
机器学习为编译器优化带来新机遇
随着现代计算机系统的日益复杂,如何编译出更快更小的代码一直是编译器领域面临的重大挑战。传统的基于启发式规则的编译优化方法已经很难继续提升性能,而机器学习技术的快速发展为编译器优化带来了新的机遇。近年来,将机器学习应用于编译器优化成为学术界和工业界的研究热点,取得了一系列突破性进展。
本文将全面介绍机器学习在编译器优化中的应用现状,包括最新的研究成果、开源工具以及未来发展趋势,为读者提供这一新兴领域的全面认识。
机器学习驱动的编译器优化框架
Google Research最近提出了一个名为MLGO(Machine Learning Guided Compiler Optimizations)的框架,这是首个能够系统地将机器学习技术整合到工业级编译器LLVM中的通用框架。MLGO使用强化学习来训练神经网络,以替代LLVM中的启发式决策。
MLGO主要包含两个优化:
- 内联优化(Inlining):通过机器学习模型决定是否内联某个函数调用,以减小代码体积。
- 寄存器分配优化:使用强化学习来优化寄存器分配策略,提高代码性能。
这两项优化都已在LLVM代码库中开源,并在生产环境中得到部署应用。
基于机器学习的内联优化
内联是一种重要的编译优化技术,可以通过消除冗余代码来减小程序体积。传统的内联决策主要依赖于复杂的启发式规则,难以进一步优化。MLGO框架使用强化学习来训练一个神经网络模型,用于替代原有的启发式规则。
在编译过程中,编译器会遍历调用图,对每对调用者-被调用者函数询问神经网络模型是否应该进行内联。模型会根据输入的特征(如基本块数量、用户数等)做出决策。这个过程是序贯的,因为之前的内联决策会影响后续的调用图结构。

MLGO在一个包含30,000个模块的大型内部软件包上训练了内联优化模型。实验结果表明,该模型具有良好的泛化性,能够在其他软件上实现3%~7%的代码体积减小。此外,模型在3个月后仍保持较好的性能,展现了跨时间的泛化能力。
基于机器学习的寄存器分配优化
寄存器分配是另一个关键的编译优化问题,直接影响代码的执行效率。MLGO框架同样使用强化学习来优化LLVM的寄存器分配策略。
在寄存器分配过程中,当没有可用寄存器时,需要决定驱逐哪个活跃变量。这个"活跃变量驱逐"问题就是MLGO训练模型来解决的目标。模型的目标是减少不必要的内存访问,提高代码性能。
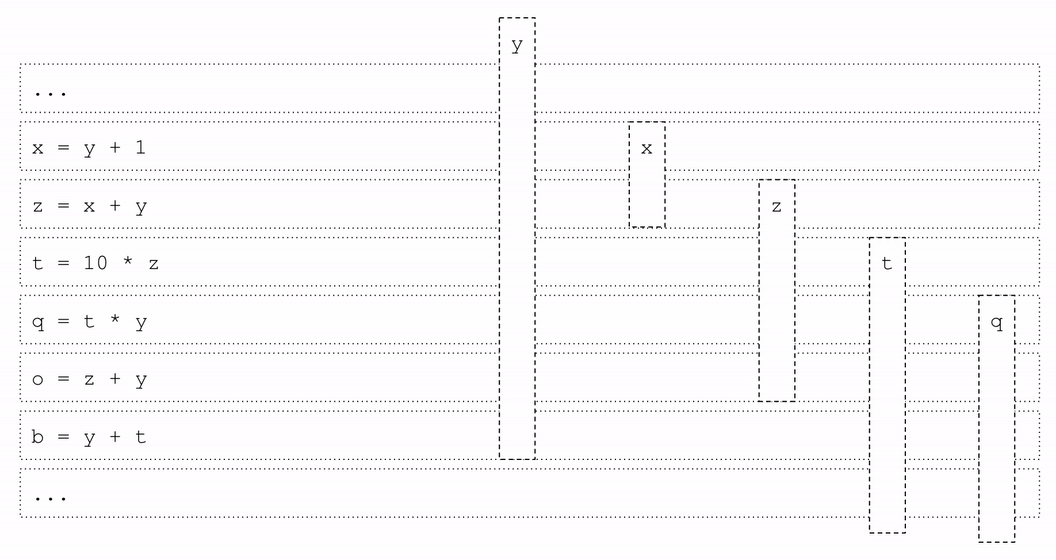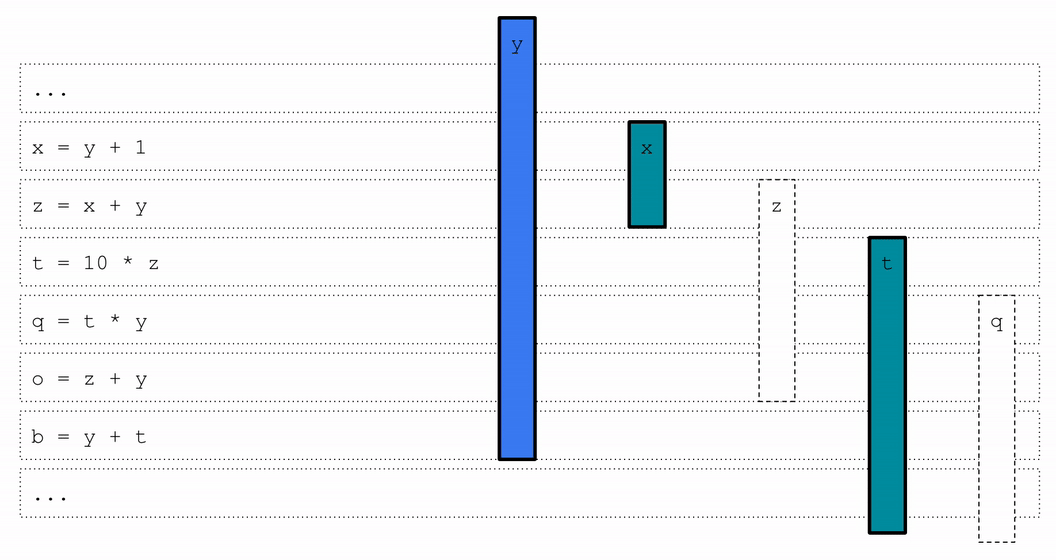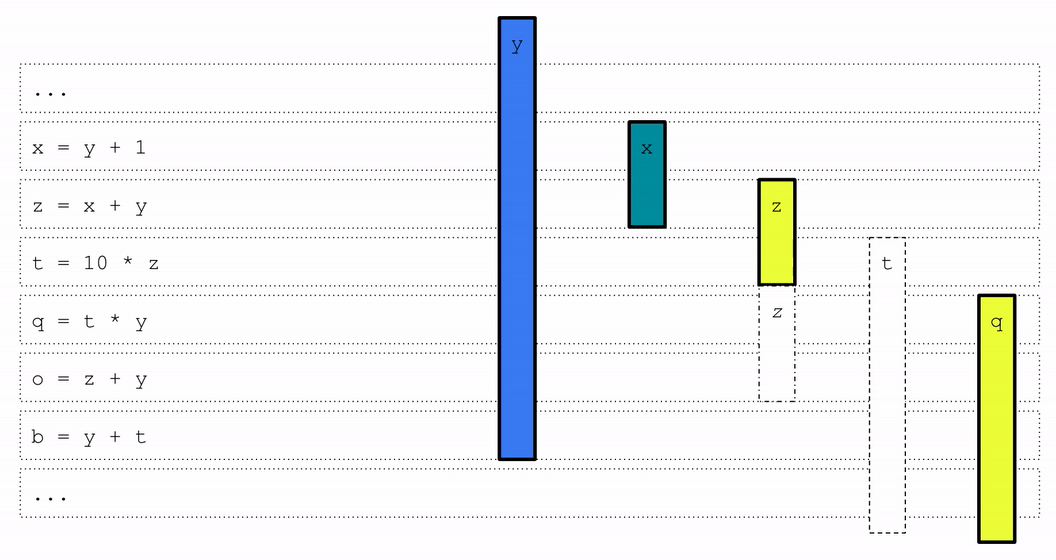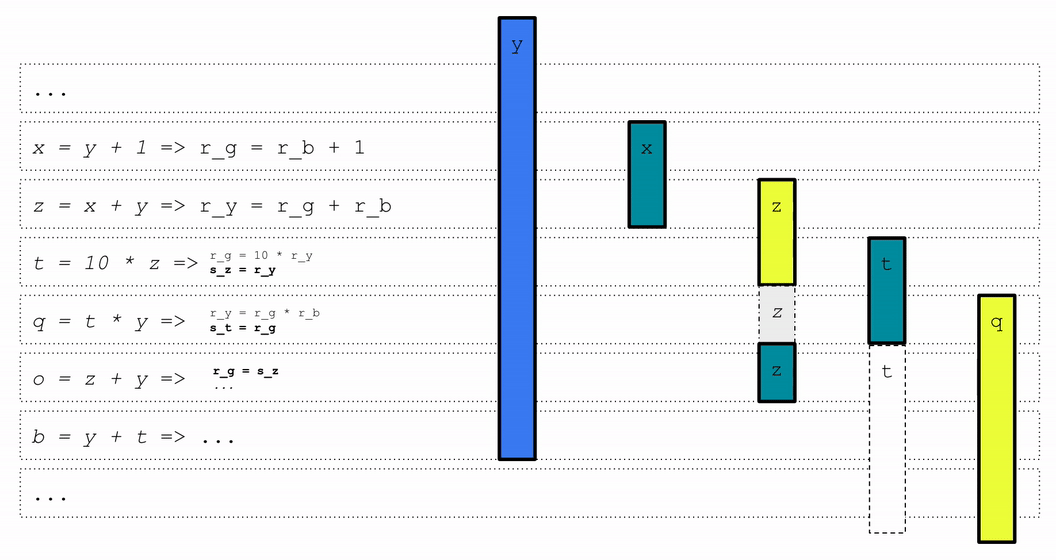
实验结果显示,MLGO训练的寄存器分配模型在一组内部大规模数据中心应用上实现了0.3%~1.5%的每秒查询数(QPS)提升。这个性能提升在部署后的几个月内持续存在,证明了模型的时间泛化能力。
开源工具与数据集
除了Google的MLGO框架,还有一些其他的开源工具和数据集可供研究人员使用:
- LLVM-MI: 微软开源的基于LLVM的机器学习优化框架。
- CompilerGym: Facebook Research开发的编译器优化强化学习环境。
- TVM: 一个端到端的深度学习编译器栈,支持多种硬件后端。
这些工具为研究人员提供了实验平台,大大促进了该领域的发展。
未来展望
机器学习在编译器优化中的应用仍处于起步阶段,还有很多值得探索的方向:
- 更深入的优化:扩展到更多编译优化阶段,如指令调度、循环优化等。
- 更智能的模型:探索更先进的机器学习算法,如元学习、自监督学习等在编译优化中的应用。
- 硬件协同设计:将机器学习优化与硬件架构设计相结合,实现软硬件协同优化。
- 可解释性研究:提高机器学习模型在编译优化决策中的可解释性和可信性。
随着研究的深入和技术的进步,相信机器学习将为编译器优化带来更多突破,推动编程语言和计算机体系结构的发展。
结语
机器学习在编译器优化中的应用是一个充满活力的新兴领域。本文介绍的MLGO框架及其在内联优化和寄存器分配中的应用,展示了机器学习技术在提升编译器性能方面的巨大潜力。我们期待看到更多创新性的研究成果,推动编译器技术的进步,为软件开发和计算机系统优化带来新的机遇。
对于有兴趣深入了解这一领域的读者,可以访问awesome-machine-learning-in-compilers项目,其中收集了大量相关的研究论文、工具和数据集。让我们共同期待机器学习与编译器优化的美好未来!


















