
 Github
Github 论文
论文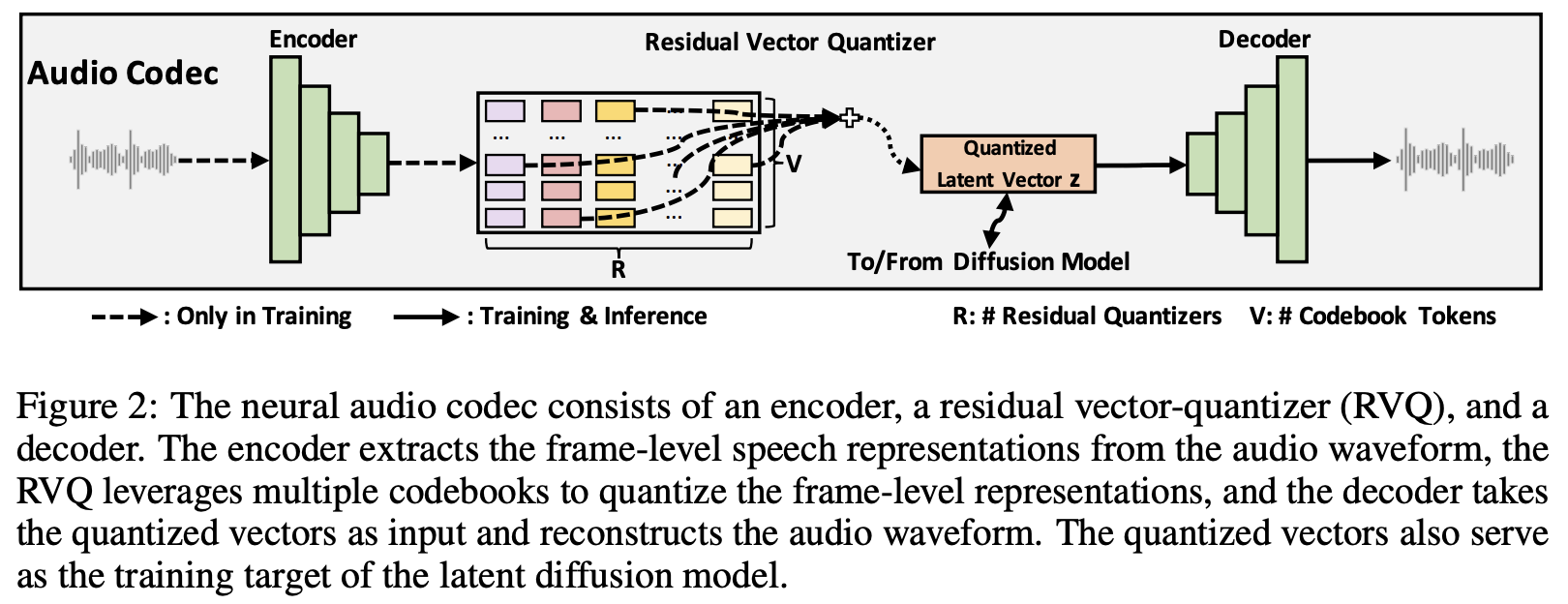
Natural Speech 2 - Pytorch(进行中)
在Pytorch中实现Natural Speech 2,零样本语音和歌唱合成器
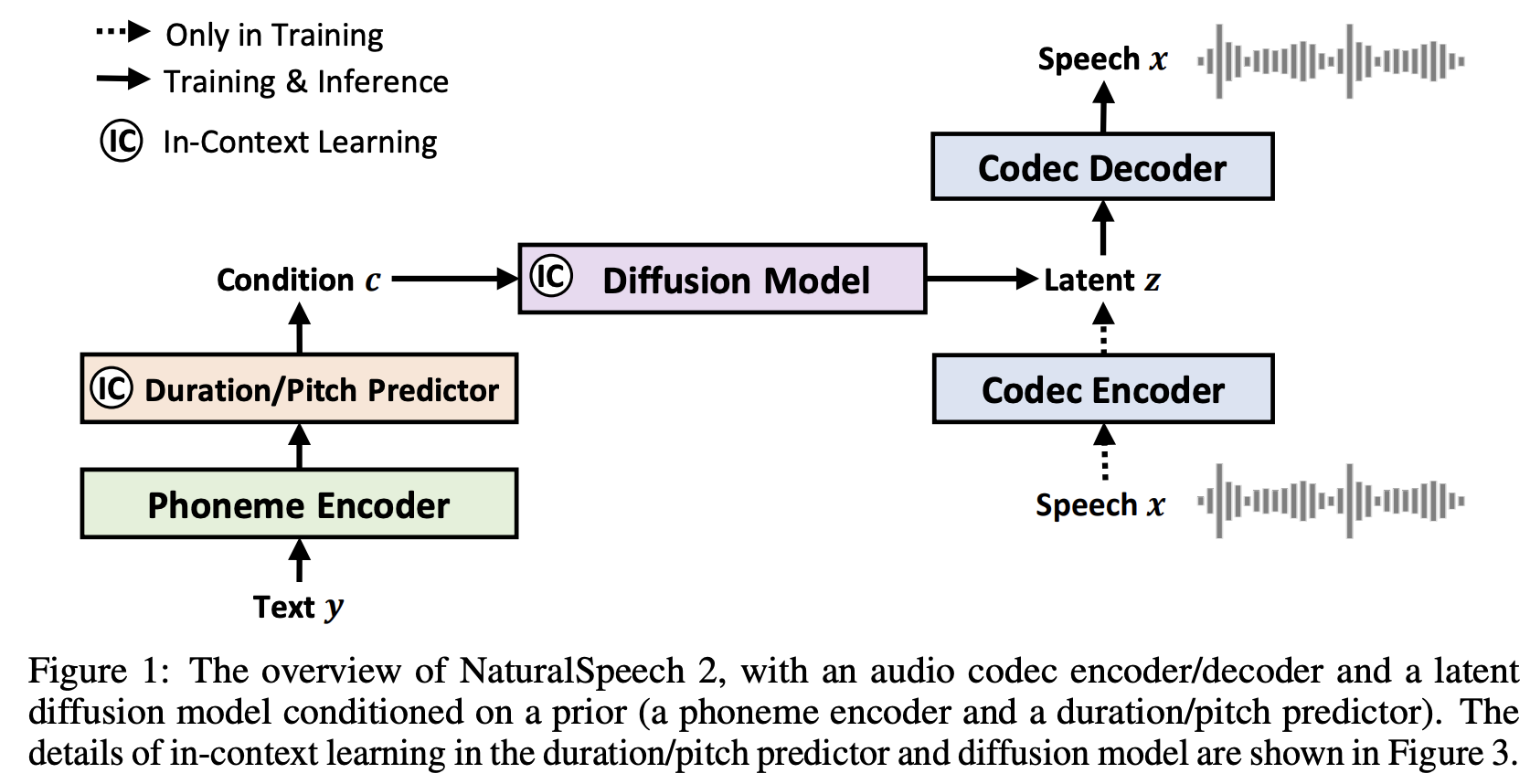
NaturalSpeech 2是一个TTS系统,它利用具有连续潜在向量的神经音频编解码器和具有非自回归生成的潜在扩散模型,实现自然和零样本文本到语音合成
本仓库将使用去噪扩散而非基于分数的SDE,并可能提供阐明版本。它还将在适用的情况下为注意力/transformer组件提供改进。
致谢
-
感谢Stability和🤗 Huggingface慷慨赞助,支持我们研究和开源前沿人工智能
-
感谢🤗 Huggingface提供了出色的accelerate库
-
感谢Manmay提交了音素、音高、持续时间和语音提示编码器的初始代码,以及多语言音素器和音素对齐器!
-
感谢Manmay完成了扩散网络的端到端条件控制连接!
-
你呢?如果你是一位有抱负的ML/AI工程师或从事TTS领域的工作,并希望为开源最先进的技术做出贡献,那就加入进来吧!
安装
$ pip install naturalspeech2-pytorch
使用方法
import torch
from naturalspeech2_pytorch import (
EncodecWrapper,
Model,
NaturalSpeech2
)
# 以encodec为例
codec = EncodecWrapper()
model = Model(
dim = 128,
depth = 6
)
# natural speech 扩散模型
diffusion = NaturalSpeech2(
model = model,
codec = codec,
timesteps = 1000
).cuda()
# 模拟原始音频数据
raw_audio = torch.randn(4, 327680).cuda()
loss = diffusion(raw_audio)
loss.backward()
# 对大量原始音频数据重复上述操作...
# 然后你可以从你的生成模型中采样,如下所示
generated_audio = diffusion.sample(length = 1024) # (1, 327680)
带条件控制的示例:
import torch
from naturalspeech2_pytorch import (
EncodecWrapper,
Model,
NaturalSpeech2,
SpeechPromptEncoder
)
# 以encodec为例
codec = EncodecWrapper()
model = Model(
dim = 128,
depth = 6,
dim_prompt = 512,
cond_drop_prob = 0.25, # 以此概率丢弃提示条件,用于无分类器引导
condition_on_prompt = True
)
# natural speech 扩散模型
diffusion = NaturalSpeech2(
model = model,
codec = codec,
timesteps = 1000
)
# 模拟原始音频数据
raw_audio = torch.randn(4, 327680)
prompt = torch.randn(4, 32768) # 他们在训练过程中随机截取了音频范围作为提示,最终会自动处理这个问题
text = torch.randint(0, 100, (4, 100))
text_lens = torch.tensor([100, 50 , 80, 100])
# 前向和后向传播
loss = diffusion(
audio = raw_audio,
text = text,
text_lens = text_lens,
prompt = prompt
)
loss.backward()
# 经过充分训练后
generated_audio = diffusion.sample(
length = 1024,
text = text,
prompt = prompt
) # (1, 327680)
或者,如果你想要一个Trainer类来处理训练和采样循环,只需简单地这样做:
from naturalspeech2_pytorch import Trainer
trainer = Trainer(
diffusion_model = diffusion, # 上面的扩散模型 + 编解码器
folder = '/path/to/speech',
train_batch_size = 16,
gradient_accumulate_every = 2,
)
trainer.train()
待办事项
-
完成感知器然后在ddpm侧进行交叉注意力条件控制
-
添加无分类器引导,即使论文中没有
-
完成训练期间的持续时间/音高预测 - 感谢Manmay
-
确保pyworld计算音高的方法也能工作
-
就pyworld的使用咨询TTS领域的博士生
-
如果可用,还提供使用spear-tts文本到语义模块的直接求和条件控制
-
在ddpm侧添加自条件控制
-
处理自动切片音频以获取提示,注意编解码器模型允许的最小音频段
-
确保curtail_from_left适用于encodec,弄清楚他们在做什么
引用
@inproceedings{Shen2023NaturalSpeech2L,
title = {NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers},
author = {Kai Shen and Zeqian Ju and Xu Tan and Yanqing Liu and Yichong Leng and Lei He and Tao Qin and Sheng Zhao and Jiang Bian},
year = {2023}
}
@misc{shazeer2020glu,
title = {GLU Variants Improve Transformer},
author = {Noam Shazeer},
year = {2020},
url = {https://arxiv.org/abs/2002.05202}
}
@inproceedings{dao2022flashattention,
title = {Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness},
author = {Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{\'e}, Christopher},
booktitle = {Advances in Neural Information Processing Systems},
year = {2022}
}
@article{Salimans2022ProgressiveDF,
title = {Progressive Distillation for Fast Sampling of Diffusion Models},
author = {Tim Salimans and Jonathan Ho},
journal = {ArXiv},
year = {2022},
volume = {abs/2202.00512}
}
@inproceedings{Hang2023EfficientDT,
title = {Efficient Diffusion Training via Min-SNR Weighting Strategy},
author = {Tiankai Hang and Shuyang Gu and Chen Li and Jianmin Bao and Dong Chen and Han Hu and Xin Geng and Baining Guo},
year = {2023}
}
@article{Alayrac2022FlamingoAV,
title = {Flamingo: a Visual Language Model for Few-Shot Learning},
author = {Jean-Baptiste Alayrac and Jeff Donahue and Pauline Luc and Antoine Miech and Iain Barr and Yana Hasson and Karel Lenc and Arthur Mensch and Katie Millican and Malcolm Reynolds and Roman Ring and Eliza Rutherford and Serkan Cabi and Tengda Han and Zhitao Gong and Sina Samangooei and Marianne Monteiro and Jacob Menick and Sebastian Borgeaud and Andy Brock and Aida Nematzadeh and Sahand Sharifzadeh and Mikolaj Binkowski and Ricardo Barreira and Oriol Vinyals and Andrew Zisserman and Karen Simonyan},
journal = {ArXiv},
year = {2022},
volume = {abs/2204.14198}
}
@article{Badlani2021OneTA,
title = {One TTS Alignment to Rule Them All},
author = {Rohan Badlani and Adrian Lancucki and Kevin J. Shih and Rafael Valle and Wei Ping and Bryan Catanzaro},
journal = {ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
year = {2021},
pages = {6092-6096},
url = {https://api.semanticscholar.org/CorpusID:237277973}
}











