
 访问官网
访问官网 Github
Github 论文
论文

一个多智能体强化学习环境


[!注意] RWARE环境已更新,以支持新的Gymnasium接口,取代了已弃用的
gym=0.21依赖(非常感谢@LukasSchaefer)。关于向后兼容性,请参阅Gymnasium兼容性文档或使用仓库的v1.0.3版本。接口的主要变化如下:
obss = env.reset()-->obss, info = env.reset()obss, rewards, dones, info = env.step(actions)-->obss, rewards, done, truncated, info = env.step(actions)done作为单个布尔值给出,而不是每个智能体一个bool值- 你可以通过
obss, info = env.reset(seed=42)给重置函数一个特定的种子,以初始化特定的回合。
目录
环境描述
多机器人仓库(RWARE)环境模拟了一个有机器人移动和递送请求商品的仓库。这个模拟器的灵感来自现实世界的应用,其中机器人拾取货架并将它们送到工作站。人类访问货架的内容,然后机器人可以将它们返回到空的货架位置。
该环境是可配置的:它允许不同的大小(难度)、智能体数量、通信能力和奖励设置(合作/个人)。当然,每个实验中使用的参数必须清楚地报告,以允许算法之间进行公平比较。
它看起来是什么样的?
以下是一个小型(10x20)仓库的四个经过训练的智能体的图示。智能体已经使用SEAC算法[2]进行了训练。可以使用env.render()函数实现这种可视化,稍后将对此进行描述。
动作空间
在这个模拟中,机器人有以下离散动作空间:
A={向左转,向右转,前进,装载/卸载货架}
前三个动作只允许每个机器人旋转和向前移动。装载/卸载只在智能体位于预定位置的货架下方时才有效。
观察空间
智能体的观察是部分可观察的,由以智能体为中心的3x3(可配置)方格组成。在这个有限的网格内,所有实体都是可观察的:
- 位置、旋转以及智能体是否携带货架。
- 其他机器人的位置和旋转。
- 货架以及它们当前是否在请求队列中。
动态:碰撞
环境的动态特性也特别有趣。就像真实的三维仓库一样,机器人可以在货架下移动。当然,当机器人装载时,它们必须使用走廊,避开任何静止的货架。
任何碰撞都以允许最大移动性的方式解决。当两个或更多智能体试图移动到同一位置时,我们优先考虑那个也阻挡了其他智能体的智能体。否则,选择是任意的。下面的视觉效果展示了各种碰撞的解决方案。
| 示例1 | 示例2 | 示例3 |
|---|---|---|
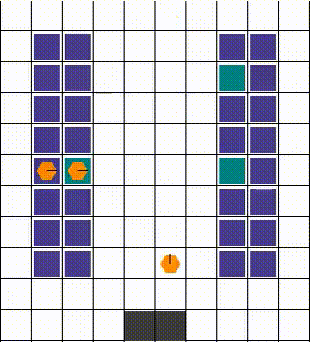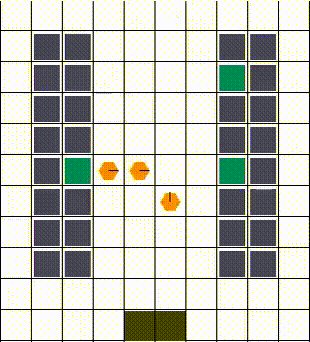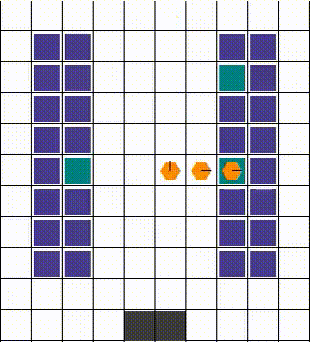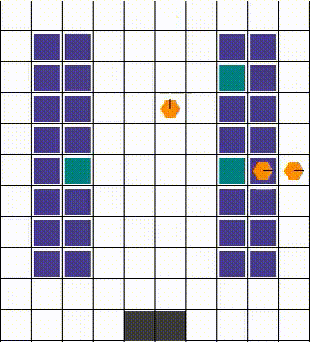 | 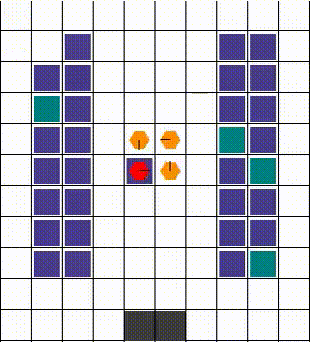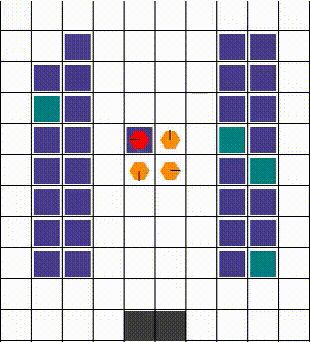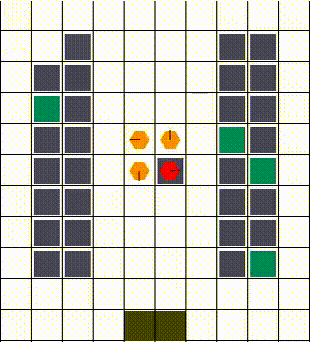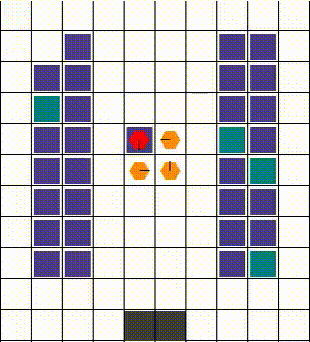 | 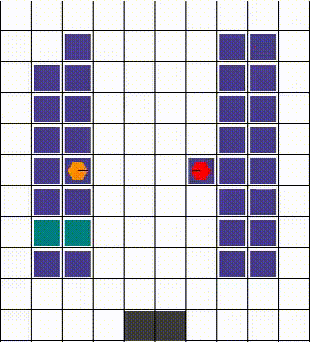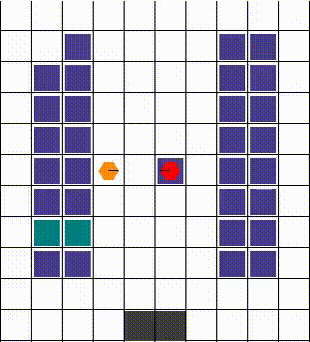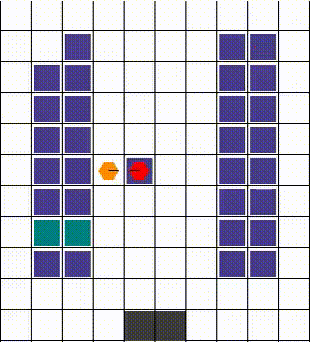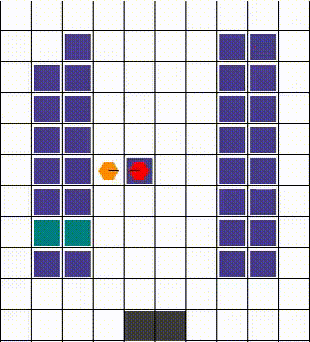 |
奖励
在每个时间点,都会请求一定数量R的货架。当一个请求的货架被带到目标位置时,另一个货架会被均匀采样并添加到当前请求中。智能体成功将请求的货架送到目标位置时会获得奖励1。这些环境中的一个重大挑战是让智能体不仅要递送请求的货架,还要找到一个空位置来返回先前递送的货架。在递送之间有多个步骤会导致奖励信号非常稀疏。
环境参数
多机器人仓库任务由以下参数化:
- 仓库的大小,预设为微小(10x11)、小型(10x20)、中型(16x20)或大型(16x29)。
- 智能体数量N。
- 请求货架数量R。默认情况下R=N,但环境的简单和困难变体分别使用R = 2N和R = N/2。
请注意,R直接影响环境的难度。较小的R,特别是在较大的网格上,会显著影响奖励的稀疏性,从而影响探索:随机带来正确的货架变得越来越不可能。
命名方案
虽然RWARE在使用Warehouse类时允许微调多个参数,但为了简单起见,它还在Gymnasium中注册了多个默认环境。
注册的名称看起来像rware-tiny-2ag-v1,一开始可能看起来很神秘,但实际上并不复杂。每个名称总是以rware开头。接下来,地图大小被附加为-tiny、-small、-medium或-large。地图中的机器人数量被选择为Xag,其中X是大于1的数字(例如,-4ag表示4个智能体)。难度修饰符可选择附加为-easy或-hard,使请求的货架数量分别为智能体数量的两倍或一半(见奖励部分)。最后,-v2是Gymnasium要求的版本。在撰写本文时,所有环境都是v1,但我们会在更改或修复错误时增加它。
几个例子:
import gymnasium as gym
import rware
env = gym.make("rware-tiny-2ag-v2")
env = gym.make("rware-small-4ag-v2")
env = gym.make("rware-medium-6ag-hard-v2")
当然,还有更多设置可用,但必须在环境创建期间更改。例如:
import gymnasium as gym
import rware
env = gym.make("rware-tiny-2ag-v2", sensor_range=3, request_queue_size=6)
自定义布局
你可以通过以下方式设计自定义仓库布局:
import gymnasium as gym
import rware
layout = """
.......
...x...
..x.x..
.x...x.
..x.x..
...x...
.g...g.
"""
env = gym.make("rware:rware-tiny-2ag-v2", layout=layout)
这将把"X"转换为货架,"G"转换为目标位置,结果如下图所示:
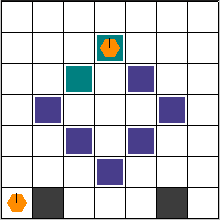
所有参数的详细解释可以在这里找到
安装
假设你已经安装了Python3(最好是在虚拟环境中:venv或Anaconda),你可以使用PyPI:
pip install rware
如果你更喜欢能够获取和编辑代码,可以使用Git下载并安装:
git clone git@github.com:uoe-agents/robotic-warehouse.git
cd robotic-warehouse
pip install -e .
入门
RWARE设计为与Open AI的Gym框架兼容。
创建环境的方式与创建Gym环境完全相同:
import gymnasium as gym
import rware
env = gym.make("rware-tiny-2ag-v2")
你甚至可以绕过Gym的import语句,直接使用:
import gymnasium as gym
env = gym.make("rware:rware-tiny-2ag-v2")
环境名称开头的rware:告诉Gym导入相应的包。
代理数量、观察空间和动作空间可以通过以下方式访问:
env.n_agents # 2
env.action_space # Tuple(Discrete(5), Discrete(5))
env.observation_space # Tuple(Box(XX,), Box(XX,))
返回的空间来自Gym库(gym.spaces)。元组的每个元素对应一个代理,这意味着len(env.action_space) == env.n_agents和len(env.observation_space) == env.n_agents始终为真。
reset和step函数与Gym相同:
obs = env.reset() # 观察的元组
actions = env.action_space.sample() # 可以对动作空间进行采样
print(actions) # (1, 0)
n_obs, reward, done, info = env.step(actions)
print(done) # False
print(reward) # [0.0, 0.0]
这里唯一与Gym不同的是:奖励和done标志是列表,每个元素对应各自的代理。
最后,可以为调试目的渲染环境:
env.render()
在终止前应关闭环境:
env.close()
请引用
如果你使用这个环境,请考虑引用
- 包含此环境的MARL算法比较评估
@inproceedings{papoudakis2021benchmarking,
title={Benchmarking Multi-Agent Deep Reinforcement Learning Algorithms in Cooperative Tasks},
author={Georgios Papoudakis and Filippos Christianos and Lukas Schäfer and Stefano V. Albrecht},
booktitle = {Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks (NeurIPS)},
year={2021},
url = {http://arxiv.org/abs/2006.07869},
openreview = {https://openreview.net/forum?id=cIrPX-Sn5n},
code = {https://github.com/uoe-agents/epymarl},
}
- 在机器人仓库任务中达到最先进性能的方法
@inproceedings{christianos2020shared,
author = {Christianos, Filippos and Sch\"{a}fer, Lukas and Albrecht, Stefano},
booktitle = {Advances in Neural Information Processing Systems},
editor = {H. Larochelle and M. Ranzato and R. Hadsell and M. F. Balcan and H. Lin},
pages = {10707--10717},
publisher = {Curran Associates, Inc.},
title = {Shared Experience Actor-Critic for Multi-Agent Reinforcement Learning},
url = {https://proceedings.neurips.cc/paper/2020/file/7967cc8e3ab559e68cc944c44b1cf3e8-Paper.pdf},
volume = {33},
year = {2020}
}











