
引言
在计算机视觉和图像处理领域,低光照图像增强一直是一个具有挑战性的任务。由于光照不足,这类图像往往存在细节丢失、噪声严重等问题,严重影响了后续的图像分析和识别工作。近年来,随着深度学习技术的发展,基于神经网络的低光照图像增强方法取得了显著进展。然而,如何在保持图像自然度的同时有效提高图像质量,仍然是该领域的一个重要研究方向。
在这一背景下,来自中国的研究团队提出了一种名为PyDIff的新方法,该方法基于金字塔扩散模型,为低光照图像增强任务带来了新的突破。PyDIff方法在IJCAI 2023国际人工智能联合会议上获得了口头报告,充分体现了其在学术界的重要影响。
PyDIff方法概述
PyDIff是一种基于金字塔扩散模型的低光照图像增强方法。该方法的核心思想是利用多尺度金字塔结构和扩散模型的生成能力,在不同分辨率下逐步恢复和增强低光照图像的细节。
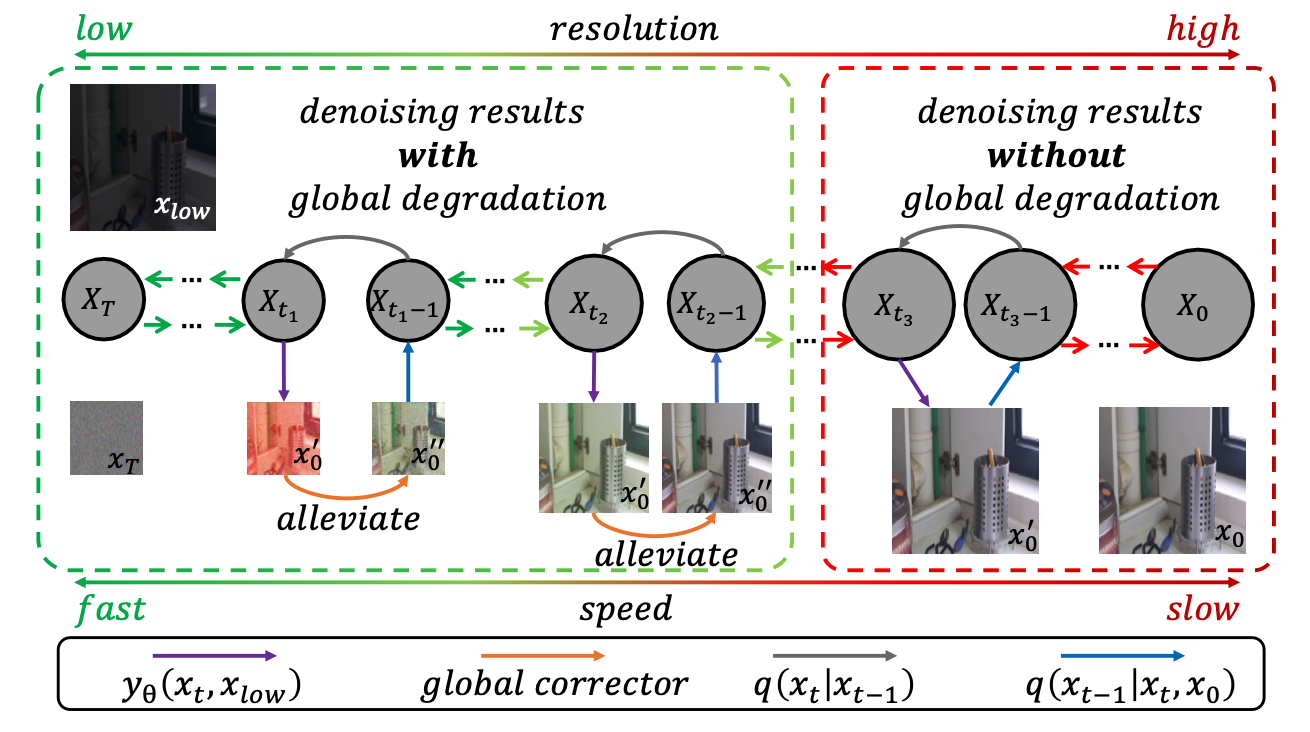
如上图所示,PyDiff的整体框架主要包括以下几个关键组件:
-
金字塔结构:将输入的低光照图像分解为多个尺度层次,便于在不同分辨率下进行处理。
-
扩散模型:在每个尺度层次上,使用扩散模型来学习从低质量图像到高质量图像的映射关系。
-
多尺度融合:将不同尺度层次的增强结果进行融合,得到最终的高质量输出图像。
这种多尺度的处理方式使得PyDiff能够有效地处理不同尺度的图像细节,从而在保持全局一致性的同时,还能恢复局部的精细结构。
PyDiff的优势
与现有的低光照图像增强方法相比,PyDiff具有以下几个突出优势:
-
高质量增强效果:在LOL(Low-Light)数据集上的评估结果显示,PyDiff在PSNR、SSIM和LPIPS等多个指标上均优于现有的最先进方法。
-
多尺度处理能力:金字塔结构使得PyDiff能够同时关注图像的全局和局部信息,从而实现更加自然和细腻的增强效果。
-
生成式方法的优势:基于扩散模型的生成式方法使得PyDiff在处理严重退化的低光照图像时具有更强的鲁棒性和适应性。
-
灵活的应用潜力:PyDiff不仅适用于低光照图像增强,还可以扩展到其他图像恢复和增强任务中。
实验结果与性能评估
为了验证PyDiff的有效性,研究团队在广泛使用的LOL数据集上进行了全面的评估。评估结果如下表所示:
| 方法 | PSNR | SSIM | LPIPS |
|---|---|---|---|
| KIND | 20.87 | 0.80 | 0.17 |
| KIND++ | 21.30 | 0.82 | 0.16 |
| Bread | 22.96 | 0.84 | 0.16 |
| IAT | 23.38 | 0.81 | 0.26 |
| HWMNet | 24.24 | 0.85 | 0.12 |
| LLFLOW | 24.99 | 0.92 | 0.11 |
| PyDiff (Ours) | 27.09 | 0.93 | 0.10 |
从表中可以看出,PyDiff在所有三个评估指标上都取得了最优结果。特别是在PSNR指标上,PyDiff相比第二名的LLFLOW方法提升了超过2dB,这在图像增强领域是一个非常显著的进步。
PyDiff的实现与使用
为了促进学术交流和技术推广,研究团队将PyDiff的完整实现开源在了GitHub上。感兴趣的研究者和开发者可以通过以下步骤来使用PyDiff:
-
环境配置:
git clone https://github.com/limuloo/PyDIff.git cd PyDiff conda create -n PyDiff python=3.7 conda activate PyDiff conda install pytorch==1.7.0 torchvision torchaudio cudatoolkit=11.0 -c pytorch -
安装依赖:
cd BasicSR-light pip install -r requirements.txt BASICSR_EXT=True sudo $(which python) setup.py develop cd ../PyDiff pip install -r requirements.txt BASICSR_EXT=True sudo $(which python) setup.py develop -
数据准备: 研究者可以使用LOL数据集进行实验。将数据集下载后,按照以下结构放置:
PyDiff/ BasicSR-light/ PyDiff/ dataset/ LOLdataset/ our485/ eval15/ -
预训练模型: 可以从这里下载预训练模型,并将其放置在以下位置:
PyDiff/ BasicSR-light/ PyDiff/ pretrained_models/ LOLweights.pth -
测试:
cd PyDiff/ CUDA_VISIBLE_DEVICES=0 python pydiff/train.py -opt options/infer.yaml -
训练: 对于拥有2个24GB或更大显存的GPU,可以使用以下命令进行训练:
cd PyDiff/ CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 --master_port=22666 pydiff/train.py -opt options/train_v1.yaml --launcher pytorch对于单GPU训练,可以使用以下命令:
cd PyDiff/ CUDA_VISIBLE_DEVICES=0 python -m torch.distributed.launch --nproc_per_node=1 --master_port=22666 pydiff/train.py -opt options/train_v2.yaml --launcher pytorch
未来展望
尽管PyDiff在低光照图像增强任务上取得了显著成果,但研究团队认为这只是一个开始。未来的研究方向可能包括:
- 进一步优化模型结构,提高处理效率和实时性能。
- 探索在更多样化的场景和数据集上的应用效果。
- 将PyDiff的核心思想扩展到其他图像处理任务,如超分辨率、去噪等。
- 结合最新的生成式AI技术,进一步提升模型的生成质量和多样性。
结论
PyDiff作为一种新颖的低光照图像增强方法,通过结合金字塔结构和扩散模型,在保持图像自然度的同时显著提升了图像质量。其在LOL数据集上的卓越表现,不仅推动了低光照图像处理技术的发展,也为计算机视觉领域的其他任务提供了新的思路。随着开源代码的发布,相信PyDiff将吸引更多研究者的关注,并在实际应用中发挥重要作用。
对于有兴趣深入了解或应用PyDiff的读者,可以访问GitHub项目页面获取更多详细信息和最新更新。同时,如果您在研究中使用了PyDiff,请引用以下论文以支持作者的工作:
@article{zhou2023pyramid,
title={Pyramid Diffusion Models For Low-light Image Enhancement},
author={Zhou, Dewei and Yang, Zongxin and Yang, Yi},
journal={arXiv preprint arXiv:2305.10028},
year={2023}
}
PyDiff的成功不仅标志着低光照图像增强技术的一个重要里程碑,也为整个计算机视觉领域注入了新的活力。我们期待看到更多基于PyDiff的创新应用和进一步的技术突破,共同推动人工智能和图像处理技术的不断发展。












