
HiFi-GAN简介
HiFi-GAN(高保真生成对抗网络)是由Jungil Kong、Jaehyeon Kim和Jaekyoung Bae等人在2020年提出的一种高效高保真语音合成模型。它采用生成对抗网络(GAN)的架构,能够从mel频谱图生成高质量的语音波形。
HiFi-GAN的主要特点包括:
- 生成速度快:在单个V100 GPU上可以实现167.9倍实时的语音生成速度
- 音质高:生成的语音质量接近人类语音
- 通用性强:可用于未见说话人的mel频谱图反演和端到端语音合成
- 资源需求低:小型版本可在CPU上实现13.4倍实时生成速度
相关资源
-
官方论文: HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
-
官方代码实现: GitHub - jik876/hifi-gan
-
在线演示: HiFi-GAN Demo
-
预训练模型下载: HiFi-GAN Pretrained Models
-
PyTorch Hub模型: NVIDIA HiFi-GAN
-
Papers With Code页面: HiFi-GAN Explained
快速上手
- 克隆官方代码仓库:
git clone https://github.com/jik876/hifi-gan.git
cd hifi-gan
- 安装依赖:
pip install -r requirements.txt
- 下载预训练模型并进行推理:
import torch
# 加载模型
hifigan = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_hifigan')
# 从mel频谱图生成音频
audio = hifigan(mel_spectrogram)
模型结构
HiFi-GAN由一个生成器和两个判别器组成:
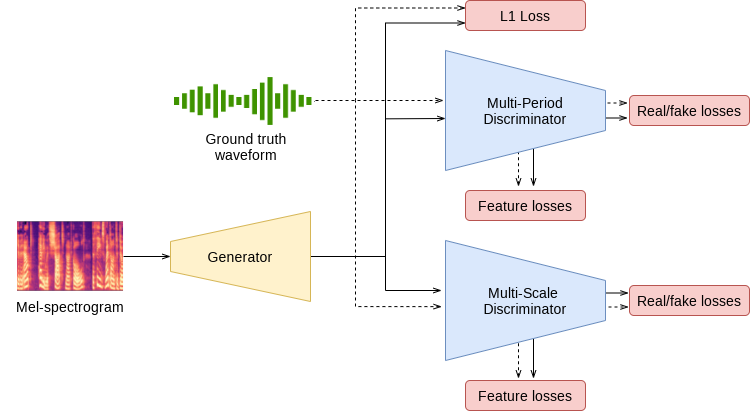
- 生成器:使用转置卷积进行上采样,并采用多感受野融合模块
- 多周期判别器:处理输入音频的周期性信号
- 多尺度判别器:在不同尺度上评估音频样本
训练和微调
-
准备数据集,如LJSpeech数据集
-
训练模型:
python train.py --config config_v1.json
- 微调已有模型:
python train.py --fine_tuning True --config config_v1.json
应用场景
HiFi-GAN可应用于多种语音合成任务:
- 文本到语音(TTS)系统的声码器
- 语音转换
- 语音增强
- 音乐生成
后续发展
HiFi-GAN为高效高质量的语音合成开辟了新的方向。未来可能的研究方向包括:
- 进一步提高生成速度和质量
- 扩展到多说话人和多语言场景
- 结合其他先进技术,如自适应层归一化等
希望本文能帮助你快速了解HiFi-GAN并开始应用这一强大的语音合成模型。如有任何问题,欢迎在评论区讨论交流!















