
机器学习生产环境的挑战与解决方案
在当今数据驱动的时代,机器学习已经成为许多企业和组织的核心竞争力。然而,将机器学习模型从实验室环境成功部署到生产环境中,并非易事。数据科学家和机器学习工程师常常面临诸多挑战,如模型性能监控、版本控制、扩展性、安全性等问题。为了应对这些挑战,一系列优秀的开源工具应运而生,它们共同构成了"Awesome Production Machine Learning"生态系统。
MLOps的兴起
MLOps(Machine Learning Operations)是一种新兴的实践,旨在将DevOps的最佳实践应用于机器学习系统的开发和部署。它强调自动化和监控,贯穿机器学习系统的整个生命周期,从集成、测试、发布到部署和基础设施管理。MLOps的目标是缩短系统开发周期,提高部署频率,同时保证高质量的模型输出。

开源工具生态系统
"Awesome Production Machine Learning"项目汇集了一系列优秀的开源工具,涵盖了机器学习生产环境中的各个方面。这些工具可以大致分为以下几个类别:
- 数据处理与特征工程
- 模型训练与超参数调优
- 模型部署与服务
- 模型监控与维护
- 安全性与隐私保护
让我们深入了解每个类别中的一些代表性工具。
数据处理与特征工程
在机器学习项目中,数据处理和特征工程往往占据了大部分时间和精力。高质量的数据和特征是构建优秀模型的基础。以下工具可以帮助数据科学家更高效地完成这些任务:
Featuretools
Featuretools是一个开源的自动化特征工程框架。它可以自动从关系数据和事务数据中创建有意义的特征,大大减少了手动特征工程的工作量。Featuretools的核心是Deep Feature Synthesis(DFS)算法,该算法可以通过堆叠和组合原始特征来生成新的特征。
主要特点:
- 自动化特征生成
- 支持时间序列数据
- 可扩展性强,支持大规模数据集
- 与pandas和scikit-learn等库无缝集成
Feature Engine
Feature Engine是另一个强大的特征工程库。它提供了一系列用于变量转换和特征选择的类,这些类遵循scikit-learn的fit-transform API,使其易于集成到现有的机器学习管道中。
主要特点:
- 提供多种特征编码方法(如one-hot编码、目标编码等)
- 支持缺失值处理
- 包含多种特征选择算法
- 文档详尽,易于学习和使用
模型训练与超参数调优
选择合适的模型架构和调整超参数对于获得高性能的机器学习模型至关重要。以下工具可以帮助自动化这一过程:
Optuna
Optuna是一个自动化超参数优化框架。它采用先进的贝叶斯优化算法,可以高效地搜索最佳超参数组合。Optuna的设计非常灵活,可以与各种机器学习框架(如PyTorch、TensorFlow、scikit-learn等)集成。
主要特点:
- 支持多种搜索算法(如随机搜索、贝叶斯优化等)
- 可视化工具,帮助理解超参数对模型性能的影响
- 支持分布式优化,加速搜索过程
- 提供早停机制,节省计算资源
AutoGluon
AutoGluon是亚马逊开源的AutoML工具包。它可以自动化整个机器学习流程,包括特征工程、模型选择和超参数调优。AutoGluon支持表格数据、图像分类和对象检测等多种任务类型。
主要特点:
- 简单易用,只需几行代码即可完成端到端的机器学习任务
- 支持堆叠和集成学习,提高模型性能
- 自动处理缺失值和类别特征
- 可扩展性强,支持自定义模型和搜索空间
模型部署与服务
将训练好的模型部署到生产环境并提供稳定的服务是机器学习项目的关键环节。以下工具可以简化这一过程:
MLflow
MLflow是一个开源平台,用于管理机器学习项目的完整生命周期。它提供了一套API和UI界面,用于跟踪实验、打包代码、管理模型和部署模型。
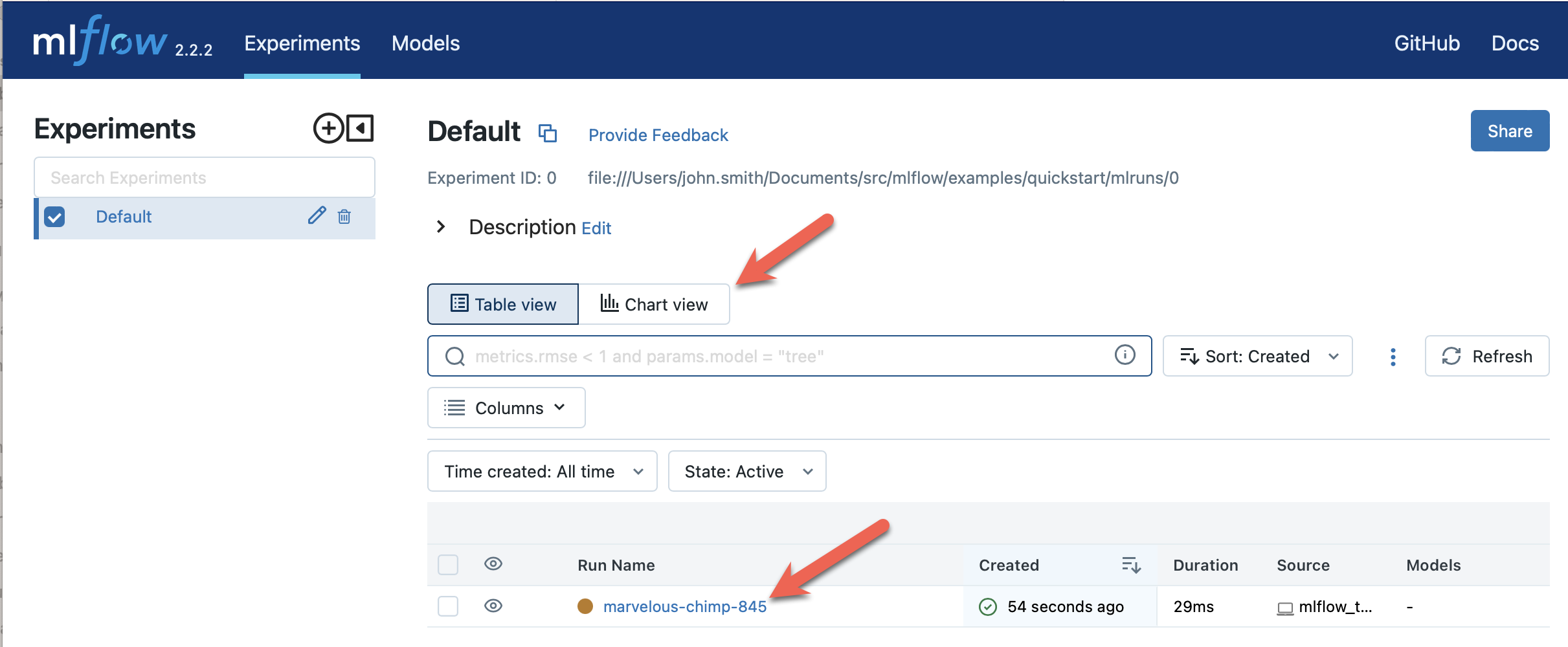
主要特点:
- 实验跟踪:记录参数、代码版本、指标和输出文件
- 项目打包:将数据科学代码打包成可重复执行的形式
- 模型注册:提供集中式模型存储,支持版本控制和阶段转换
- 模型服务:支持多种部署方式,包括REST API、Apache Spark等
BentoML
BentoML是一个灵活的工具,用于打包、服务和部署机器学习模型。它支持主流的机器学习框架,如scikit-learn、PyTorch、TensorFlow等,并提供了一种标准化的方式来构建和部署机器学习服务。
主要特点:
- 模型打包:将模型、依赖和推理代码打包成标准化格式
- 高性能服务:内置优化的模型服务器,支持批处理和微批处理
- 灵活部署:支持Docker容器、Kubernetes、无服务器平台等多种部署选项
- API管理:自动生成OpenAPI规范,支持API版本控制
模型监控与维护
在模型部署到生产环境后,持续监控其性能并及时维护是确保系统可靠性的关键。以下工具可以帮助实现这一目标:
Prometheus
Prometheus是一个开源的监控和告警工具包。虽然它最初设计用于监控大规模分布式系统,但也非常适合监控机器学习模型的性能指标。
主要特点:
- 多维数据模型:通过指标名称和键值对来标识时间序列数据
- 强大的查询语言:PromQL允许灵活地查询和聚合时间序列数据
- 可视化:与Grafana等工具集成,提供丰富的可视化选项
- 告警:支持灵活的告警规则配置和通知机制
Seldon Core
Seldon Core是一个开源平台,用于在Kubernetes上部署机器学习模型。它不仅提供了模型部署功能,还包括了强大的监控和解释能力。
主要特点:
- 支持多种机器学习框架
- A/B测试和多臂老虎机实验
- 复杂的推理图,支持模型组合和前后处理
- 集成了Prometheus和Grafana,提供实时监控
- 模型解释功能,帮助理解模型决策
安全性与隐私保护
随着机器学习系统的广泛应用,数据安全和隐私保护变得越来越重要。以下工具可以帮助增强机器学习系统的安全性:
Adversarial Robustness Toolbox (ART)
ART是IBM开发的一个用于机器学习安全的Python库。它提供了工具来评估、防御和验证机器学习模型和应用程序对抗各种威胁。
主要特点:
- 支持多种攻击方法(如对抗样本生成)
- 提供防御技术(如对抗训练、输入净化等)
- 包含鲁棒性度量指标
- 支持多种深度学习框架(TensorFlow、PyTorch等)
TensorFlow Privacy
TensorFlow Privacy是一个用于训练机器学习模型的库,它整合了差分隐私技术。差分隐私可以防止模型无意中记忆或泄露训练数据中的敏感信息。
主要特点:
- 提供差分隐私优化器,可以轻松集成到现有的TensorFlow模型中
- 支持计算隐私预算
- 包含用于评估模型隐私性的工具
结语
"Awesome Production Machine Learning"项目汇集的这些开源工具,为构建可靠、高效、安全的机器学习生产系统提供了强大支持。从数据处理到模型部署,从性能监控到安全防护,这些工具覆盖了机器学习系统生命周期的各个环节。
然而,需要注意的是,仅仅使用这些工具并不能解决所有问题。成功的机器学习项目还需要团队具备深厚的领域知识、良好的工程实践以及持续学习和改进的文化。随着技术的不断发展,我们相信会有更多创新的工具和方法出现,进一步推动机器学习在生产环境中的应用。
对于数据科学家和机器学习工程师来说,持续关注这个领域的发展,并积极尝试和采纳新的工具和方法,将有助于构建更加强大和可靠的机器学习系统。让我们共同期待机器学习技术在未来能为更多领域带来革命性的变革!


















