
 访问官网
访问官网 Github
Github 文档
文档使用LLM "训练" Python代码
问题
我想到一个有趣的想法:让LLM能够遍历我所有的邮件,通过提取航班行程中的目的地来告诉我我去过世界上的哪些地方。
设置:连接到Gmail
LlamaHub有一个供代理使用的Gmail工具。这是我首先尝试的地方。不过,你需要先完成与Google的身份验证流程。以下是我的操作步骤:
- 在Google Cloud Console中创建一个新项目
- 进入APIs & Services -> Library,搜索Gmail并启用该API
- 进入APIs & Services -> Credentials,创建一个新的OAuth客户端ID
- 应用类型:Web应用
- 授权重定向URI:http://localhost:8080/(最后的斜杠似乎很重要)
- 进入APIs & Services -> OAuth consent screen,将应用设置为外部应用,这样我就可以将个人Gmail连接到它,前提是我将其明确添加为允许的测试用户
- 下载凭证JSON文件并将其保存为项目根目录下的
credentials.json
不幸的是,Gmail工具没有翻页浏览大量结果的方法,所以我复制并修改了它,你可以在gmail.py中找到。
第一次尝试:让LLM对每封邮件进行分类
在summarize.py中,你可以看到我的第一次尝试。我遍历了每一条匹配"你的航班行程"的搜索结果,并尝试让LLM对其进行分类,每次都输出JSON。这确实有效!但是非常慢,而且消耗了大量的token——可能会变得很昂贵!
第二次尝试:让LLM生成邮件分类脚本
在generate.py中,你可以看到我的第二个解决方案:我不是对每封邮件运行LLM,而是让它处理一部分邮件。对于每封邮件,我给它邮件正文以及一个Python函数,该函数的目的是检测邮件正文是否为行程(一开始只是一个空字符串)。
如果LLM认为这封邮件是行程,它会被指示修改Python函数,使得该邮件能被检测到。它还被指示确保之前的邮件仍然能被检测到。因此,它不断迭代,每次都生成一个越来越复杂的Python函数,可以检测更多的行程。这个过程如下:
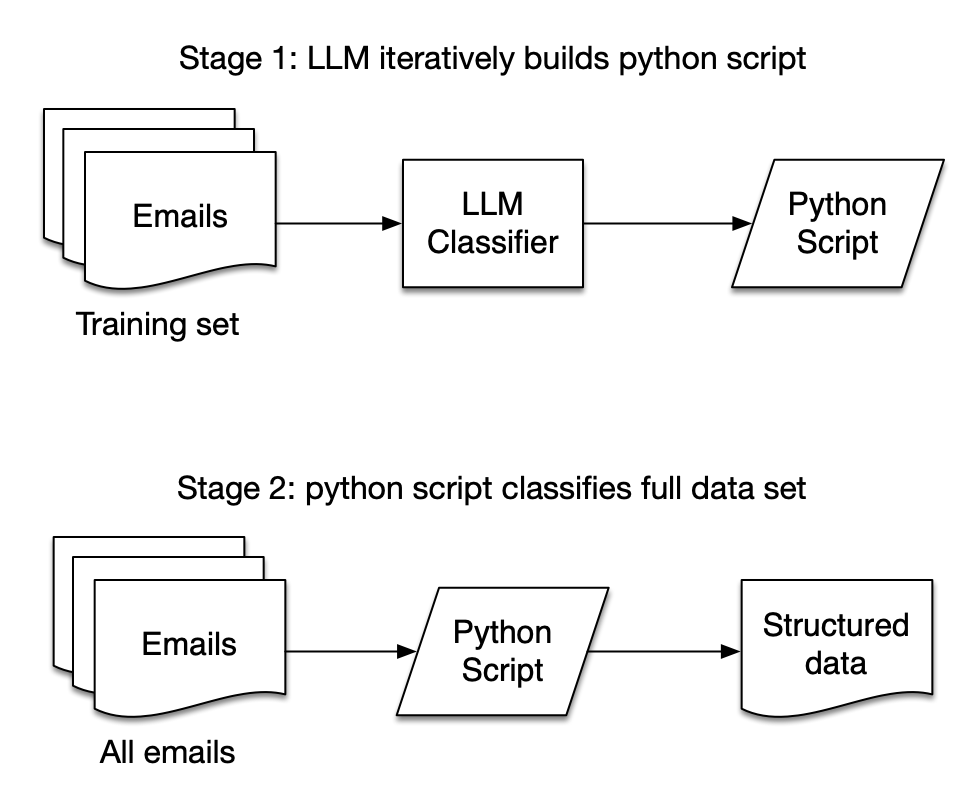
在sample_generated_code.py中,你可以看到在处理了大约100封邮件后的输出结果,其中并非所有邮件都是实际的行程(很多来自航空公司的垃圾邮件也匹配搜索条件)。你可以看到它正在慢慢迭代,为每个单独的航空公司创建一个检测块,这正是我作为人类可能会想到的方法,但需要更多的调整。
进一步工作
我想到了一些下一步可以做的事情:
- 改进搜索字符串以排除更多垃圾邮件,这样它就能训练更多实际的行程(现在它正在读取很多垃圾邮件)
- 使用本地模型来节省费用(我一直在关注Mistral的最新模型
codestral。Meta的llama3无法完成这项任务。) - 在提示中明确包含合并检测块的指令。这看起来很复杂!不确定它是否能做到。











