
 Github
Github Huggingface
Huggingface 文档
文档🌊 uniflow



uniflow 提供了一个统一的大语言模型接口,用于提取和转换原始文档。
- 文档类型:Uniflow 支持从 PDF、HTML 和 TXT 中提取数据。
- 大语言模型无关:Uniflow 支持大多数常用的大语言模型进行文本转换,包括:
- OpenAI 模型(GPT3.5 和 GPT4),
- Google Gemini 模型(Gemini 1.5、多模态),
- AWS BedRock 模型,
- Huggingface 开源模型,包括 Mistral-7B,
- Azure OpenAI 模型等。
:question: 要解决的问题
Uniflow 解决了机器学习科学家在准备大语言模型训练数据时面临的两个关键挑战:
- 首先,将 PDF 和 Word 等遗留文档提取为干净的文本(大语言模型可以从中学习)是很棘手的,这是由于 PDF 布局复杂以及提取过程中信息丢失;
- 其次,将提取的数据转换为适合训练大语言模型的格式是一个劳动密集型过程,这涉及为每个问题创建包含首选答案和拒绝答案的数据集,以支持基于反馈的学习技术。
因此,我们构建了 Uniflow,一个统一的大语言模型接口,用于提取和转换原始文档。
:seedling: 使用案例
Uniflow 旨在帮助每个数据科学家生成自己的隐私保护、可直接使用的训练数据集,用于大语言模型微调,从而使大语言模型微调对每个人都更加accessible:rocket:。
查看 Uniflow 的实践解决方案:
- 提取财务报告(PDF)并进行总结
- 提取财务报告(PDF)并微调财务大语言模型
- 从数学书(HTML)中提取问答数据集
- 从 PDF 中提取问答数据集
- 构建用于大语言模型微调的 RLHF/RLAIF 偏好数据集
:computer: 安装
安装 uniflow 大约需要 5-10 分钟,只需按照以下 3 个步骤操作:
-
在终端上使用以下命令创建 conda 环境:
conda create -n uniflow python=3.10 -y conda activate uniflow # 某些操作系统可能需要使用 `source activate uniflow` -
根据您的操作系统安装兼容的 pytorch。
- 如果您使用 GPU,请根据您的 CUDA 版本安装 pytorch。您可以通过
nvcc -V查看 CUDA 版本。pip3 install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu121 # cu121 表示 cuda 12.1 - 如果您使用 CPU 实例,
pip3 install torch
- 如果您使用 GPU,请根据您的 CUDA 版本安装 pytorch。您可以通过
-
安装
uniflow:pip3 install uniflow-
(可选)如果您运行以下
OpenAI流程之一,您需要设置 OpenAI API 密钥。为此,在 uniflow 根文件夹中创建一个.env文件。然后在.env文件中添加以下行:OPENAI_API_KEY=YOUR_API_KEY -
(可选)如果您运行
HuggingfaceModelFlow,您还需要安装transformers、accelerate、bitsandbytes和scipy库:pip3 install transformers accelerate bitsandbytes scipy -
(可选)如果您运行
LMQGModelFlow,您还需要安装lmqg和spacy库:pip3 install lmqg spacy
-
恭喜您完成了安装!
:man_technologist: 开发设置
如果您有兴趣为我们做出贡献,以下是初步的开发设置。
conda create -n uniflow python=3.10 -y
conda activate uniflow
cd uniflow
pip3 install poetry
poetry install --no-root
AWS EC2 开发环境设置
如果您使用EC2,可以使用以下配置启动GPU实例:
- EC2
g4dn.xlarge(如果您想运行一个预训练的7B参数的LLM) - Deep Learning AMI PyTorch GPU 2.0.1(Ubuntu 20.04)
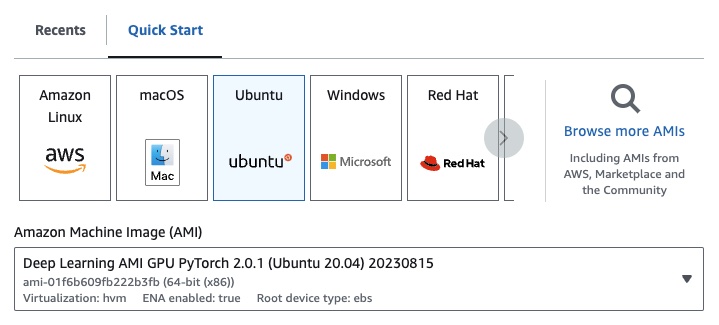
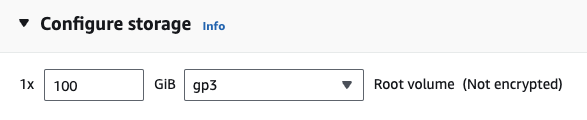
- EBS:至少100G
API密钥
如果您运行以下OpenAI流程之一,您需要设置OpenAI API密钥。
为此,在您的根uniflow文件夹中创建一个.env文件。然后在.env文件中添加以下行:
OPENAI_API_KEY=YOUR_API_KEY
:scroll: Uniflow使用手册
概述
使用uniflow需要遵循以下三个主要步骤:
-
选择
Config
这决定了LLM和不同的可配置参数。 -
构建您的
Prompts
构建您想用来提示模型的上下文。您可以使用PromptTemplate类配置自定义指令和示例。 -
运行您的
Flow
在您的输入数据上运行流程,并从您的LLM生成输出。
注:我们目前正在构建
Preprocessing流程,以帮助处理来自不同源的数据,如html、Markdown等。
1. Config
Config决定使用哪个LLM以及如何序列化和反序列化输入数据。它还包含特定于LLM的参数。
以下是您可以使用的不同预定义配置及其对应的LLM:
| Config | LLM |
|---|---|
| Config | gpt-3.5-turbo-1106 |
| OpenAIConfig | gpt-3.5-turbo-1106 |
| HuggingfaceConfig | mistralai/Mistral-7B-Instruct-v0.1 |
| LMQGConfig | lmqg/t5-base-squad-qg-ae |
您可以使用默认设置运行每个配置,也可以为您的用例向配置传入自定义参数,如temperature或batch_size。有关更多详细信息,请参阅高级自定义配置部分。
2. Prompting
默认情况下,uniflow设置为根据您传入的Context生成问题和答案。为此,它使用默认指令和少量示例来指导LLM。
以下是默认指令:
根据最后一个示例中的最后一个上下文生成一个问题及其对应的答案。按照以下示例的格式在响应中包含上下文、问题和答案
以下是默认的少量示例:
context="敏捷的棕色狐狸跳过懒惰的棕色狗。",
question="狐狸的颜色是什么?",
answer="棕色。"
context="敏捷的棕色狐狸跳过懒惰的黑色狗。",
question="狗的颜色是什么?",
answer="黑色。"
要使用这些默认指令和示例运行,您只需要向流程传递一个Context对象列表。uniflow然后会为每个Context对象生成一个包含指令和少量示例的自定义提示,以发送给LLM。有关更多详细信息,请参阅运行流程部分。
Context
Context类用于传递LLM提示的上下文。Context包含一个context属性,它是一个文本字符串。
要使用默认指令和少量示例运行uniflow,您可以向流程传递一个Context对象列表。例如:
from uniflow.op.prompt import Context
data = [
Context(
context="敏捷的棕色狐狸跳过懒惰的棕色狗。",
),
...
]
client.run(data)
有关运行流程的更详细概述,请参阅运行流程部分。
PromptTemplate
如果您想使用自定义提示指令或少量示例运行,可以使用PromptTemplate对象。它具有instruction和example属性。
| 属性 | 类型 | 描述 |
|---|---|---|
instruction | str | LLM的详细指令 |
examples | List[Context] | 少量示例 |
您可以根据需要覆盖任何默认值。
要查看如何使用PromptTemplate运行uniflow,使用自定义instruction、少量示例和自定义Context字段来生成摘要的示例,请查看openai_pdf_source_10k_summary notebook
运行流程
一旦您决定了Config和提示策略,就可以在输入数据上运行流程。
-
导入
uniflowClient、Config和Context对象。from uniflow.flow.client import TransformClient from uniflow.flow.config import TransformOpenAIConfig, OpenAIModelConfig from uniflow.op.prompt import Context -
将您的数据预处理成块以传入流程。将来我们会有
Preprocessing流程来帮助完成这一步,但现在您可以使用您选择的库,如pypdf,来分块您的数据。raw_input_context = ["今天是个阳光明媚的日子,天空是蓝色的。", "我叫鲍比,是一名从事AI/ML工作的优秀软件工程师。"] -
创建一个
Context对象列表,将您的数据传入流程。data = [ Context(context=c) for c in raw_input_context ] -
[可选] 如果您想使用自定义指令和/或示例,请创建一个
PromptTemplate。from uniflow.op.prompt import PromptTemplate
guided_prompt = PromptTemplate( instruction="根据以下最后一段上下文生成一句话摘要。按照下面示例的格式在回复中包含上下文和摘要", few_shot_prompt=[ Context( context="当你按照创造者的日程工作时,会议是一场灾难。一个会议可能会毁掉整个下午,因为它把时间分成两块,每块都太小,无法完成任何艰难的工作。而且你还得记住去参加会议。对于按管理者日程工作的人来说,这不是问题。每个小时总有事情要做;唯一的问题是做什么。但当一个按创造者日程工作的人有会议时,他们不得不考虑这件事。", summary="会议扰乱了遵循创造者日程的人的生产力,将他们的时间分割成不实用的片段,而遵循管理者日程的人则习惯于连续不断的任务流。", ), ], )
1. 创建一个`Config`对象以传递给`Client`对象。
config = TransformOpenAIConfig( prompt_template=guided_prompt, model_config=OpenAIModelConfig( response_format={"type": "json_object"} ), ) client = TransformClient(config)
2. 使用`client`对象在输入数据上运行流程。
output = client.run(data)
3. 处理输出数据。默认情况下,LLM输出将是一个输出字典列表,每个传入流程的`Context`对应一个字典。每个字典都有一个`response`属性,包含LLM响应以及任何错误。例如,`output[0]['output'][0]`看起来会像这样:
{ 'response': [{'context': '那天阳光明媚,天空颜色是蓝色的。', 'question': '天空的颜色是什么?', 'answer': '蓝色。'}], 'error': '没有错误。' }
## 示例
更多示例,请参见[example](./example/model)文件夹。
## 高级自定义配置
如果你想进一步调整特定参数,如LLM模型、线程数、温度等,你也可以通过向`Config`对象传递自定义配置或参数来配置流程。
每个配置都有以下参数:
| 参数 | 类型 | 描述 |
| ------------- | ------------- | ------------- |
| `prompt_template` | `PromptTemplate` | 用于引导提示的模板。 |
| `num_threads` | int | 流程使用的线程数。 |
| `model_config` | `ModelConfig` | 传递给模型的配置。 |
你可以通过传入一个带有自定义参数的`Model Configs`来进一步配置`model_config`。
### 模型配置
__模型配置__是传递给基础`Config`对象的配置,决定使用哪个LLM模型,并包含特定于该LLM模型的参数。
#### ModelConfig
基础配置称为`ModelConfig`,具有以下参数:
| 参数 | 类型 | 默认值 | 描述 |
| ------------- | ------------- | ------------- | ------------- |
| `model_name` | str | gpt-3.5-turbo-1106 | [OpenAI网站](https://platform.openai.com/docs/models/gpt-3-5) |
#### OpenAIModelConfig
`OpenAIModelConfig`继承自`ModelConfig`,并有以下附加参数:
| 参数 | 类型 | 默认值 | 描述 |
| ------------- | ------------- | ------------- | ------------- |
| `num_calls` | int | 1 | 对OpenAI API的调用次数。 |
| `temperature` | float | 1.5 | 用于OpenAI API的温度。 |
| `response_format` | Dict[str, str] | {"type": "text"} | 用于OpenAI API的响应格式。可以是"text"或"json" |
#### HuggingfaceModelConfig
`HuggingfaceModelConfig`继承自`ModelConfig`,但默认覆盖`model_name`参数以使用`mistralai/Mistral-7B-Instruct-v0.1`模型。
| 参数 | 类型 | 默认值 | 描述 |
| ------------- | ------------- | ------------- | ------------- |
| `model_name` | str | mistralai/Mistral-7B-Instruct-v0.1 | [Hugging Face网站](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) |
| `batch_size` | int | 1 | 用于Hugging Face API的批处理大小。 |
#### LMQGModelConfig
`LMQGModelConfig`继承自`ModelConfig`,但默认覆盖`model_name`参数以使用`lmqg/t5-base-squad-qg-ae`模型。
| 参数 | 类型 | 默认值 | 描述 |
| ------------- | ------------- | ------------- | ------------- |
| `model_name` | str | lmqg/t5-base-squad-qg-ae | [Hugging Face网站](https://huggingface.co/lmqg/t5-base-squad-qg-ae) |
| `batch_size` | int | 1 | 用于LMQG API的批处理大小。 |
### 自定义配置示例
以下是如何向`Client`对象传递自定义配置的示例:
from uniflow.flow.client import TransformClient from uniflow.flow.config import TransformOpenAIConfig, OpenAIModelConfig from uniflow.op.prompt import Context
contexts = ["那天阳光明媚,天空颜色是蓝色的。", "我叫鲍比,是一名从事AI/ML工作的优秀软件工程师。"]
data = [ Context( context=c ) for c in contexts ]
config = OpenAIConfig( num_threads=2, model_config=OpenAIModelConfig( model_name="gpt-4", num_calls=2, temperature=0.5, ), ) client = TransformClient(config) output = client.run(data)
如你所见,我们根据需求向`OpenAIConfig`配置传递了自定义参数的`OpenAIModelConfig`。











