
 Github
Github 论文
论文多跳知识图谱推理与奖励塑造
这是以下论文的官方代码发布:
Xi Victoria Lin, Richard Socher 和 Caiming Xiong。多跳知识图谱推理与奖励塑造。EMNLP 2018。
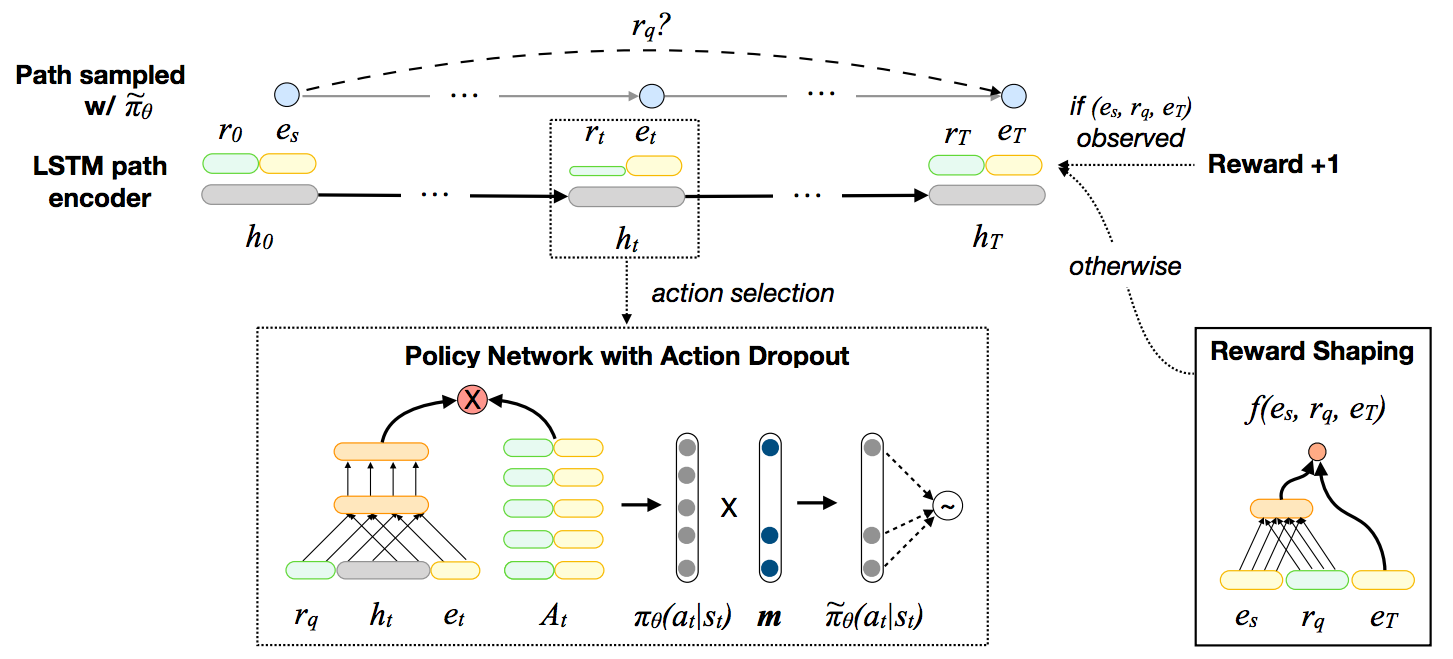
快速开始
环境变量和依赖项
使用 Docker
构建 Docker 镜像
docker build -< Dockerfile -t multi_hop_kg:v1.0
启动 Docker 容器并在其中运行实验。
nvidia-docker run -v `pwd`:/workspace/MultiHopKG -it multi_hop_kg:v1.0
本文档的其余部分假设在容器内交互式工作。如果您更喜欢在容器外运行实验,请相应地更改命令。
手动设置
或者,您可以手动安装 Pytorch(>=0.4.1)并使用 Makefile 设置其余依赖项。
make setup
处理数据
首先,解压数据文件
tar xvzf data-release.tgz
然后运行以下命令预处理数据集。
./experiment.sh configs/<dataset>.sh --process_data <gpu-ID>
<dataset> 是 ./data 目录中任何数据集文件夹的名称。在我们的实验中,使用了五个数据集:umls、kinship、fb15k-237、wn18rr 和 nell-995。
<gpu-ID> 是表示 GPU 索引的非负整数。
训练模型
然后可以使用以下命令来训练论文中提出的模型和基线。默认情况下,训练结束时将打印开发集评估结果。
- 训练基于嵌入的模型
./experiment-emb.sh configs/<dataset>-<emb_model>.sh --train <gpu-ID>
实现了以下基于嵌入的模型:distmult、complex 和 conve。
- 训练强化学习模型(策略梯度)
./experiment.sh configs/<dataset>.sh --train <gpu-ID>
- 训练强化学习模型(策略梯度 + 奖励塑造)
./experiment-rs.sh configs/<dataset>-rs.sh --train <gpu-ID>
- 注意:要使用奖励塑造训练强化学习模型,请确保 1)您已预训练基于嵌入的模型,2)正确设置了指向预训练基于嵌入模型的文件路径指针(示例配置文件)。
评估预训练模型
要生成预训练模型的评估结果,只需将上述命令中的 --train 标志更改为 --inference。
例如,以下命令使用强化学习模型(策略梯度 + 奖励塑造)进行推理,并打印评估结果(在开发集和测试集上)。
./experiment-rs.sh configs/<dataset>-rs.sh --inference <gpu-ID>
要打印推理过程中由波束搜索生成的推理路径,请使用 --save_beam_search_paths 标志:
./experiment-rs.sh configs/<dataset>-rs.sh --inference <gpu-ID> --save_beam_search_paths
-
NELL-995 数据集注意事项:
对于这个数据集,我们将原始训练数据分为
train.triples和dev.triples,最终要测试的模型必须使用这两个文件组合进行训练。- 要获得正确的测试集结果,您需要在所有数据预处理、训练和推理命令中添加
--test标志。
# 您可能需要根据开发集的表现调整训练轮数。 ./experiment.sh configs/nell-995.sh --process_data <gpu-ID> --test ./experiment-emb.sh configs/nell-995-conve.sh --train <gpu-ID> --test ./experiment-rs.sh configs/NELL-995-rs.sh --train <gpu-ID> --test ./experiment-rs.sh configs/NELL-995-rs.sh --inference <gpu-ID> --test- 在开发过程中不要使用
--test标志。
- 要获得正确的测试集结果,您需要在所有数据预处理、训练和推理命令中添加
更改超参数
要更改超参数和其他实验设置,请从配置文件开始。
更多实现细节
我们在实验中使用小批量训练。为了减少填充量(这可能会导致内存问题并降低包含大扇出节点的知识图谱的计算速度), 我们根据不同节点动作空间的大小将它们分组到桶中。桶实现的描述可以在 这里和 这里找到。
引用
如果您发现本仓库中的资源有帮助,请引用
@inproceedings{LinRX2018:MultiHopKG,
author = {Xi Victoria Lin and Richard Socher and Caiming Xiong},
title = {Multi-Hop Knowledge Graph Reasoning with Reward Shaping},
booktitle = {Proceedings of the 2018 Conference on Empirical Methods in Natural
Language Processing, {EMNLP} 2018, Brussels, Belgium, October
31-November 4, 2018},
year = {2018}
}











