
 Github
Github 文档
文档CBook-150K
中文图书语料集合
此语料集合基于网上开源的MD5图书链接获取
MD5链接
├── CBOOK_MD5
├── MD5_0_9999
├── MD5_0_999.txt
├── MD5_1000_1999.txt
├── ...
├── MD5_9000_9999.txt
├── MD5_10000_19999
├── MD5_10000_10999.txt
├── MD5_11000_11999.txt
├── ...
├── MD5_15000_15999.txt
├── ...
├── MD5_140000_149999
├── MD5_140000_140999.txt
├── MD5_141000_141999.txt
├── ...
├── MD5_149000_149999.txt
MD5快传插件
- 插件下载安装后即可在百度云盘内使用
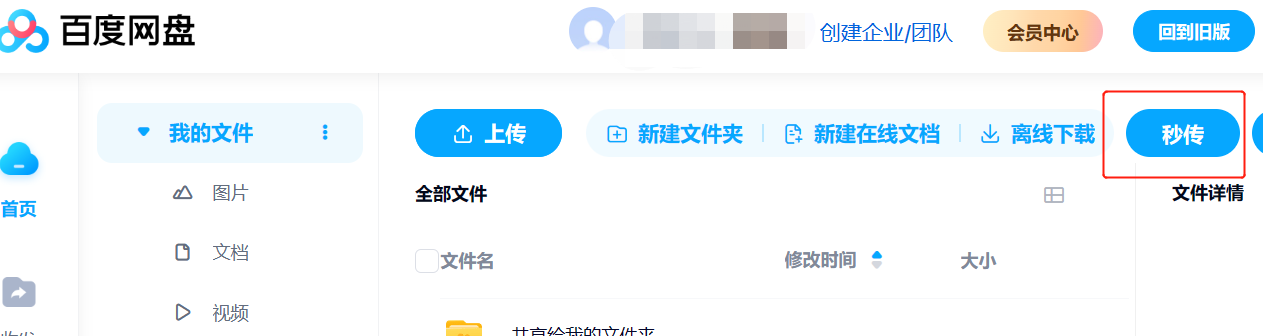
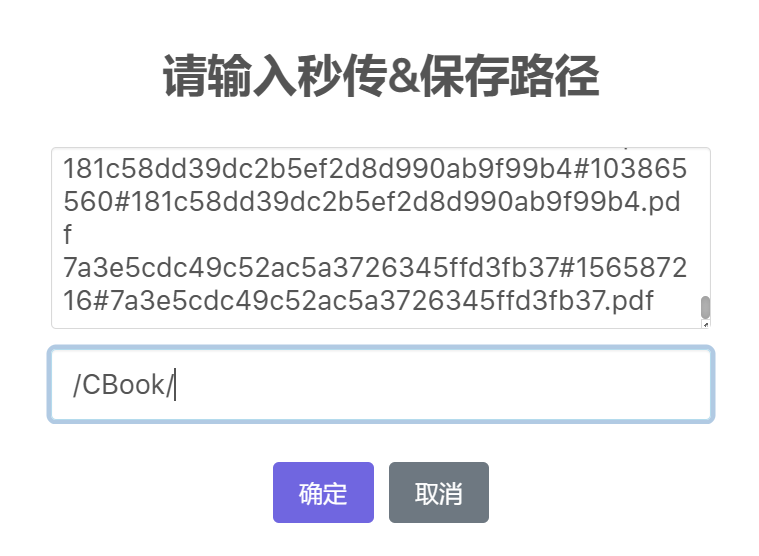
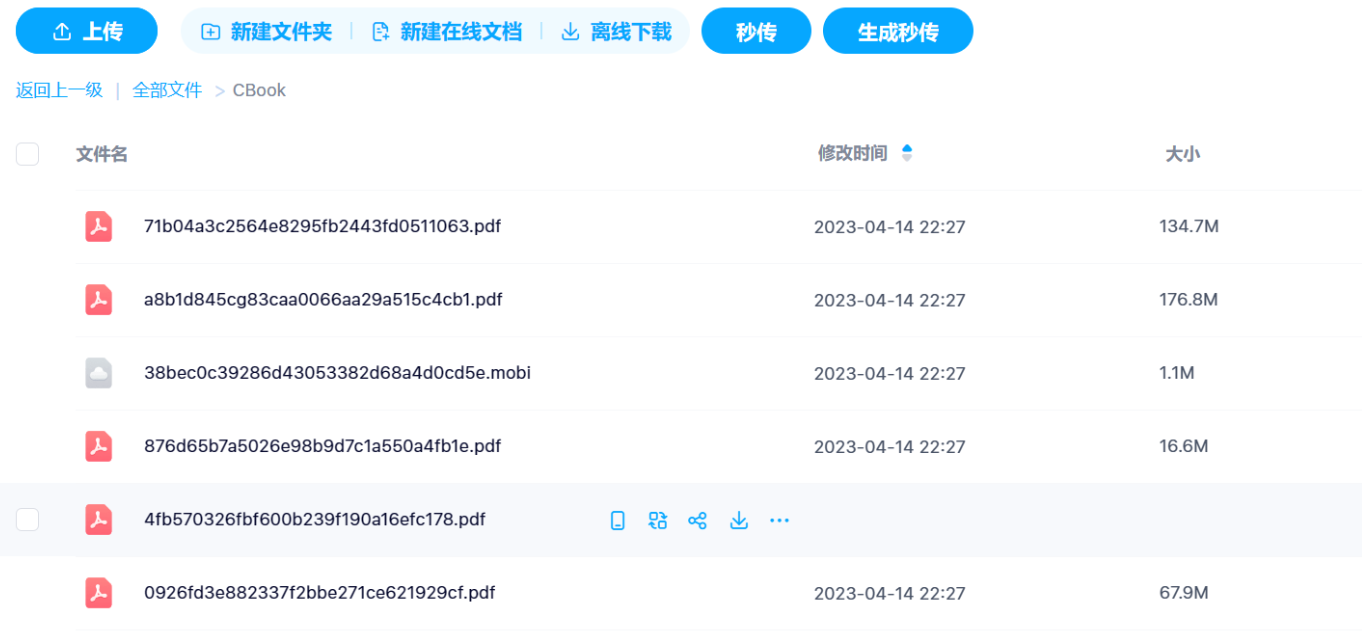
- 将MD5链接复制到秒传按钮对应的窗口内即可转存,转存成功后方可批量下载。
图书解析
主要解析以下格式的图书:
- PDF(非扫描版)
- EPUB
- MOBI
需求
具体见requirement.txt
PDF格式解析
DocAI:复旦大学自然语言处理实验室自2019年起,自主开发的非扫描件PDF处理工具。
注册并登录即可使用。
亦可使用python第三方库PyPDF2解析:
import PyPDF2
import os
# 保存每页文本信息
page_info = []
try:
# 指定pdf文件路径
book_path = os.path.join(pdf_chinese_md5_dir,PDF_MD5)
with open(book_path, 'rb') as pdf_fp:
pdf_reader = PyPDF2.PdfReader(pdf_fp)
if pdf_reader.is_encrypted:
# 如果PDF文档是加密的,则需要提供密码才能继续处理
pass
else:
# 遍历每一页并提取文本信息
for i in range(len(pdf_reader.pages)):
page = pdf_reader.pages[i]
text = page.extract_text()
# 如果提取到的文本信息非空,则认为该PDF文档包含文本信息
if text.strip():
page_info.append(text.strip()+'\n')
except Exception as e:
print(e)
EPUB格式解析
import zipfile
from bs4 import BeautifulSoup
import os
# 每个chapter文本
chapter_content_list = []
# 指定epub文件路径
book_path = os.path.join(epub_chinese_md5_dir,EPUB_MD5)
# 使用ZipFile库打开epub文件
book = zipfile.ZipFile(book_path)
# 获取书籍的文本HTML名称
xhtml_data = [string for string in book.namelist() if string.endswith('xhtml') or string.endswith('html') or string.endswith('xml')]
# 解析每个HTML文本格式
for k in range(len(xhtml_data)):
try:
chapter_file = book.open(unquote(xhtml_data[k]))
chapter_content = chapter_file.read().decode('utf-8')
chapter_content = BeautifulSoup(chapter_content, 'html')
chapter_content_list.append(chapter_content.get_text().strip())
except Exception as e:
print(e)
continue
MOBI格式解析
import mobi
import shutil
from bs4 import BeautifulSoup
import os
# 指定mobi文件路径
book_path = os.path.join(mobi_chinese_md5_dir,MOBI_MD5)
# 提取TMP文件路径
tempdir, filepath = mobi.extract(book_path)
#获取HTML文件内容后删除中间文件
try:
with open(filepath,'r',encoding='utf-8') as mobi_fp:
chapter_content = mobi_fp.read()
shutil.rmtree(tempdir)
#利用BeautifulSoup提取HTML文本信息并作格式化后重新提取
chapter_content = BeautifulSoup(chapter_content, 'html.parser')
chapter_content = chapter_content.prettify()
chapter_content = BeautifulSoup(chapter_content, 'html.parser')
file_content = chapter_content.get_text().strip()
except Exception as e:
print(e)
注意
本语料集合仅供科研用途











