
Woodpecker项目简介
在人工智能和自然语言处理领域,多模态大语言模型(MLLMs)的快速发展引人注目。然而,这些模型面临着一个严峻的挑战 - 幻觉问题。所谓幻觉,指的是模型生成的文本内容与输入图像不一致的现象。为了解决这个问题,研究人员提出了各种方法,其中大多数依赖于特定数据的指令微调。而最近,一个名为Woodpecker的项目为我们带来了全新的解决思路。

Woodpecker项目由一群来自中国科学技术大学的研究人员开发,旨在通过一种无需训练的方法来识别和纠正多模态大语言模型中的幻觉。正如啄木鸟治愈树木一样,Woodpecker能够从生成的文本中挑出并纠正幻觉内容。这种创新方法不仅能够提高模型输出的准确性,还为解决MLLMs中的幻觉问题开辟了一条新的道路。
Woodpecker的工作原理
Woodpecker采用了一种后处理的方式来纠正幻觉,这使得它能够轻松地为不同的MLLMs提供服务。其工作流程包含五个主要阶段:
- 关键概念提取
- 问题formulation
- 视觉知识验证
- 视觉声明生成
- 幻觉纠正
这种分阶段的设计不仅使得整个过程更加透明,也提高了系统的可解释性。用户可以通过访问每个阶段的中间输出来了解Woodpecker是如何一步步识别和纠正幻觉的。

Woodpecker的评估结果
为了验证Woodpecker的有效性,研究团队进行了广泛的实验评估。他们选择了四个基线模型进行比较:LLaVA、mPLUG-Owl、Otter和MiniGPT-4。评估结果令人振奋:
POPE基准测试
POPE基准测试主要关注对象级别的幻觉。在这项测试中,Woodpecker展现出了显著的性能提升。与基线模型相比,Woodpecker在准确率上取得了30.66%/24.33%的提升,这充分证明了该方法在处理对象级幻觉方面的卓越能力。
MME测试
MME测试不仅关注对象级幻觉,还包括属性级幻觉。在这项更全面的测试中,Woodpecker同样表现出色。结果显示,Woodpecker能够有效地识别和纠正不同类型的幻觉,进一步证明了其versatility和有效性。
LLaVA-QA90测试
研究团队还提出了一种新的开放式评估方法,利用最近开放的GPT-4V接口直接进行评估。他们设计了两个指标:准确性和详细程度。在这项测试中,Woodpecker再次展现出优异的性能,不仅提高了输出的准确性,还增强了内容的详细程度。
这些评估结果充分证明了Woodpecker在处理多模态大语言模型幻觉问题上的巨大潜力。它不仅能够显著提高模型输出的准确性,还能保持甚至增强输出的丰富性和详细程度。
Woodpecker的实际应用
为了让更多人体验Woodpecker的强大功能,研究团队还开发了一个在线演示系统。用户可以通过在线演示亲自体验Woodpecker的幻觉纠正能力。这个演示系统不仅展示了Woodpecker的实际应用效果,还为研究人员和开发者提供了一个直观的平台来了解和评估这项技术。
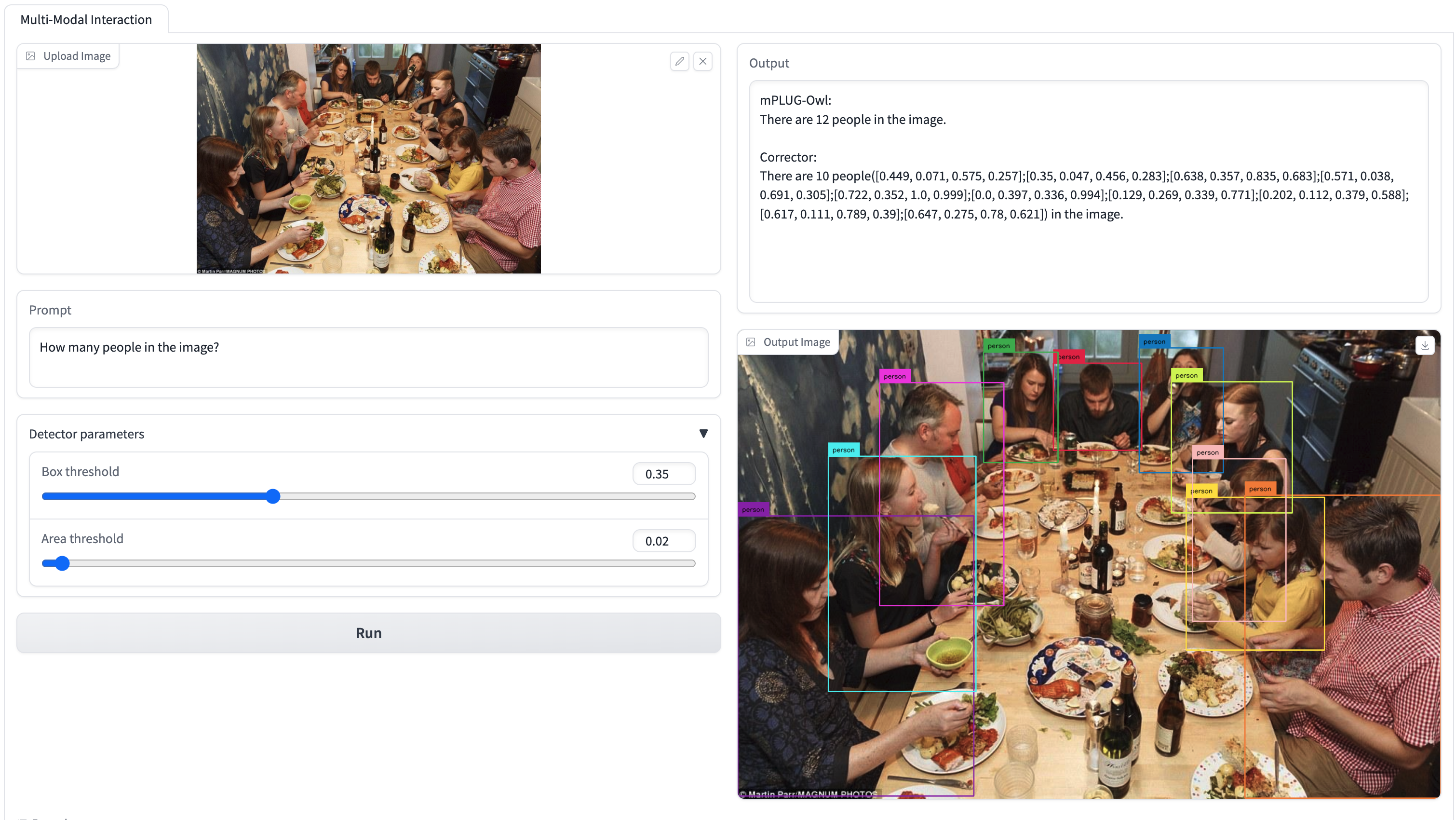
Woodpecker的技术实现
对于那些希望深入了解Woodpecker技术细节或者想要在自己的项目中使用Woodpecker的开发者,研究团队提供了详细的安装和使用指南。
环境配置
首先,需要创建一个conda环境并安装必要的依赖:
conda create -n corrector python=3.10
conda activate corrector
pip install -r requirements.txt
然后,安装spacy及相关模型包:
pip install -U spacy
python -m spacy download en_core_web_lg
python -m spacy download en_core_web_md
python -m spacy download en_core_web_sm
对于开放集检测器,需要按照GroundingDINO的指南进行安装。
使用方法
Woodpecker的使用非常简单。只需运行以下命令即可基于图像和MLLM的文本输出进行纠正:
python inference.py \
--image-path {path/to/image} \
--query "Some query.(e.x. Describe this image.)" \
--text "Some text to be corrected." \
--detector-config "path/to/GroundingDINO_SwinT_OGC.py" \
--detector-model "path/to/groundingdino_swint_ogc.pth" \
--api-key "sk-xxxxxxx" \
纠正后的文本将会在终端中打印出来,中间结果默认保存在./intermediate_view.json文件中。
Woodpecker的影响和未来展望
Woodpecker项目的出现无疑为解决多模态大语言模型中的幻觉问题提供了一个全新的视角。与传统的需要大量数据和计算资源进行模型重训练的方法不同,Woodpecker采用了一种轻量级、灵活的后处理方法。这种方法不仅效果显著,而且具有很强的通用性,可以应用于各种不同的MLLMs。
Woodpecker的成功也为人工智能领域的其他挑战提供了启发。它展示了如何通过创新的方法来解决复杂的AI问题,而不必总是依赖于更大的模型或更多的训练数据。这种思路可能会影响未来AI研究的方向,推动更多轻量级、高效率的解决方案的出现。
此外,Woodpecker的开源性质也为整个AI社区带来了巨大价值。研究人员和开发者可以基于Woodpecker的代码进行进一步的改进和创新,这将加速多模态AI技术的发展。
结语
Woodpecker项目的出现标志着多模态大语言模型研究的一个重要里程碑。它不仅提供了一种有效的幻觉纠正方法,还为整个领域带来了新的思考方向。随着技术的不断发展和完善,我们可以期待看到更多基于Woodpecker的应用和创新,这将进一步推动多模态AI技术向更高水平发展。
对于那些对Woodpecker项目感兴趣的研究者和开发者,可以访问Woodpecker的GitHub仓库获取更多详细信息。同时,如果您在使用过程中有任何问题,也可以通过邮件(bradyfu24@gmail.com)或者添加微信(xjtupanda)与开发团队取得联系。
让我们共同期待Woodpecker项目在未来带来更多惊喜,为构建更加智能、可靠的AI系统贡献力量! 🚀🌟










