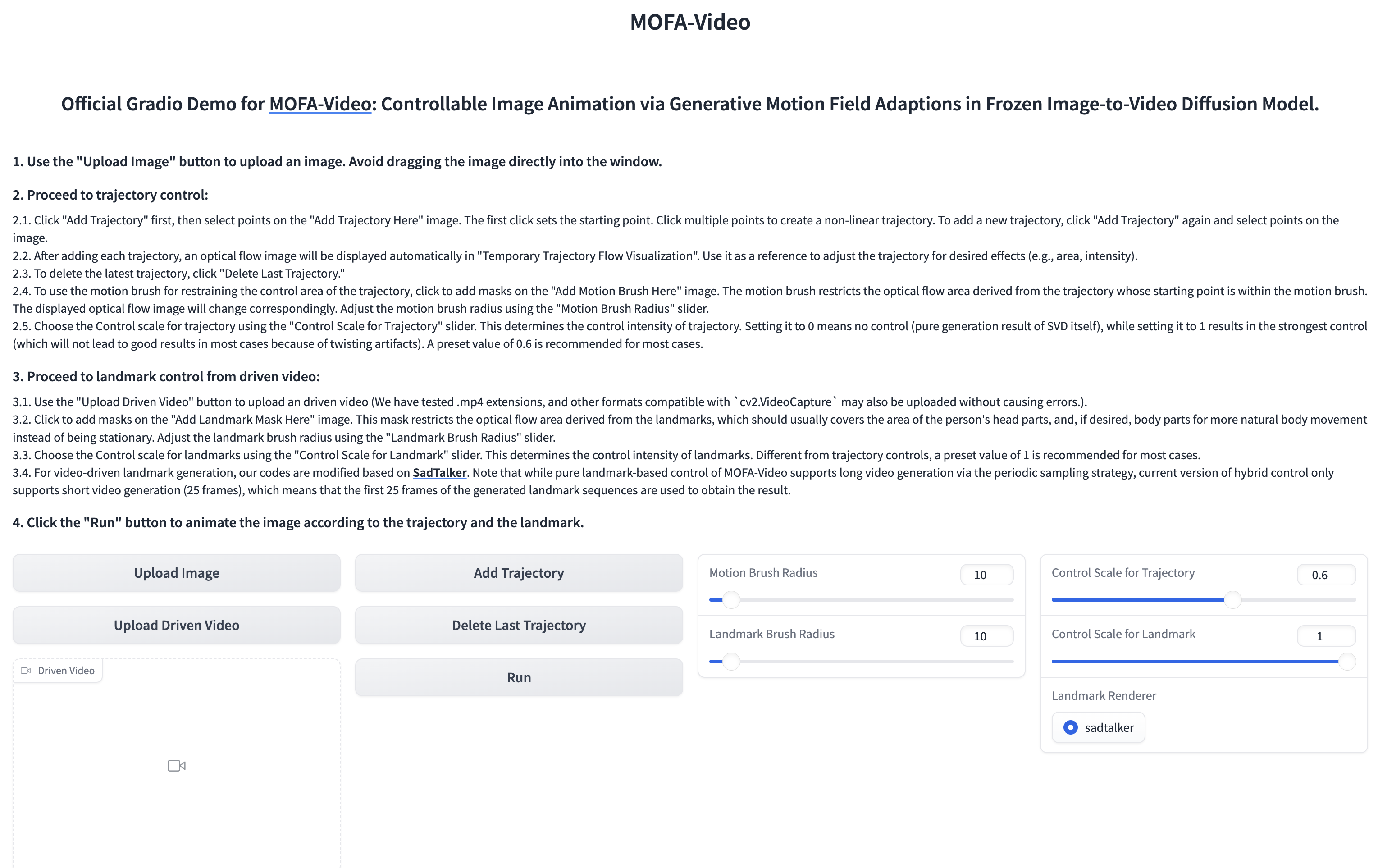
使用参考视频动画化面部部分
cd ./MOFA-Video-Hybrid
python run_gradio_video_driven.py
🪄🪄🪄 Gradio接口如下所示。请参照Gradio界面上的说明进行推理过程!
💫 基于轨迹的图像动画
请参见这里获取说明。
训练您自己的MOFA-适配器
请参见这里获取更多说明。
引用
@article{niu2024mofa,
title={MOFA-Video: Controllable Image Animation via Generative Motion Field Adaptions in Frozen Image-to-Video Diffusion Model},
author={Niu, Muyao and Cun, Xiaodong and Wang, Xintao and Zhang, Yong and Shan, Ying and Zheng, Yinqiang},
journal={arXiv preprint arXiv:2405.20222},
year={2024}
}
致谢
我们诚挚感谢以下项目的代码发布: DragNUWA, SadTalker, AniPortrait, Diffusers, SVD_Xtend, Conditional-Motion-Propagation, 以及 Unimatch. </SOURCE_TEXT>











