
LangChain聊天机器人:使用LangChain和Streamlit构建智能对话系统
在人工智能和自然语言处理技术快速发展的今天,聊天机器人已经成为许多应用场景中不可或缺的重要组成部分。本文将详细介绍如何使用LangChain框架和Streamlit构建一个功能强大、可定制的聊天机器人系统。
项目概述
本项目的目标是创建一个基于LangChain的聊天机器人,它能够回答用户关于LangChain框架的各种问题。我们将使用Python文档和API参考作为知识库,通过检索增强生成(RAG)的方式来提供准确的回答。整个系统将使用Streamlit构建用户界面,实现一个完整的Web应用。
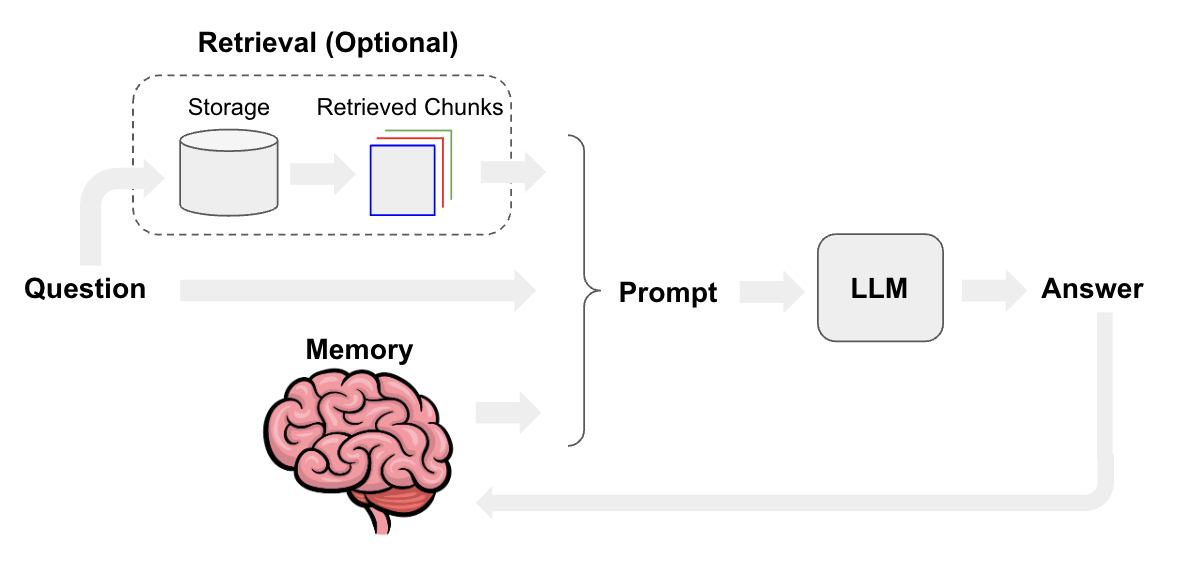
环境准备
在开始开发之前,我们需要准备好开发环境。建议使用Conda创建一个新的虚拟环境:
conda create --name langchain_chatbot python=3.10
conda activate langchain_chatbot
然后安装所需的依赖包:
pip install langchain openai streamlit python-dotenv
核心组件实现
1. 数据摄取
为了让聊天机器人能够回答LangChain相关的问题,我们首先需要导入和索引相关文档。主要步骤包括:
- 使用SitemapLoader和RecursiveURLLoader加载Python文档和API参考。
- 使用RecursiveCharacterTextSplitter将文档分割成小块。
- 使用OpenAIEmbeddings生成文本嵌入。
- 将嵌入存储到Weaviate向量数据库中。
from langchain.document_loaders import SitemapLoader, RecursiveURLLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Weaviate
# 加载文档
docs = SitemapLoader("https://python.langchain.com/sitemap.xml").load()
api_ref = RecursiveUrlLoader("https://api.python.langchain.com/en/latest/").load()
# 文本分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=4000, chunk_overlap=200)
splits = text_splitter.split_documents(docs + api_ref)
# 生成嵌入并存储
embeddings = OpenAIEmbeddings()
vectoREstore = Weaviate.from_documents(splits, embeddings)
2. 问答链构建
问答链是聊天机器人的核心,它负责处理用户输入、检索相关文档并生成回答。我们使用LangChain表达式语言(LCEL)来定义这个链:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnablePassthrough
# 初始化语言模型
llm = ChatOpenAI(model="gpt-3.5-turbo")
# 定义提示模板
template = """根据以下上下文回答问题。如果你不知道答案,就说你不知道,不要试图编造答案。
上下文: {context}
问题: {question}
回答:"""
prompt = ChatPromptTemplate.from_template(template)
# 构建检索-问答链
retriever = vectorstore.as_retriever()
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
)
3. Streamlit界面
使用Streamlit可以快速构建一个直观的Web界面:
import streamlit as st
st.title("LangChain聊天机器人")
# 初始化会话状态
if "messages" not in st.session_state:
st.session_state.messages = []
# 显示聊天历史
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# 接收用户输入
if prompt := st.chat_input("你的问题是?"):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
# 生成回答
with st.chat_message("assistant"):
response = rag_chain.invoke(prompt)
st.markdown(response)
st.session_state.messages.append({"role": "assistant", "content": response})
部署与监控
将聊天机器人部署到生产环境后,我们可以使用LangSmith进行监控和分析。LangSmith提供了丰富的指标和可视化工具,帮助我们跟踪聊天机器人的性能:
- 响应时间分析
- 成功率监控
- 用户反馈统计
- Token使用量跟踪
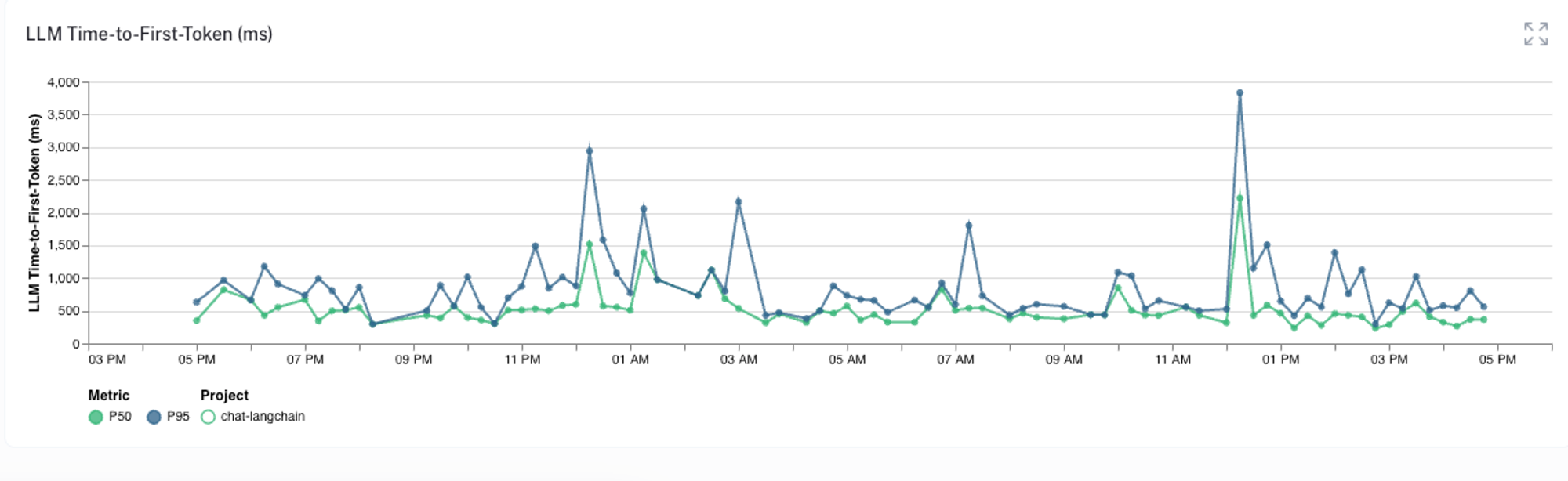
通过这些指标,我们可以持续优化聊天机器人的性能和用户体验。
结语
本文详细介绍了如何使用LangChain和Streamlit构建一个智能聊天机器人系统。从数据摄取、核心组件实现到部署监控,我们覆盖了整个开发流程。这个项目不仅可以回答LangChain相关问题,还可以通过修改知识库来适应其他领域的应用需求。
随着大语言模型和相关技术的不断进步,类似的聊天机器人系统将在各行各业发挥越来越重要的作用。我们期待看到更多创新的应用场景和解决方案的出现。
如果你对本项目感兴趣,欢迎访问GitHub仓库获取完整代码,并根据自己的需求进行定制和扩展。让我们一起探索LangChain的无限可能!


















