
 Github
Github 论文
论文ProFusion
ProFusion(使用在大型数据集如CC3M上预训练的编码器)可用于高效构建定制数据集,该数据集可用于训练无需微调的定制助手(CAFE)。
给定一张测试图像,该助手可以以无需微调的方式执行定制生成。它可以处理复杂的用户输入,生成文本解释和详细说明以及图像,无需任何微调。

CAFE 的结果

CAFE 的结果
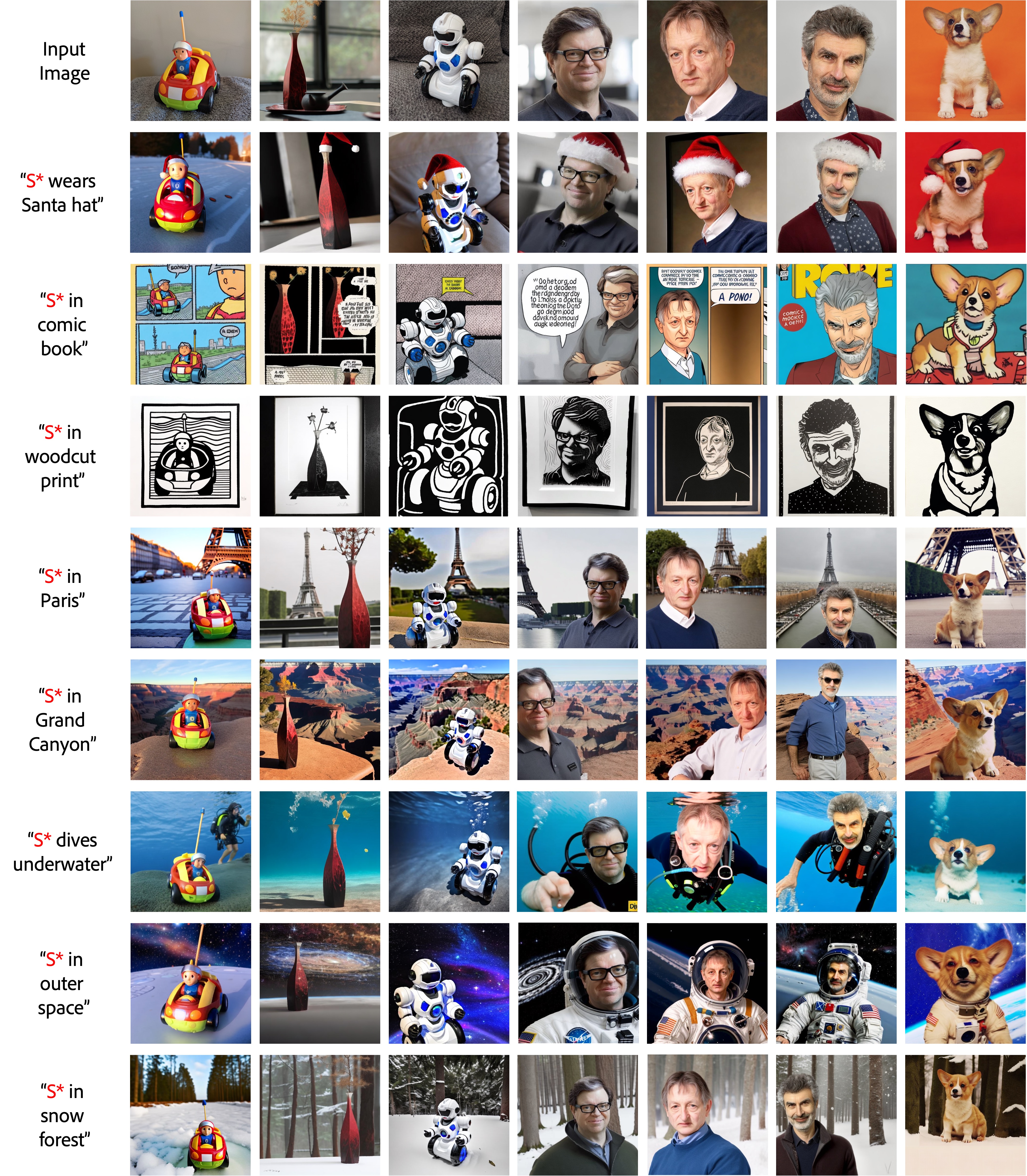
ProFusion 的结果
ProFusion 是一个用于定制预训练大规模文本到图像生成模型的框架,在我们的示例中使用的是Stable Diffusion 2。
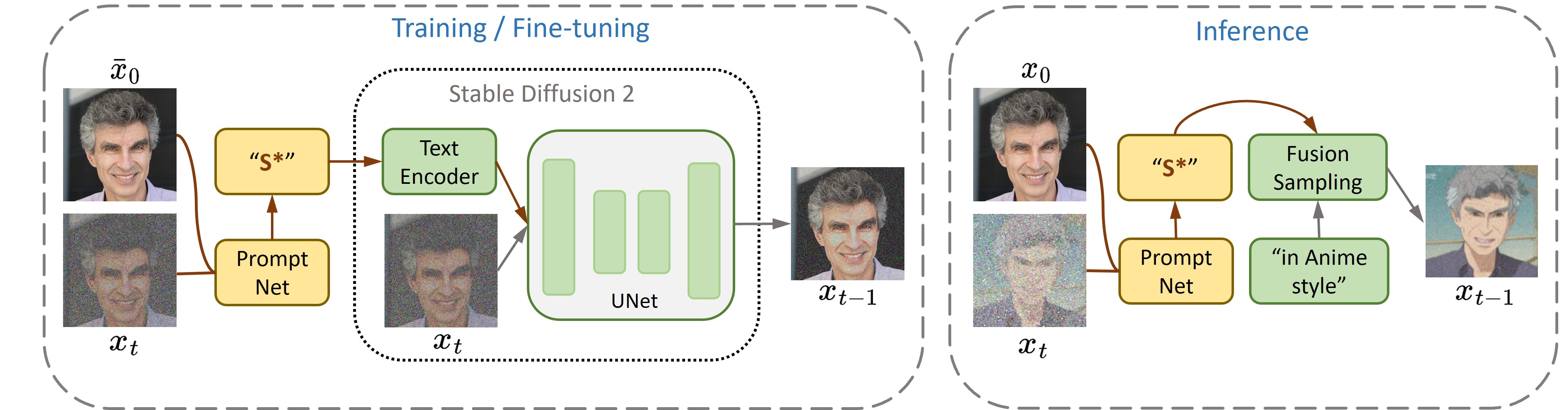
ProFusion 的示意图
使用 ProFusion,您可以使用单张测试图像,在单个 GPU 上(微调时批量大小为 1 需要约 20GB 显存)为新颖/独特的概念生成无限数量的创意图像。

ProFusion 的结果
示例
-
安装依赖项(我们修改了原始的 diffusers);
cd ./diffusers pip install -e . cd .. pip install accelerate==0.16.0 torchvision transformers==4.25.1 datasets ftfy tensorboard Jinja2 regex tqdm joblib -
初始化 Accelerate;
accelerate config -
使用测试图像定制模型,示例见 test.ipynb 笔记本;
训练您自己的编码器
如果您想为其他领域或在您自己的数据集上训练 PromptNet 编码器。
-
首先,准备一个仅包含图像的数据集;
-
然后,运行
accelerate launch --mixed_precision="fp16" train.py\ --pretrained_model_name_or_path="stabilityai/stable-diffusion-2-base" \ --train_data_dir=./images_512 \ --max_train_steps=80000 \ --learning_rate=2e-05 \ --output_dir="./promptnet" \ --train_batch_size=8 \ --promptnet_l2_reg=0.000 \ --gradient_checkpointing
引用
@article{zhou2023enhancing,
title={Enhancing Detail Preservation for Customized Text-to-Image Generation: A Regularization-Free Approach},
author={Zhou, Yufan and Zhang, Ruiyi and Sun, Tong and Xu, Jinhui},
journal={arXiv preprint arXiv:2305.13579},
year={2023}
}











