
 访问官网
访问官网 Github
Github 文档
文档 论文
论文
audioFlux






audioflux 是一个用于音频和音乐分析、特征提取的深度学习工具库。它支持数十种时频分析变换方法和数百种相应的时域和频域特征组合。可提供给深度学习网络进行训练,用于研究音频领域的各种任务,如分类、分离、音乐信息检索(MIR)和自动语音识别(ASR)等。
新功能
- v0.1.8
- 增加了多种音调算法:
YIN、CEP、PEF、NCF、HPS、LHS、STFT和FFP。 - 增加了
PitchShift和TimeStretch算法。
- 增加了多种音调算法:
目录
概述
audioFlux 基于数据流设计。它在结构上解耦了每个算法模块,可以快速高效地提取多维度特征。以下是主要特征架构图。
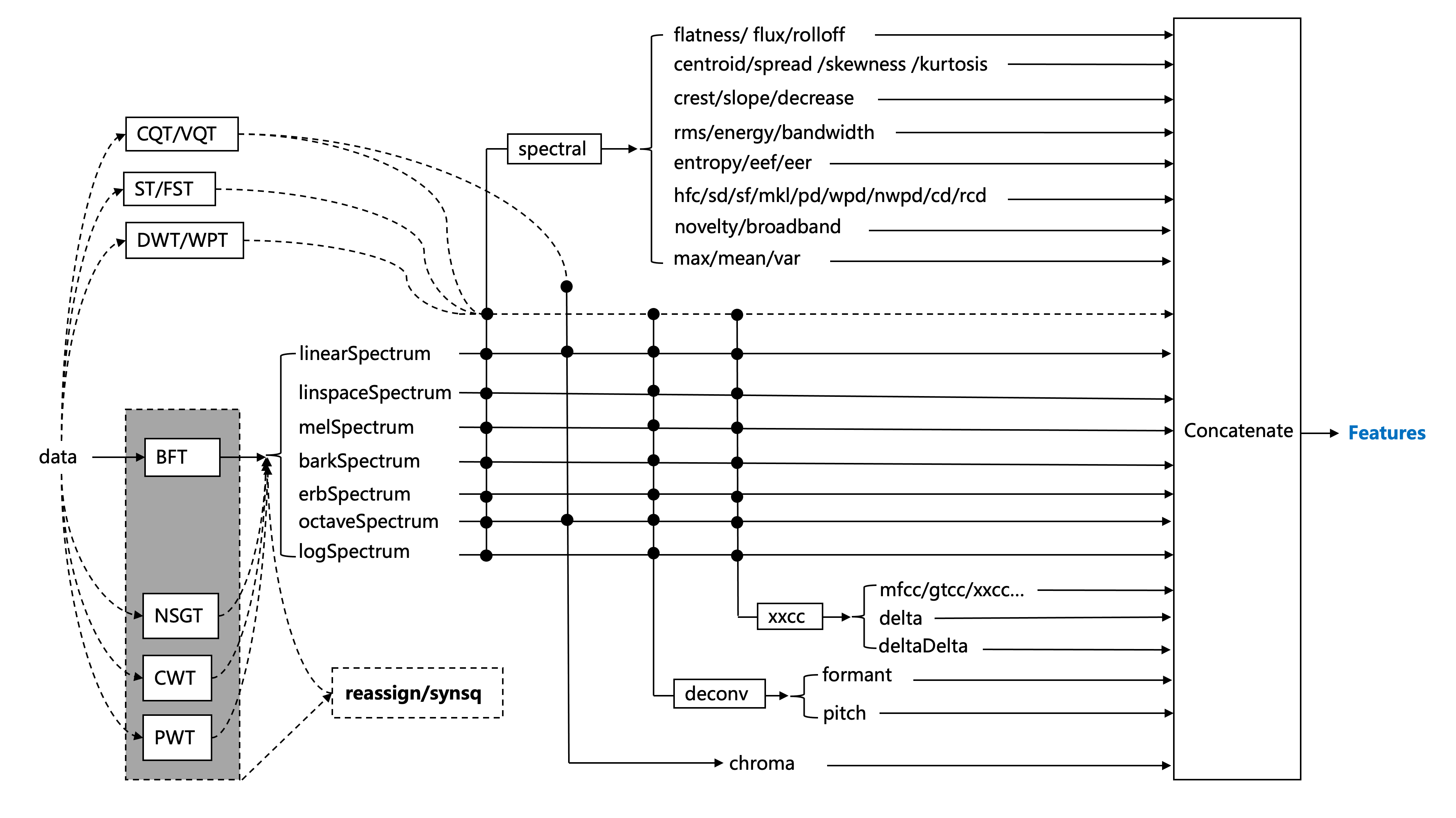
你可以使用多维特征组合,选择不同的深度学习网络进行训练,研究音频领域的各种任务,如分类、分离、MIR 等。
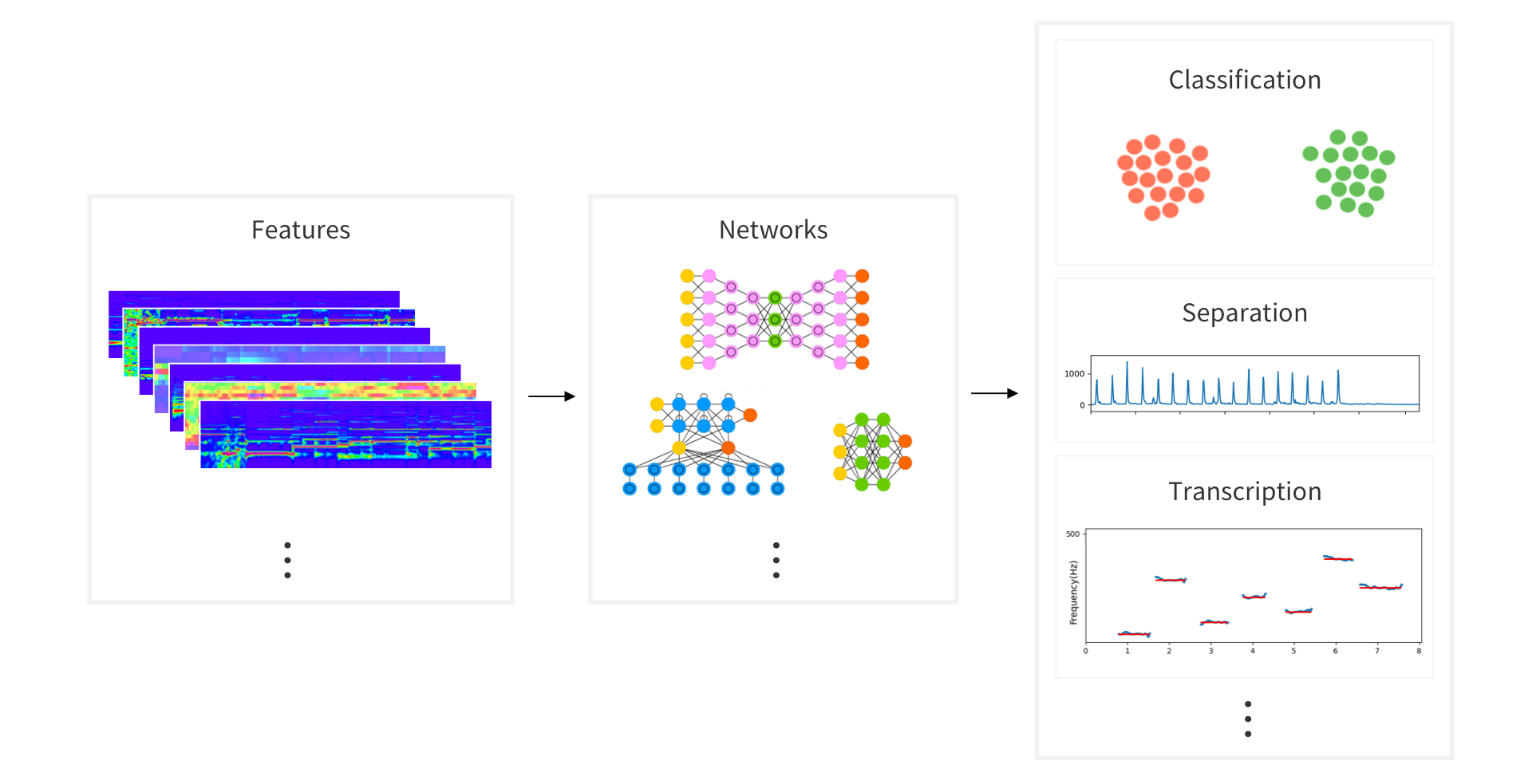
audioFlux 的主要功能包括 transform、feature 和 mir 模块。
1. 变换
在时频表示中,主要的变换算法有:
BFT- 基于傅里叶变换,类似短时傅里叶变换。NSGT- 非平稳Gabor变换。CWT- 连续小波变换。PWT- 伪小波变换。
上述变换支持以下所有频率比例类型:
- 线性 - 短时傅里叶变换光谱图。
- 等间隔 - 等间隔比例光谱图。
- Mel - Mel 频率比例光谱图。
- Bark - Bark 频率比例光谱图。
- Erb - Erb 频率比例光谱图。
- 八度 - 八度比例光谱图。
- 对数 - 对数比例光谱图。
以下变换不支持多种频率比例类型,只作为独立变换使用:
CQT- 恒定-Q变换。VQT- 可变-Q变换。ST- S-变换/Stockwell变换。FST- 快速S-变换。DWT- 离散小波变换。WPT- 小波包变换。SWT- 不平稳小波变换。
详细的变换功能、描述和使用请查看文档。
同步压缩 或 重分配 是一种用于锐化时频表示的技术,包含以下算法:
reassign- 对STFT进行重分配变换。synsq- 使用CWT数据进行重分配。wsst- 对CWT进行重分配变换。
2. 特征
特征模块包含以下算法:
spectral- 频谱特征,支持所有频谱类型。xxcc- 倒谱系数,支持所有频谱类型。deconv- 频谱反卷积,支持所有频谱类型。chroma- Chroma 特征,只支持CQT频谱,线性/八度频谱基于BFT。
3. MIR
MIR 模块包含以下算法:
pitch- YIN、STFT 等算法。onset- 频谱流,novelty 等算法。hpss- 中值滤波,NMF 算法。
安装

该库是跨平台的,目前支持 Linux、macOS、Windows、iOS 和 Android 系统。
Python 包安装
要安装 audioFlux 包,Python 版本需 >=3.6,使用已发布的 Python 包。
使用 PyPI:
$ pip install audioflux
使用 Anaconda:
$ conda install -c tanky25 -c conda-forge audioflux
其他构建
快速开始
更多示例脚本请参见 文档 部分。
基准测试
服务器硬件:
- CPU: AMD Ryzen Threadripper 3970X 32-Core Processor
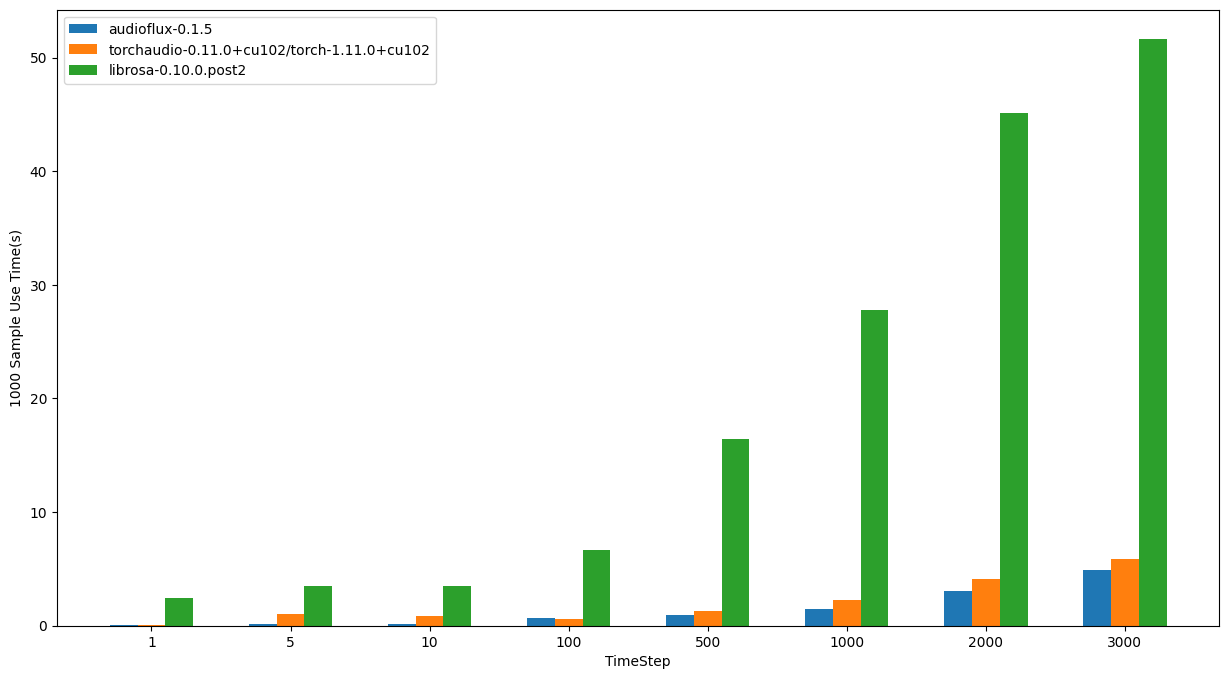
更详细的性能基准测试请参见 基准测试 模块。
文档
该包的文档可以在以下网址找到:
贡献
我们非常乐意与你合作并接受你对 audioFlux 的贡献。如果你想贡献,请派生最新的 Git 仓库并创建一个功能分支。发送的请求应通过所有持续集成测试。
你也非常欢迎提出任何改进建议,包括需求建议、发现错误、功能请求、一般问题、新算法等。 打开一个问题
引用
如果你想在学术作品中引用 audioflux,请使用以下方法:
-
如果你在工作中使用了该库,为了可重复性,请引用你使用的在 Zenodo 索引的版本:
许可证
audioFlux 项目使用 MIT 许可证。











