
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文GIFfusion 💥

Giffusion是一个使用Stable Diffusion生成GIF和视频的Web界面。

运行方法
在Colab中
打开上面链接的Colab笔记本,按照说明启动Giffusion界面
在本地机器上
克隆Giffusion仓库
git clone https://github.com/DN6/giffusion.git && cd giffusion
安装依赖
pip install -r requirements.txt
启动应用
python app.py
功能
保存和加载会话
Giffusion使用Hugging Face Hub保存输出生成和设置。要保存和加载会话,首先需要使用huggingface-cli login设置Hugging Face访问令牌。
设置完成后,可以通过点击会话设置中的保存会话按钮来保存会话。这将在Hub上创建一个数据集仓库,并将设置和输出生成保存到一个随机生成名称的文件夹中。您也可以手动设置Repo ID和会话名称,以将会话保存到特定仓库。
加载会话的方式类似。只需提供要加载的会话的Repo ID和会话名称,然后点击加载会话按钮。您可以使用下拉选择器筛选界面中各个组件的设置。
自带管道
Giffusion支持使用Diffusers库中的任何管道和兼容的检查点。只需在管道设置中粘贴检查点名称和管道名称即可。
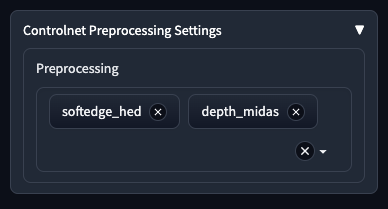
ControlNet支持
Giffusion允许使用StableDiffusionControlNetPipeline。只需粘贴要在管道中使用的ControlNet检查点即可加载。
还支持MultiControlnet。只需粘贴Hugging Face Hub中的模型检查点路径列表
lllyasviel/control_v11p_sd15_softedge, lllyasviel/control_v11f1p_sd15_depth
预处理说明: 使用Controlnets时,需要在将输入用作模型的条件信号之前对其进行预处理。Controlnet预处理设置允许您选择一组预处理选项来应用于图像。请确保按照Controlnet模型的顺序选择它们。例如,对于上面的代码片段,您需要在深度预处理器之前选择软边缘预处理器。如果在MultiControlnet设置中使用不需要处理的Controlnet模型,还提供了无处理选项。
自定义管道支持
您也可以在Giffusion中使用自己的自定义管道。只需在自定义管道部分粘贴管道文件的路径即可。管道文件必须遵循类似于Diffusers中的社区管道的格式。
Compel提示权重支持
现在通过Compel生成提示嵌入,并支持此处概述的权重语法。
多帧生成
Giffusion遵循类似于Deforum Art的Stable Diffusion笔记本中使用的提示语法
0: 一张柯基犬的图片
60: 一张狮子的图片
提示的第一部分表示关键帧编号,冒号后的文本是模型用来生成图像的提示。 在上面的例子中,我们要求模型在第0帧生成一只柯基犬的图片,在第60帧生成一头狮子的图片。那么,这两个关键帧之间的所有图像是如何生成的呢?
你可能还记得,扩散模型的工作原理是将噪声转化为图像。Stable Diffusion将噪声张量转换为潜在嵌入,以在运行扩散过程时节省时间和内存。这个潜在嵌入被输入到解码器中以生成图像。
我们模型的输入是噪声张量和文本嵌入张量。以我们的关键帧作为起点和终点,我们可以通过插值这些张量来生成这些帧之间的图像。

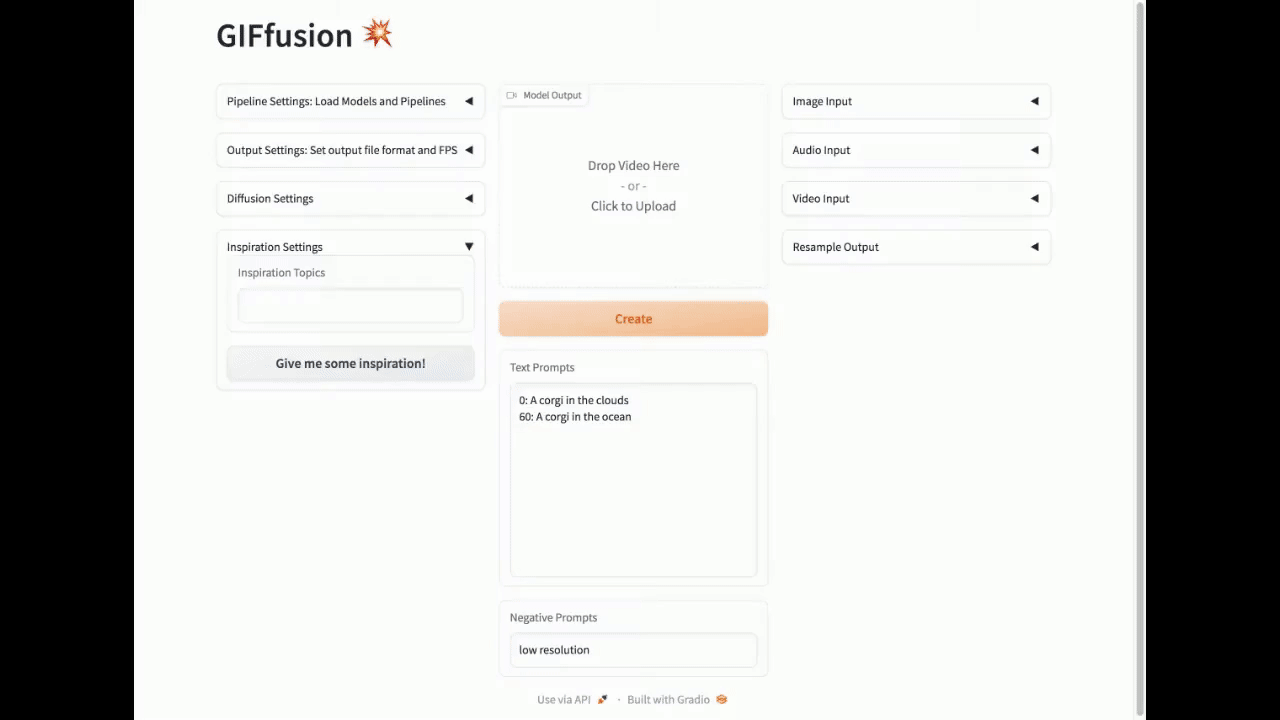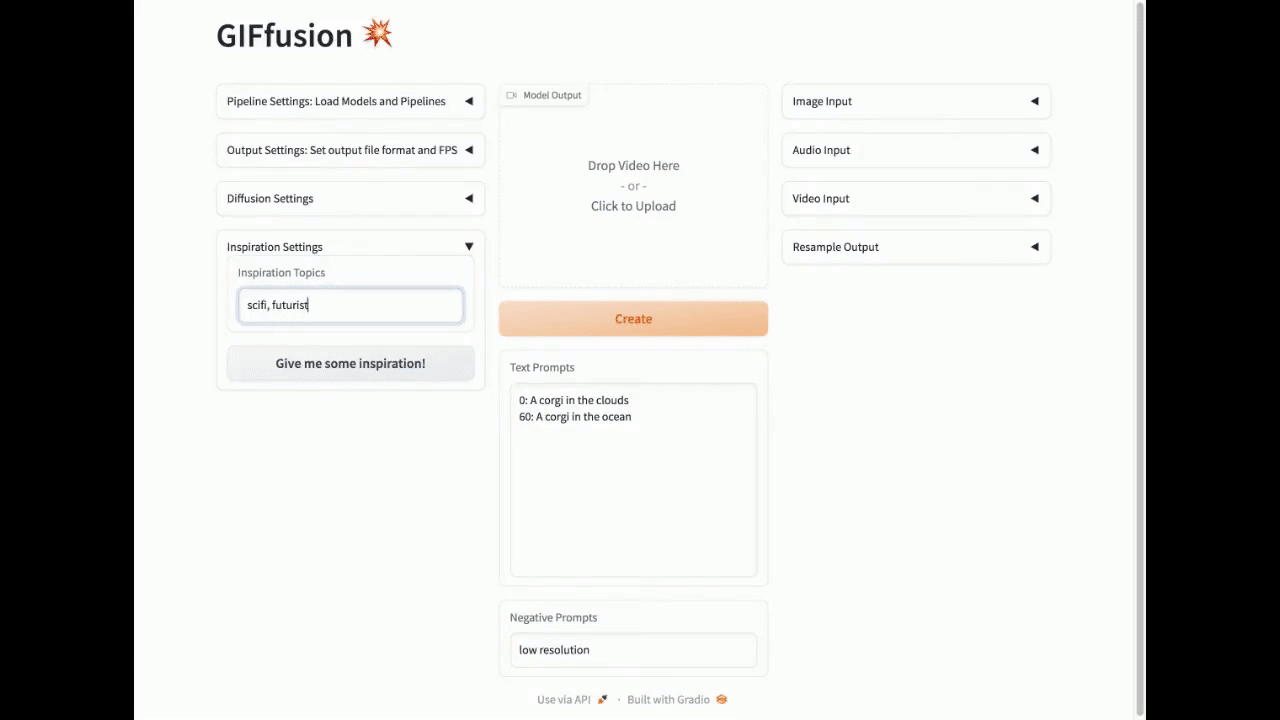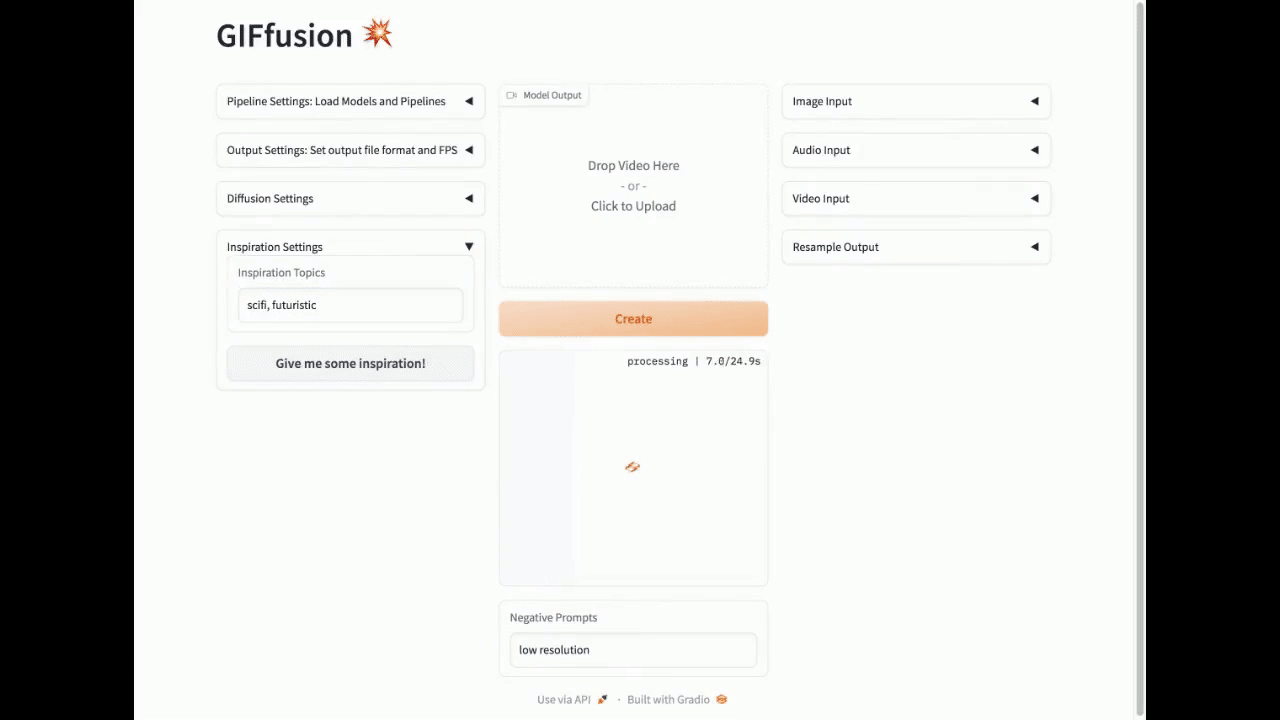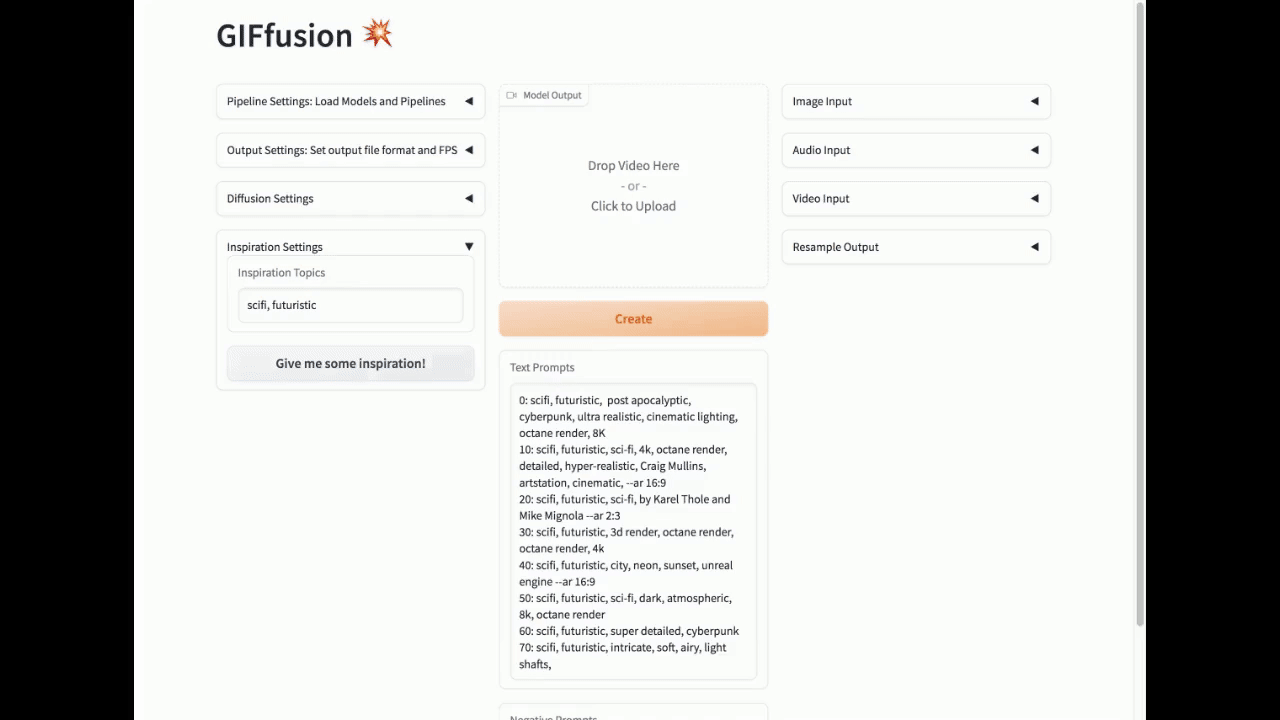
灵感按钮
创建提示可能具有挑战性。点击"给我一些灵感"按钮可以自动为你生成提示。
你甚至可以提供一个主题列表,让灵感按钮用作起点。
多媒体支持
使用额外的媒体输入来增强图像生成过程

音频输入
使用音频驱动你的GIF和视频动画。
https://user-images.githubusercontent.com/7529846/204550897-70777873-30ca-46a9-a74e-65b6ef429958.mp4
要使用音频驱动你的动画,
- 转到"音频输入"下拉菜单并上传你的音频文件。
- 点击"获取关键帧信息"。这将根据你选择的"音频组件"从音频中提取关键帧。你可以根据文件的打击乐、和声或组合音频组件提取关键帧。
此外,还会提取这些关键帧的时间戳信息以供参考,以防你想将提示与音频中的特定时间同步。
注意: 关键帧会根据你在UI中设置的帧率而变化。
视频输入
你可以使用现有视频的帧作为扩散过程中的初始图像。
https://user-images.githubusercontent.com/7529846/204550451-5d2162dc-5d6b-4ecd-b1ed-c15cb56bc224.mp4
使用视频初始化:
-
转到"视频输入"下拉菜单
-
上传你的文件。点击"获取关键帧信息"以提取视频中存在的最大帧数,并将UI中的帧率设置更新为与输入视频的帧率匹配。
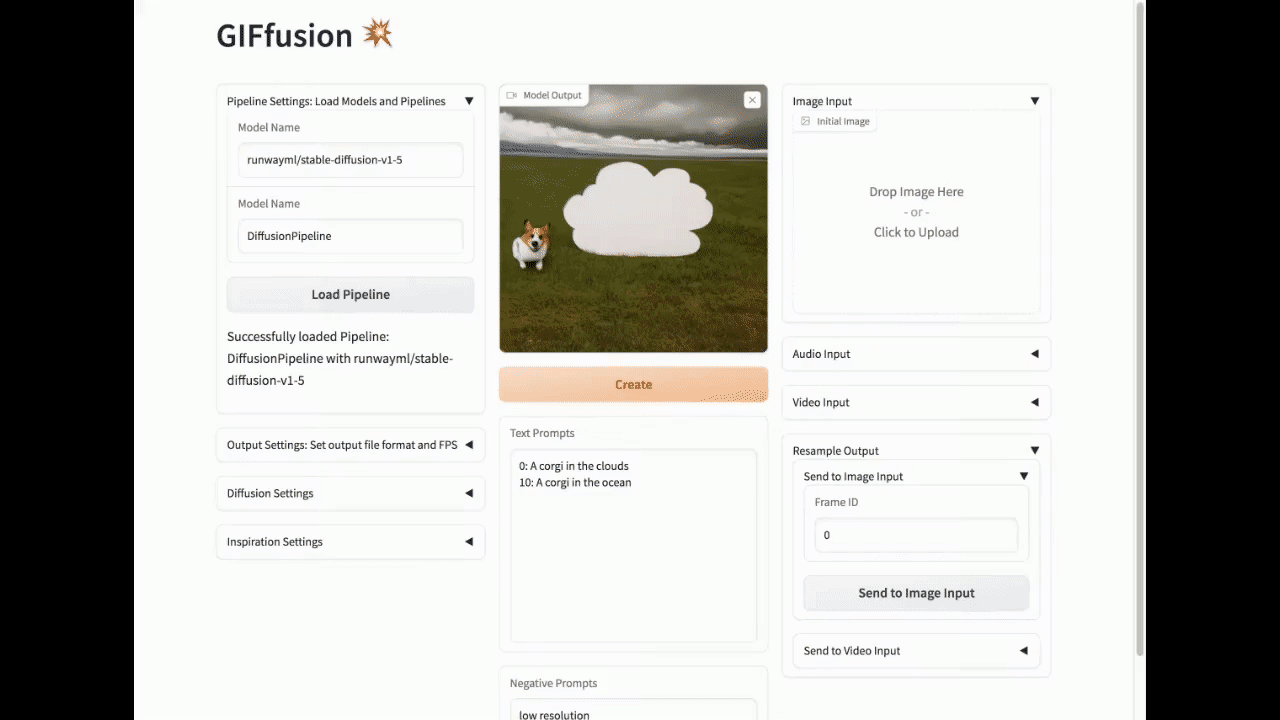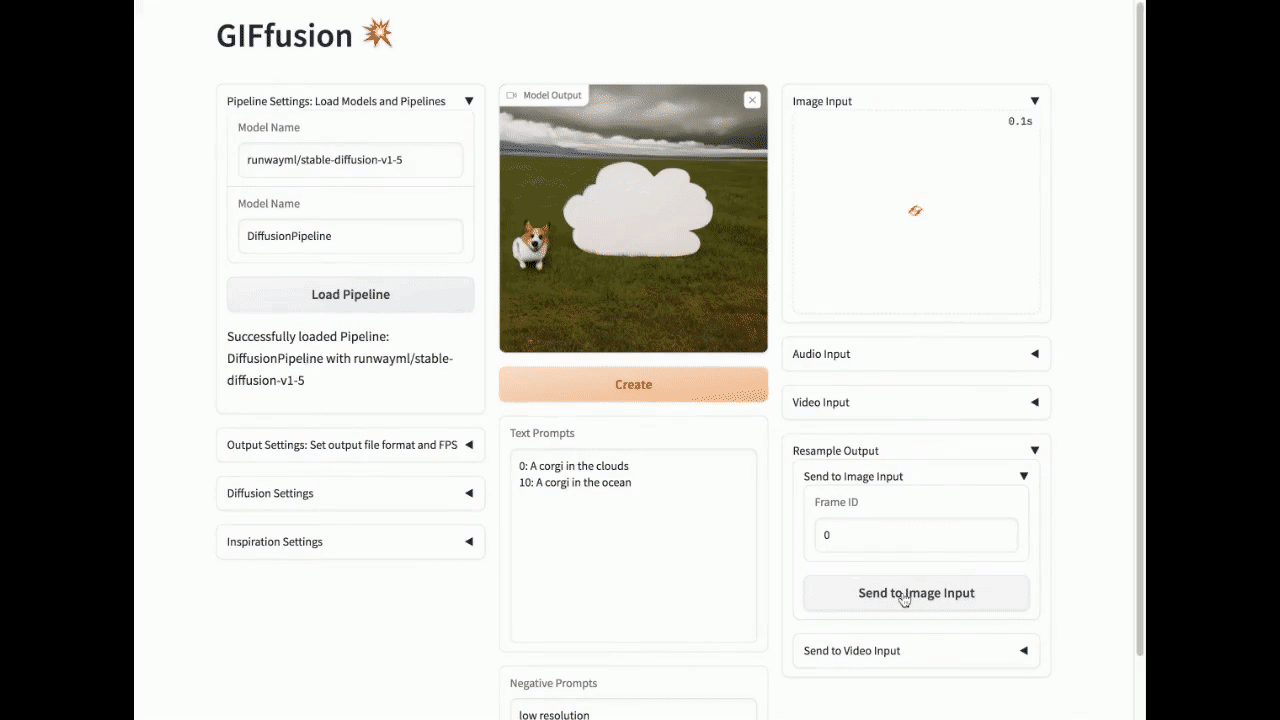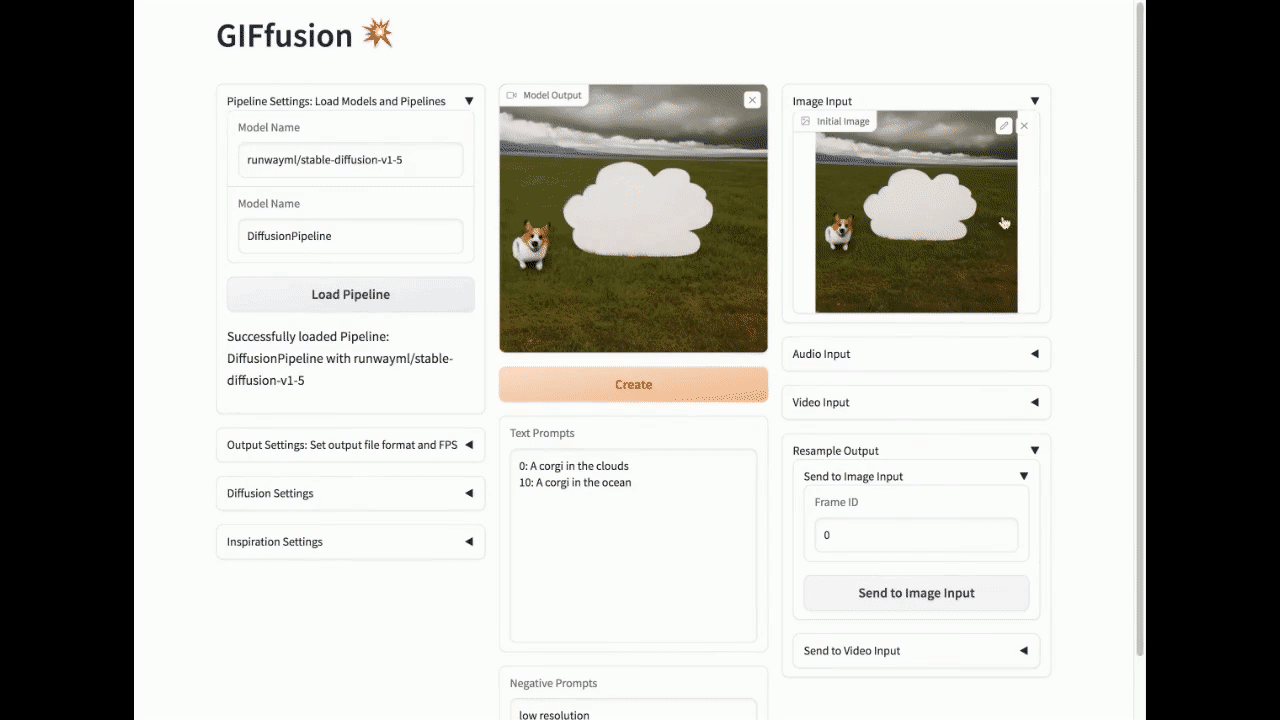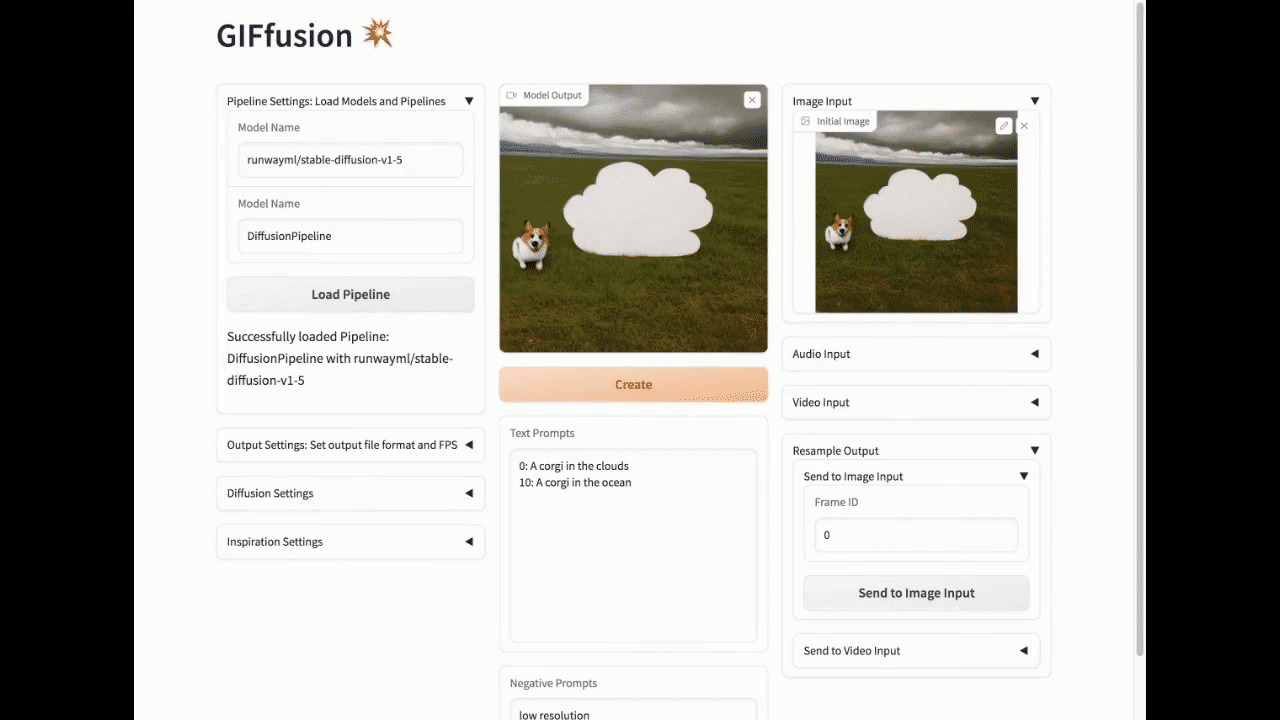
重新采样输出生成
你可以重新采样在输出标签中创建的视频和GIF,并将它们发送到图像输入或视频输入。
重新采样到图像输入
要从视频中采样图像,请选择要从输出视频或GIF中采样的帧ID,然后点击"发送到图像输入"
重新采样到视频输入
要重新采样视频,请点击"发送到视频输入"

保存到 Comet
GIFfusion 还支持将提示词、生成的 GIF/视频、图像和设置保存到 Comet,这样你就可以跟踪你的生成实验。
扩散设置
本节涵盖扩散设置下拉菜单中的所有组件。
-
使用固定潜在向量: 在整个生成过程中为每一帧使用相同的噪声潜在向量。如果你只想在提示词嵌入之间进行插值而保持噪声潜在向量不变,这个选项会很有用。
-
使用提示词嵌入: 默认情况下,Giffusion 将你的提示词转换为嵌入,并在帧之间的提示词嵌入之间进行插值。如果你禁用此选项,Giffusion 将会在帧之间前向填充文本提示词。如果你使用
ComposableDiffusion管道或想直接使用管道的提示词嵌入功能,请禁用此选项。 -
数字种子: 用于噪声潜在向量生成过程的种子。如果没有设置
使用固定潜在向量,这个种子将用于生成一个为每个关键帧提供唯一种子的计划。 -
迭代步数: 在生成过程中使用的步数。
-
无分类器引导比例: 更高的引导比例会鼓励生成与文本提示密切相关的图像,通常以降低图像质量为代价。
-
图像强度计划: 表示对参考图像进行变换的程度。必须在 0 和 1 之间。较大的强度值将执行更多的去噪步骤。这仅适用于
Img2Img类型的管道。计划遵循与运动输入类似的格式。例如,0:(0.5), 10:(0.7)将在第 0 帧到第 10 帧之间将强度值从0.5增加到0.7。 -
使用默认管道调度器: 选择使用已预先配置好的管道调度器。
-
调度器: 调度器接收训练模型的输出、扩散过程正在迭代的样本和时间步长,以返回去噪后的样本。不同的调度器需要不同数量的迭代步骤来产生好的结果。使用此选择器来尝试不同的调度器和管道。
-
调度器参数: 传递给所选调度器的额外关键字参数。
-
批量大小: 设置生成过程中使用的批量大小。如果你有访问内存更大的 GPU 的权限,可以增加批量大小来提高生成过程的速度。
-
图像高度: 默认情况下,生成的图像高度为 512 像素。某些模型和管道支持生成更高分辨率的图像。调整此设置以适应这些配置。如果提供了图像或视频输入,高度将设置为原始输入的高度。
-
图像宽度: 默认情况下,生成的图像宽度为 512 像素。某些模型和管道支持生成更高分辨率的图像。调整此设置以适应这些配置。如果提供了图像或视频输入,宽度将设置为原始输入的宽度。
-
潜在通道数: 这用于设置噪声潜在向量的通道维度。某些管道,例如
InstructPix2Pix,要求潜在通道数与 Unet 模型的输入通道数不同。默认值4应该适用于大多数管道和模型。 -
额外管道参数: Diffuser 管道根据任务支持各种参数。使用此文本框输入一个字典值,该值将作为关键字参数传递给管道对象。例如,将图像引导比例参数传递给 InstructPix2PixPipeline。
动画设置
插值类型
Giffusion 通过首先为提供的关键帧生成提示词嵌入和初始潜在向量,然后使用球面插值来插入中间值来生成动画。控制插值值之间变化率的计划默认为 线性。
你可以使用此下拉菜单将此计划更改为 正弦 或 曲线。
正弦:
使用 正弦 计划将在你的起始和结束潜在向量和嵌入之间使用以下函数进行插值 np.sin(np.pi * frequency) ** 2,默认频率值为 1.0。这将产生一个单一振荡,使生成的输出从你的起始提示词移动到结束提示词,然后再返回。将频率加倍会使振荡次数加倍。
正弦插值还支持使用多个频率。在 插值参数 中输入 1.0, 2.0 将组合这两个频率的正弦波。
正弦插值

你也可以使用Chigozie Nri的关键帧DSL手动定义动画的插值曲线,该DSL遵循Deforum格式。
一个示例曲线如下:
0: (0.0), 50: (1.0), 60: (0.5)
曲线值必须在0.0到1.0之间。
动作设置
Giffusion允许你使用关键帧动画字符串来控制图像在各帧之间的角度、缩放和平移。这些动画字符串遵循与Deforum完全相同的格式。目前,Giffusion仅支持2D动画,并允许你控制以下参数:
- 缩放:以乘法方式调整画布大小。1表示静态,大于1的数值表示向前移动,小于1的数值表示向后移动。
- 角度:每帧顺时针或逆时针旋转画布的度数。此参数使用正值表示逆时针旋转,负值表示顺时针旋转。
- X轴平移:X方向上移动的像素数。向左或向右移动画布。此参数使用正值表示向右移动,负值表示向左移动。
- Y轴平移:Y方向上移动的像素数。向上或向下移动画布。此参数使用正值表示向上移动,负值表示向下移动。
缩放参数示例
0: (1.05),1: (1.05),2: (1.05),3: (1.05),4: (1.05),5: (1.05),6: (1.05),7: (1.05),8: (1.05),9: (1.05),10: (1.05)
角度参数示例
0: (10.0),1: (10.0),2: (10.0),3: (10.0),4: (10.0),5: (10.0),6: (10.0),7: (10.0),8: (10.0),9: (10.0),10: (10.0)
X/Y轴平移参数示例
0: (5.0),1: (5.0),2: (5.0),3: (5.0),4: (5.0),5: (5.0),6: (5.0),7: (5.0),8: (5.0),9: (5.0),10: (5.0)
一致性
一致性是一种在创建动画时在各帧之间保持特征的方法。它仅适用于在运行扩散过程时产生潜在编码的模型。为了实现这一点,我们计算当前潜在编码相对于参考潜在编码(通常是前一帧的潜在编码)的梯度。
# 计算当前潜在编码相对于参考潜在编码的梯度
for step in range(coherence_steps):
loss = (latents - reference_latent).pow(2).mean()
cond_grad = torch.autograd.grad(loss, latents)[0]
latents = latents - (coherence_scale * cond_grad)
# 根据一致性alpha值更新参考潜在编码
reference_latent = (coherence_alpha * latents) + (
1.0 - coherence_alpha
) * reference_latent
- 一致性比例: 增加此值将使当前帧看起来更像参考帧。
- 一致性alpha: 控制当前帧的潜在编码与参考帧的潜在编码的混合程度。增加该值将在计算梯度时更多地考虑最近的帧。
- 一致性步骤: 在扩散过程中应用回调的频率。例如,将其设置为2,将在扩散过程的每两个步骤运行一次回调。
- 噪声调度: 为了扩散多样性而添加到潜在编码的噪声量。较高的值会导致更多的多样性。仅当一致性大于0.0时才应用噪声。
- 应用颜色匹配: 使用第一个生成的帧作为参考,对当前帧应用LAB直方图颜色匹配。这有助于减少生成过程中图像之间的剧烈颜色变化。
输出设置
- 输出格式: 将输出格式设置为GIF或MP4视频。
- 帧率: 设置输出的帧率。
参考资料
没有以下资源,Giffusion将无法实现 ❤️
- 提示词格式基于Deforum Art的工作
- 灵感按钮使用DoEvent开发的Midjourney提示词生成器空间
- 带有音频响应的Stable Diffusion视频
- Comet ML项目,展示了一些使用Giffusion制作的作品
- Gradio文档:本项目的用户界面是使用Gradio构建的
- Hugging Face Diffusers
- Keyframed用于曲线插值











