
 Github
Github Huggingface
Huggingface 论文
论文🚀 基于txtai的RAG



这个项目是一个基于txtai的检索增强生成(RAG)Streamlit应用程序。
检索增强生成(RAG)通过限制大语言模型(LLM)生成答案的上下文来帮助生成事实准确的内容。这通常通过搜索查询来实现,该查询用相关上下文填充提示。
这个应用程序支持两类RAG。
- 向量RAG:通过向量搜索查询提供上下文
- 图RAG:通过图路径遍历查询提供上下文
快速开始
运行这个应用程序的两种主要方式是使用Docker容器和Python虚拟环境。推荐使用Docker运行,至少可以了解应用程序的功能。
Docker
neuml/rag在Docker Hub上可用:
可以使用默认设置运行,如下所示。
docker run -d --gpus=all -it -p 8501:8501 neuml/rag
Python虚拟环境
也可以直接安装和运行应用程序。建议在Python虚拟环境中运行。
pip install -r requirements.txt
启动应用程序。
streamlit run rag.py
演示
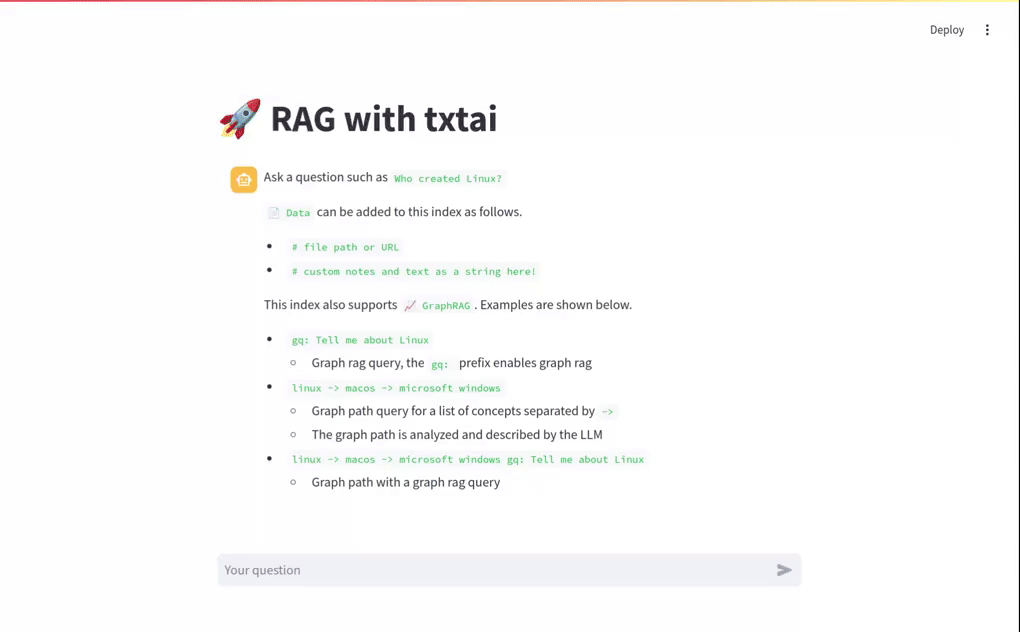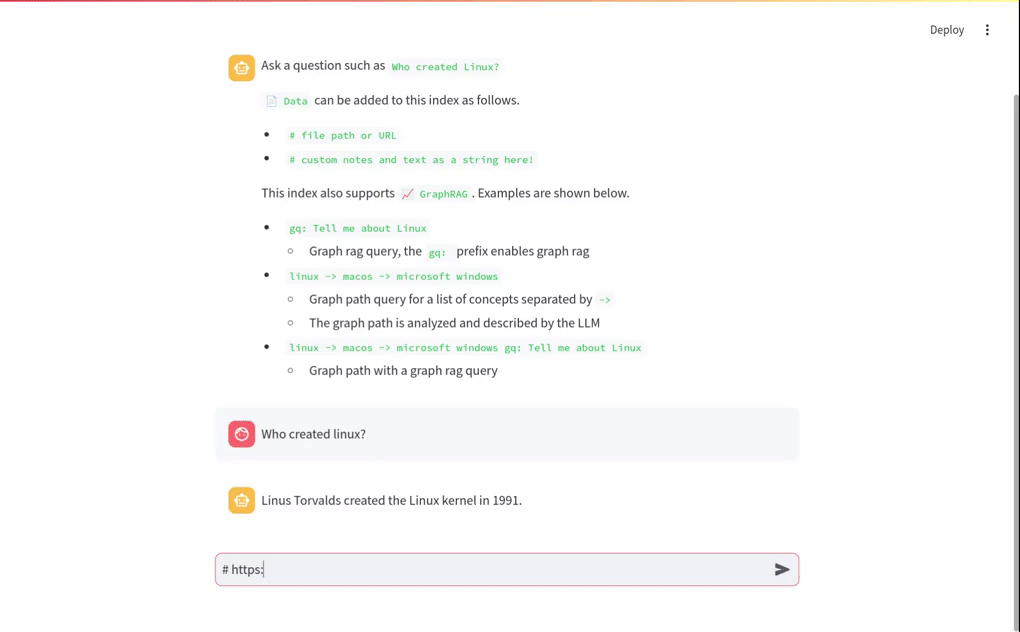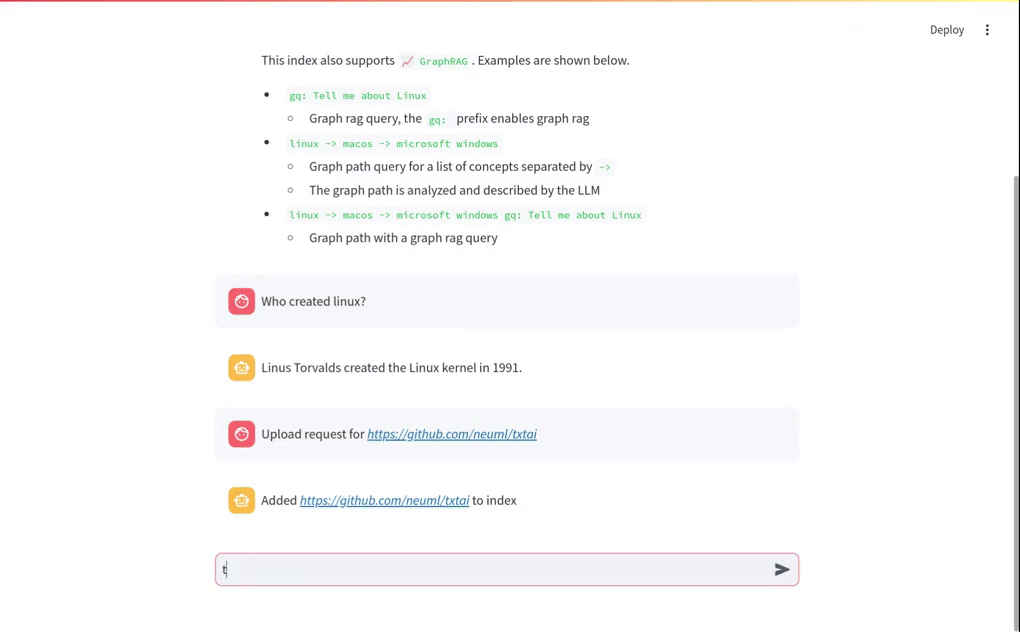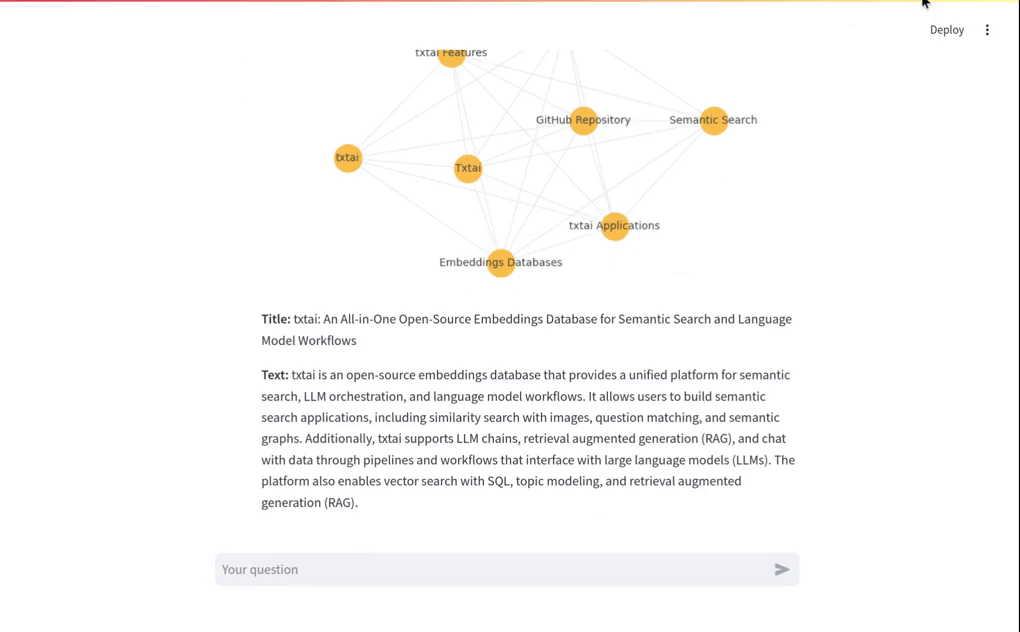
上面的短视频片段简要概述了这个RAG系统。它展示了一个基本的向量RAG查询。它还展示了一个带有上传数据的图RAG查询。以下部分将详细介绍这些概念。
RAG
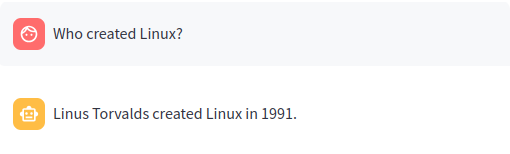
传统RAG或向量RAG运行向量搜索以找到与用户输入最相关的前N个匹配项。这些匹配项被传递给LLM,然后返回答案。
查询"谁创造了Linux?"在嵌入索引中运行向量搜索以找到最佳匹配的文档。然后将这些匹配项放入LLM提示中。执行LLM提示并返回答案。
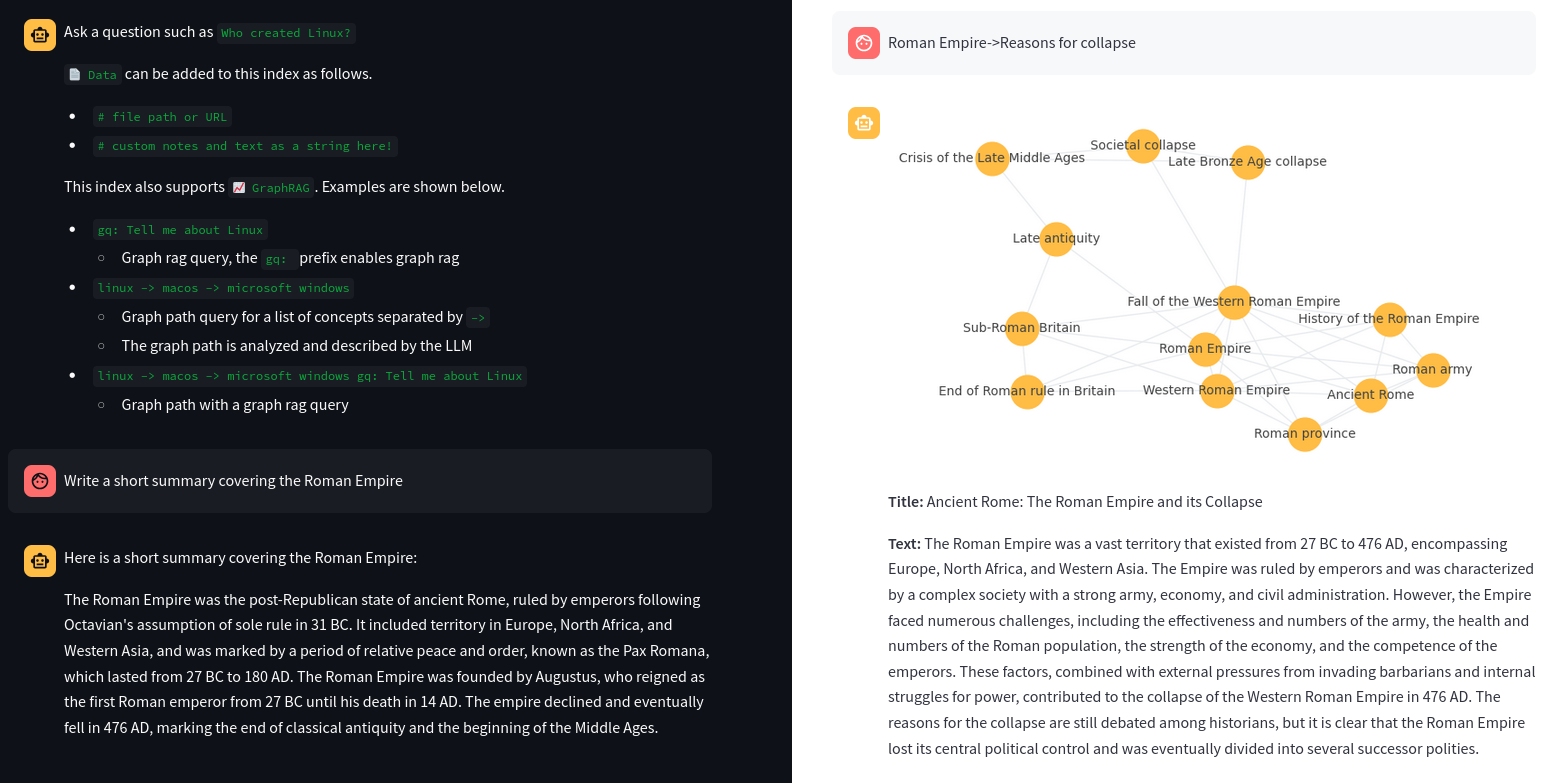
图RAG
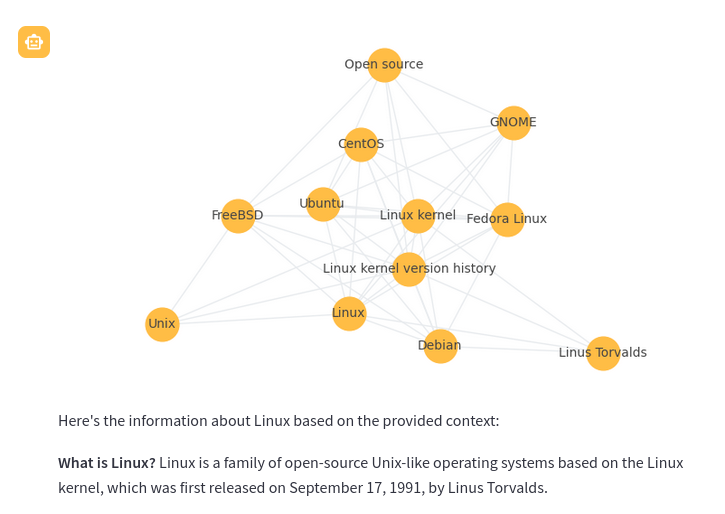
图RAG是一种使用知识或语义图来生成上下文的新方法。它不是进行向量搜索,而是运行图路径查询。在此应用程序中,图RAG支持以下方法来生成上下文。
-
带有
gq:前缀的图查询。这是一种图查询扩展形式。它首先进行向量搜索以找到前n个结果。然后使用存储在向量数据库旁边的图网络扩展这些结果。gq: 告诉我关于Linux的信息
-
图路径查询。此查询接受一系列概念,并找到与这些概念最接近的节点。然后运行图路径遍历以构建与这些概念相关的节点上下文。这个遍历的结果作为上下文传递给LLM。
linux -> macos -> microsoft windows
-
两者的组合。这首先运行图路径查询,然后仅在该路径遍历的上下文中运行图查询。
linux -> macos -> microsoft windows gq: 告诉我关于Linux的信息
每个图RAG查询响应还将显示相应的图,以帮助理解查询的工作原理。图中的每个节点都是一个部分(段落)。节点标签是在上传时通过LLM提示生成的主题标签。
向索引添加数据
无论RAG应用程序是新的嵌入索引还是现有的索引,都可以添加额外的数据。
可以按以下方式添加数据。
| 方法 | |
|---|---|
# 文件路径或URL | 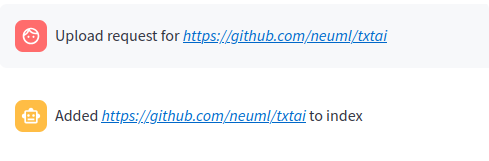 |
# 这里是自定义注释和文本作为字符串! |  |
当查询以#开头时,RAG应用程序会读取URL或文件,并将其加载到索引中。这种方法还支持将文本直接加载到索引中。例如,# txtai是一个全能的嵌入数据库会在嵌入数据库中创建一个新条目。
配置参数
RAG应用程序有多个环境变量可以设置,用于控制应用程序的行为。
| 变量 | 描述 | 默认值 |
|---|---|---|
| TITLE | 应用程序的主标题 | 🚀 基于txtai的RAG |
| LLM | LLM路径 | x86-64: Mistral-7B-OpenOrca-AWQ |
| arm64 : Mistral-7B-OpenOrca-GGUF | ||
| EMBEDDINGS | 嵌入数据库路径 | neuml/txtai-wikipedia-slim |
| MAXLENGTH | 最大生成长度 | 主题为2048,RAG为4096 |
| CONTEXT | RAG上下文大小 | 10 |
| DATA | 可选的索引数据目录 | 无 |
| PERSIST | 可选的保存索引更新目录 | 无 |
| TOPICSBATCH | 可选的LLM主题查询批处理大小 | 无 |
注意:AWQ模型仅支持x86-64机器
在应用程序中,可以通过输入:settings显示这些设置。
以下是使用Docker容器设置这些配置的示例。在Python虚拟环境中运行时,只需将这些设置为环境变量即可。
Llama 3.1 8B
docker run -d --gpus=all -it -p 8501:8501 -e LLM=hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4 neuml/rag
通过Ollama使用Llama 3.1 8B
docker run -d --gpus=all -it -p 8501:8501 --add-host=host.docker.internal:host-gateway \
-e LLM=ollama/llama3.1:8b-instruct-q4_K_M -e OLLAMA_API_BASE=http://host.docker.internal:11434 \
neuml/rag
GPT-4o
docker run -d --gpus=all -it -p 8501:8501 -e LLM=gpt-4o -e OPENAI_API_KEY=your-api-key neuml/rag
使用另一个嵌入索引运行
docker run -d --gpus=all -it -p 8501:8501 -e EMBEDDINGS=neuml/arxiv neuml/rag
使用本地文件目录构建嵌入索引
docker run -d --gpus=all -it -p 8501:8501 -e DATA=/data/path -v local/path:/data/path neuml/rag
持久化嵌入和缓存模型
docker run -d --gpus=all -it -p 8501:8501 -e DATA=/data/path -e EMBEDDINGS=/data/embeddings \
-e PERSIST=/data/embeddings -e HF_HOME=/data/modelcache -v localdata:/data neuml/rag











