
 访问官网
访问官网 Github
GithubSensei 搜索
Sensei 搜索是一个由人工智能驱动的答案引擎。
🎥 演示
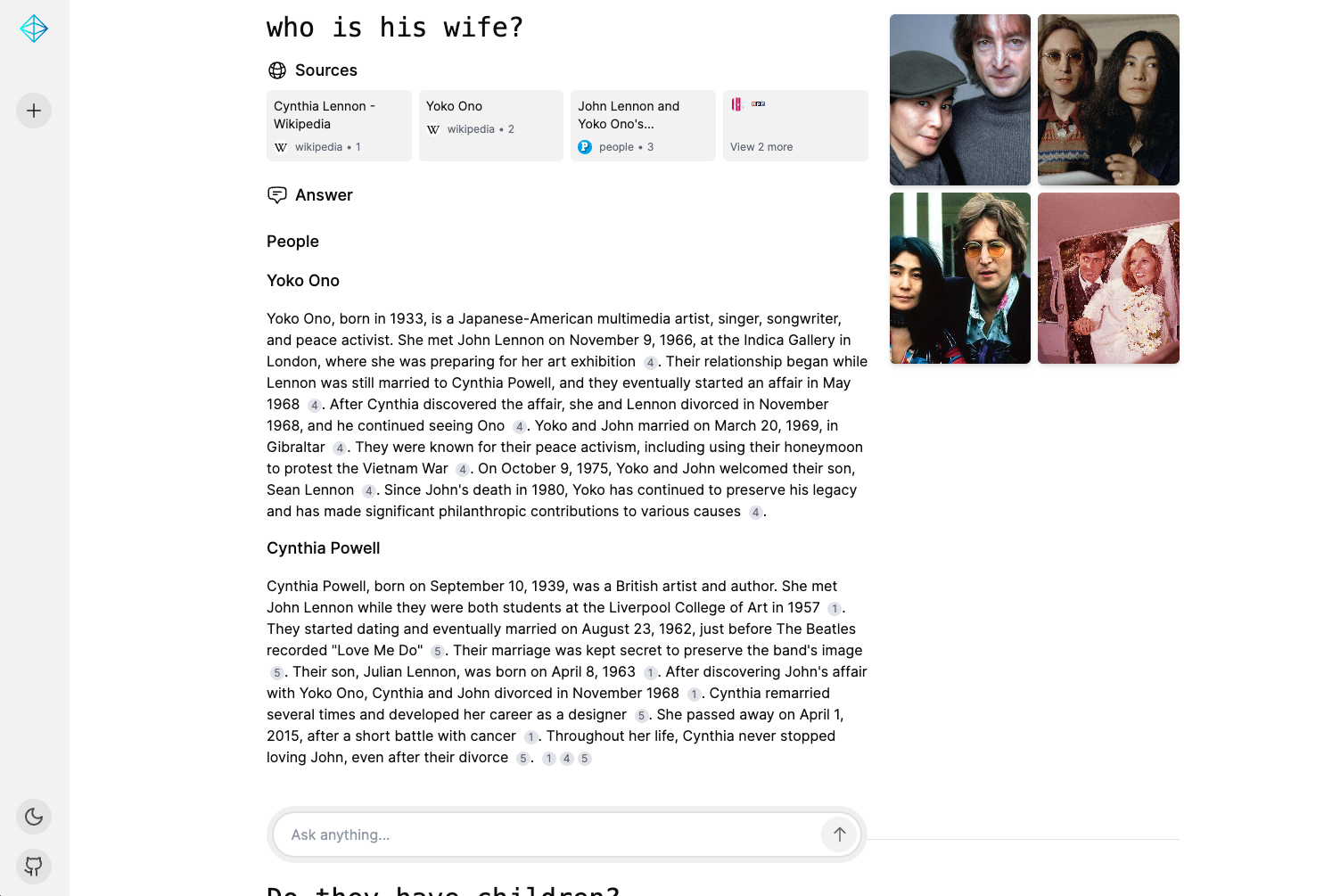
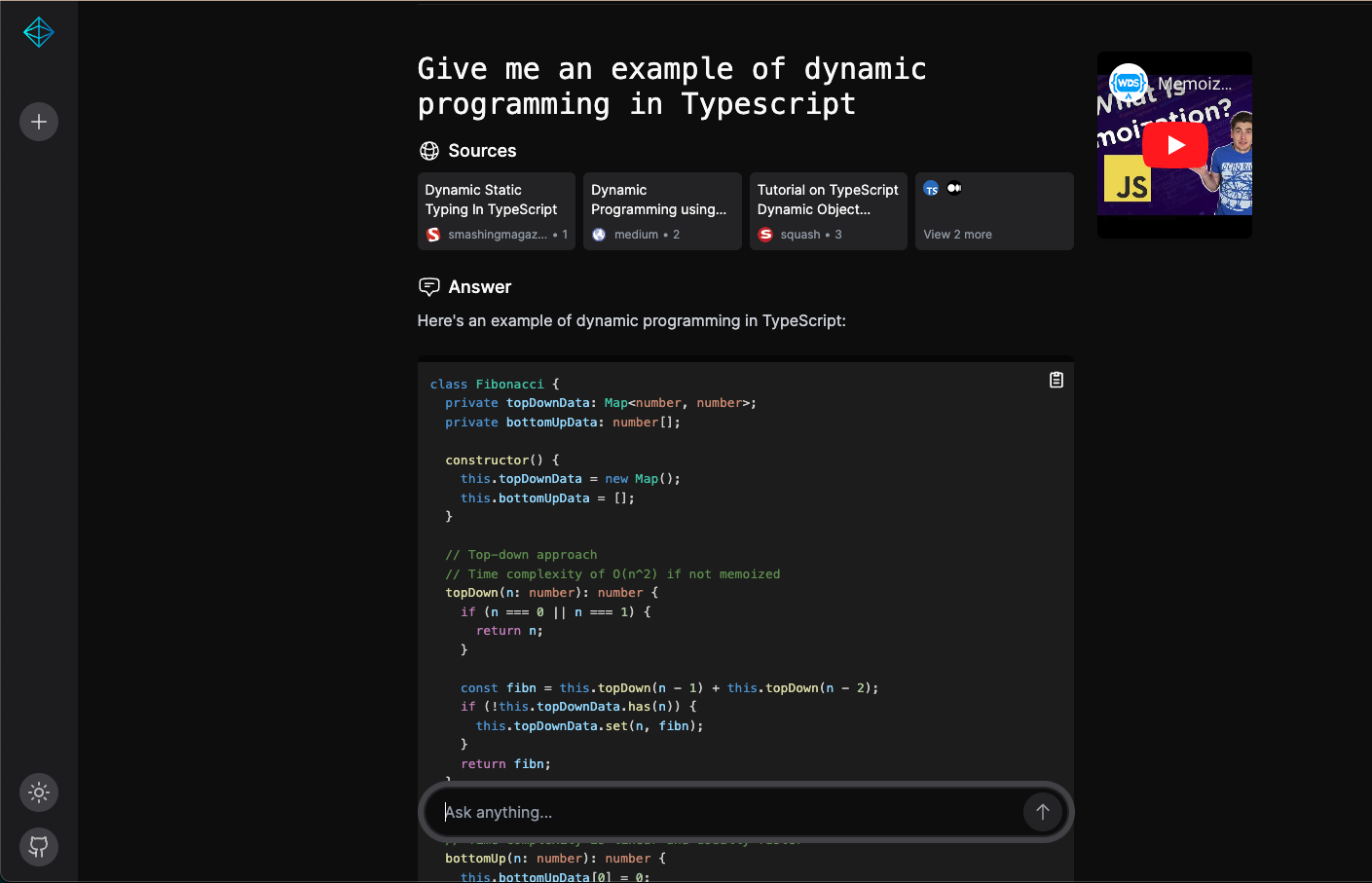
📸 截图
浅色模式
深色模式
💡 使用开源大语言模型的见解
使用开源大语言模型的主要经验和收获在一篇详细讨论中进行了总结。如需更多信息,可以阅读 Reddit 上的完整讨论:
🛠️ 技术栈
Sensei 搜索使用以下技术构建:
- 前端:Next.js、Tailwind CSS
- 后端:FastAPI、OpenAI 客户端
- 大语言模型:Command-R、Qwen-2-72b-instruct、WizardLM-2 8x22B、Claude Haiku、GPT-3.5-turbo
- 搜索:SearxNG、Bing
- 内存:Redis
- 部署:AWS、Paka
🏃♂️ 如何运行 Sensei 搜索
你可以在本地机器或云端运行 Sensei 搜索。
本地运行
按照以下步骤在本地运行 Sensei 搜索:
-
准备后端环境:
cd sensei_root_folder/backend/ mv .env.development.example .env.development根据需要编辑
.env.development。示例环境假设你通过 Ollama 运行模型。确保你有足够好的 GPU 来运行 command-r/Qwen-2-72b-instruct/WizardLM-2 8x22B 模型。 -
前端无需进行任何操作。
-
使用以下命令运行应用:
cd sensei_root_folder/ docker compose up -
打开浏览器,访问 http://localhost:3000
云端运行
我们使用 paka 将应用部署到 AWS。请注意,模型需要 GPU 实例才能运行。
开始之前,请确保你有:
- AWS 账户
- 在 AWS 账户中申请了 GPU 配额
集群配置位于 cluster.yaml 文件中。你需要将 cluster.yaml 中的 HF_TOKEN 值替换为你自己的 Hugging Face 令牌。这是必需的,因为 mistral-7b 和 command-r 模型要求你的账户已接受其使用条款和条件。
按照以下步骤在云端运行 Sensei 搜索:
-
安装 paka:
pip install paka -
在 AWS 中配置集群:
make provision-prod -
部署后端:
make deploy-backend -
部署前端:
make deploy-frontend -
获取前端 URL:
paka function list -
在浏览器中打开 URL。











