

Stable Diffusion 2 GUI:让AI图像生成触手可及
在人工智能技术迅速发展的今天,AI图像生成已经成为一个热门话题。而Stable Diffusion作为其中的佼佼者,以其强大的生成能力和开源特性吸引了众多开发者和用户的关注。今天,我们要介绍的是一个基于Stable Diffusion 2.1模型的轻量级Web界面——Stable Diffusion 2 GUI,它为用户提供了一种简单易用的方式来体验AI图像生成的魅力。
项目概览
Stable Diffusion 2 GUI是由GitHub用户qunash开发的开源项目。该项目旨在为Stable Diffusion 2.1模型提供一个轻量级的Web用户界面,使得用户可以通过直观的操作来使用各种AI图像生成功能。项目地址为:https://github.com/qunash/stable-diffusion-2-gui
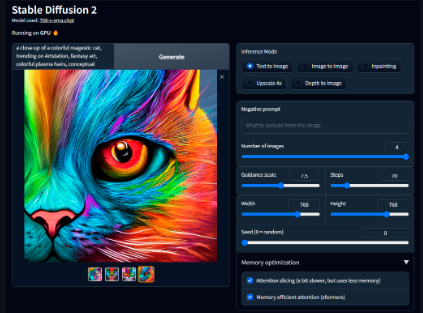
主要特性
Stable Diffusion 2 GUI提供了多种强大的功能,包括:
-
文本生成图像(Text-to-Image):用户可以输入文本描述,AI将根据描述生成相应的图像。
-
图像到图像转换(Image-to-Image):用户可以上传一张图片,然后通过文本提示来修改或增强该图片。
-
深度图到图像(Depth-to-Image):利用深度信息来生成或修改图像。
-
图像修复(Inpainting):可以对图像的特定区域进行修复或替换。
-
图像放大(Upscale):将低分辨率图像提升到更高的分辨率。
这些功能都是基于Hugging Face的Diffusers库实现的,确保了高质量的生成结果和流畅的用户体验。
技术实现
Stable Diffusion 2 GUI采用了以下技术栈:
- 后端:使用Python实现,基于Hugging Face的Diffusers库来调用Stable Diffusion 2.1模型。
- 前端:使用Gradio框架构建Web界面,提供了简洁直观的用户交互体验。
- 模型:采用Stable Diffusion 2.1,这是一个强大的文本到图像生成模型,由Stability AI开发。
项目的轻量级设计使得它可以在各种环境中快速部署和运行,无需复杂的配置过程。
使用指南
要开始使用Stable Diffusion 2 GUI,用户需要按照以下步骤操作:
-
克隆项目仓库:
git clone https://github.com/qunash/stable-diffusion-2-gui.git -
安装依赖:
pip install -r requirements.txt -
运行应用:
python app.py
运行后,用户可以通过浏览器访问本地Web界面,开始体验AI图像生成的乐趣。
社区反响
自发布以来,Stable Diffusion 2 GUI在GitHub上已经获得了超过600颗星星,这充分说明了社区对该项目的认可和支持。许多用户appreciate了项目的简洁设计和易用性,认为它降低了使用Stable Diffusion模型的门槛。
未来展望
尽管Stable Diffusion 2 GUI已经提供了丰富的功能,但开发者仍在持续改进和扩展项目。未来可能会看到以下方面的增强:
- 支持更多的Stable Diffusion模型版本
- 增加更多的图像处理和生成选项
- 优化用户界面,提供更多自定义设置
- 提高生成速度和效率
结语
Stable Diffusion 2 GUI为AI图像生成技术的普及做出了重要贡献。它不仅为专业人士提供了一个便捷的工具,也为普通用户打开了AI创作的大门。随着项目的不断发展和完善,我们有理由相信,它将在AI图像生成领域发挥更大的作用,激发更多人的创造力。
无论你是对AI技术感兴趣的开发者,还是寻求创意灵感的艺术家,Stable Diffusion 2 GUI都值得一试。它可能会成为你探索AI图像生成世界的绝佳起点,让你体验到科技与艺术融合的魅力。
🚀 如果你对Stable Diffusion 2 GUI感兴趣,不妨访问项目GitHub页面,亲自体验一下这个强大而易用的AI图像生成工具。也欢迎为项目贡献代码或提出宝贵的建议,让我们一起推动AI创作工具的发展!


















