
 Github
Github Huggingface
Huggingface 论文
论文Huatuo-26M
📃 论文 • 🤗 Huatuo-Lite • 🤗 华佗百科问答 • 🤗 知识图谱问答 • 🤗 华佗咨询问答
中文 | 英文
👩🏻⚕简介
- Huatuo-26M 是目前最大的中文医疗问答数据集。该数据集包含超过2600万个高质量的医疗问答对,涵盖了疾病、症状、治疗方法和药物信息等多个方面。
- Huatuo-Lite 是基于 Huatuo-26M 精炼和优化的数据集,经过多次净化和重写。它具有更多的数据维度和更高的数据质量。
📚数据内容
Huatuo-26M 数据集从多个来源收集和整合,包括:
- 在线医学百科 huatuo_encyclopedia_qa
- 在线医学知识库 huatuo_knowledge_graph_qa
- 在线医疗咨询记录(答案以URL形式给出) huatuo_consultation_qa
- 精简版 Huatuo-Lite
数据集中的每个问答对包含以下字段:
- questions:问题描述
- answers:医生/专家回答
- Huatuo-Lite 数据集还包括医院科室和相关疾病字段
以下是我们在论文中使用的华佗测试集,由多个来源的数据随机抽样组成。
- 测试数据集:huatuo26M-testdatasets
🤖数据使用
Huatuo-26M 数据集可用于医疗领域的各种 AI 研究和应用,例如:
- 自然语言处理:包括但不限于问答系统、文本分类、情感分析等。
- 机器学习模型训练:如疾病预测、个性化治疗推荐等。
- 医疗领域的 AI 应用:如智能诊断系统、医疗咨询聊天机器人等。
🚀快速开始
要开始使用 Huatuo-26M 数据集,您可以按照以下步骤操作:
import datasets
# 第1部分
knowledge_graph_dataset = datasets.load_dataset('FreedomIntelligence/huatuo_knowledge_graph_qa')
# 第2部分
encyclopedia_dataset = datasets.load_dataset('FreedomIntelligence/huatuo_encyclopedia_qa')
# 第3部分(仅URL)
consultation_dataset = datasets.load_dataset('FreedomIntelligence/huatuo_consultation_qa')
# 测试数据集(6k)
huatuo_testdatasets = datasets.load_dataset('FreedomIntelligence/huatuo26M-testdatasets')
👩🏻🔬实验记录
基准测试
-
检索评估:
点击展开
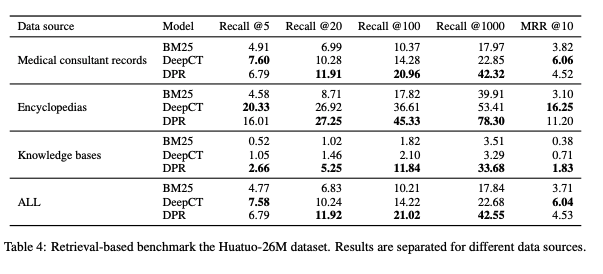
-
答案生成评估:
点击展开
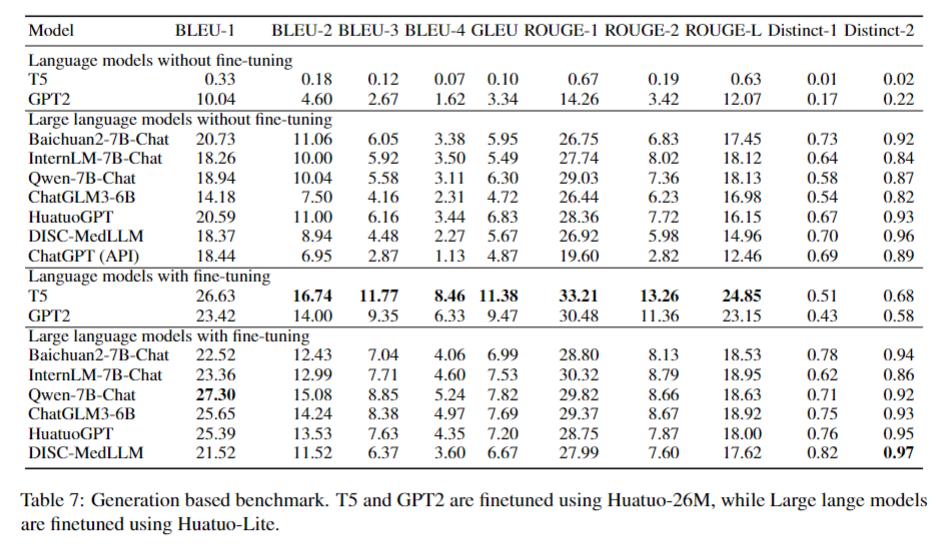
应用
-
零样本迁移到其他问答数据集:
点击展开
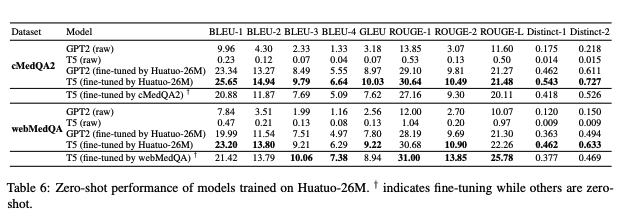
-
作为RAG的外部知识:
点击展开
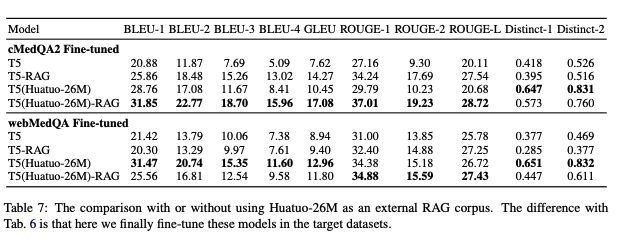
-
作为语言模型(LM)的预训练数据:
点击展开
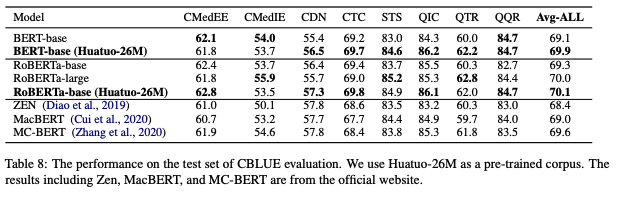
-
作为医疗LLM的微调数据:
点击展开
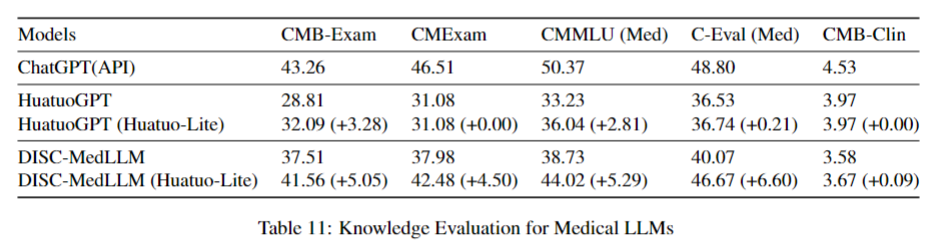
🚁许可证
Huatuo-26M 数据集采用 Apache 2.0 许可证。在使用之前,请确保您已阅读并同意许可条款。
📱联系我们
如果您有任何问题或需要帮助,请随时通过电子邮件(xidongw@163.com)或在Issues部分询问我们。
😁引用
@misc{li2023huatuo26m,
title={Huatuo-26M, a Large-scale Chinese Medical QA Dataset},
author={Jianquan Li and Xidong Wang and Xiangbo Wu and Zhiyi Zhang and Xiaolong Xu and Jie Fu and Prayag Tiwari and Xiang Wan and Benyou Wang},
year={2023},
eprint={2305.01526},
archivePrefix={arXiv},
primaryClass={cs.CL}
}











