
 Github
Github Huggingface
Huggingface 文档
文档OpenChatPaper
![]()
Yet another paper reading assistant based on OpenAI ChatGPT API. An open-source version that attempts to reimplement ChatPDF. A different dialogue version of another ChatPaper project.
又一个基于OpenAI ChatGPT API的论文阅读助手。试图重新实现 ChatPDF 的开源版本。支持对话的 ChatPaper 版本。
New Features:
- Sat. Apr.1, 2023: Add some buttons (summarize, contribution, novelty, strength, drawback, improvement) to get some basic aspects of paper quickly.
Online Demo API
Currently, we provide a demo (still developing) on the huggingface space. 目前,我们在huggingface space上提供演示(仍在开发中)。

Setup
- Install dependencies (tested on Python 3.9)
pip install -r requirements.txt
- Setup and lauch GROBID local server (add & at the end of command to run the program in the background)
bash serve_grobid.sh
- Setup backend
python backend.py --port 5000 --host localhost
- Frontend
streamlit run frontend.py --server.port 8502 --server.address localhost
中文配置文档
程序在
Python>=3.9,Ubuntu 20.04下测试,若在其他平台测试出错,欢迎提issue
- 创建一个Python的环境(推荐使用anaconda,关于如何安装请查阅其他教程),创建环境后激活并且安装依赖
conda create -n cpr python=3.9
conda activate cpr
pip install -r requirements.txt
-
确保本机安装了java环境,如果
java -version成功放回版本即说明安装成功。关于如何安装JAVA请查阅其他教程 -
GROBID是一个开源的PDF解析器,我们会在本地启动它用来解析输入的pdf。执行以下命令来下载GROBID和运行,成功后会显示
EXECUTING[XXs]
bash serve_grobid.sh

- 开启后端进程:每个用户的QA记录放进一个缓存pool里
python backend.py --port 5000 --host localhost
- 最后一步,开启Streamlit前端,访问
http://localhost:8502,在API处输入OpenAI的APIkey(如何申请?),上传PDF文件解析完成后便可开始对话
streamlit run frontend.py --server.port 8502 --server.address localhost
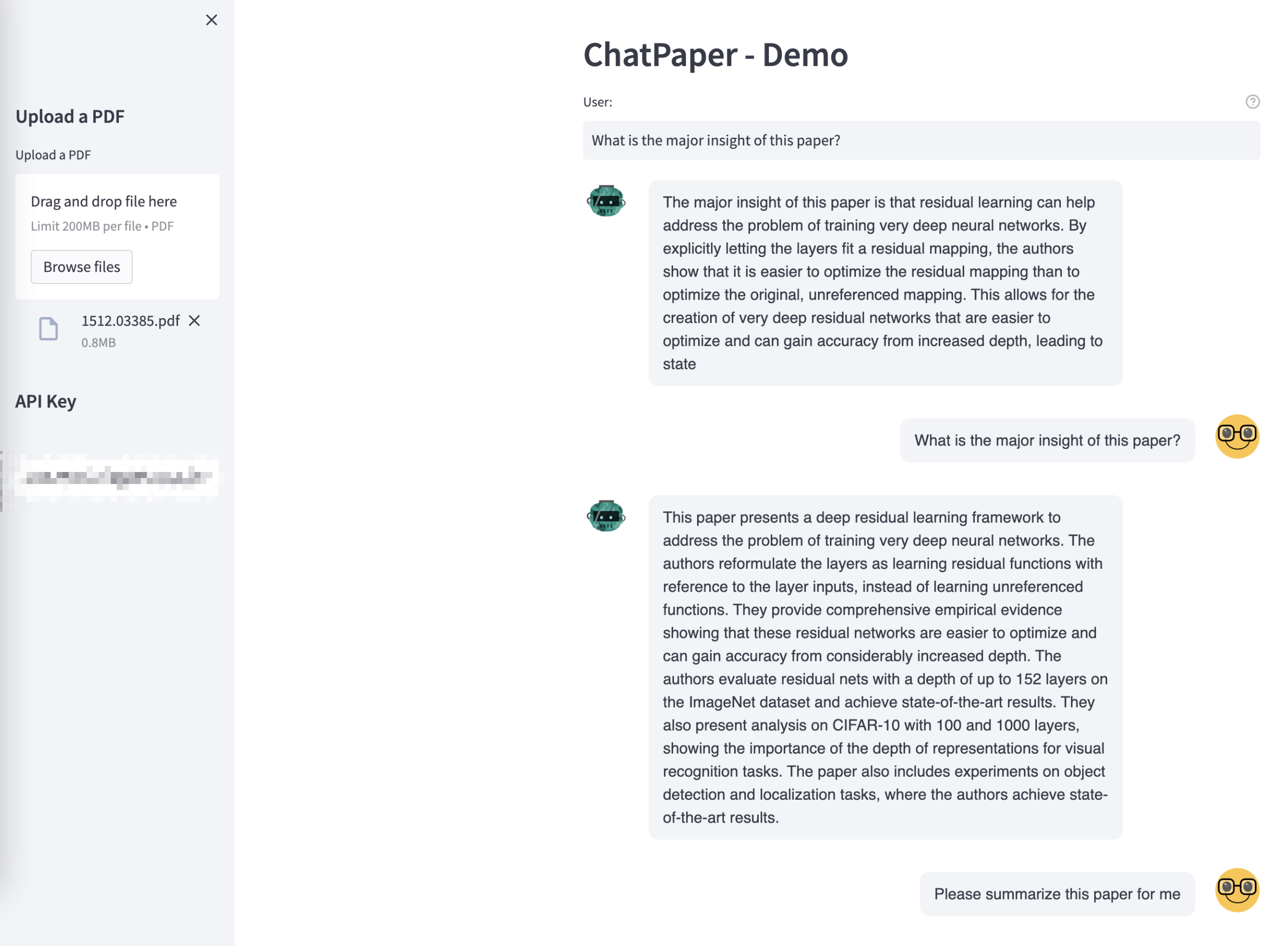
Demo Example
- Prepare an OpenAI API key and then upload a PDF to start chatting with the paper.
Implementation Details
-
Greedy Dynamic Context: Since the max token limit, we select the most relevant paragraphs in the pdf for each user query. Our model split the text input and output by the chatbot into four part: system_prompt (S), dynamic_source (D), user_query (Q), and model_answer(A). So upon each query, we first rank all the paragraphs by using a sentence_embedding model to calculate the similarity distance between the query embedding and all source embeddings. Then we compose the dynamic_source using a greedy method by to gradually push all relevant paragraphs (maintaing D <= MAX_TOKEN_LIMIT - Q - S - A - SOME_OVERHEAD).
-
Context Truncating: When context is too long, we now we simply pop out the first QA-pair.
TODO
- Context Condense: see
condense-prompt.txt - Poping context out based on similarity
- Handling paper with longer pages
Cooperation & Contributions
Feel free to reach out for possible cooperations or Contributions! (yixinliucs at gmail.com)
References
- SciPDF Parser: https://github.com/titipata/scipdf_parser
- St-chat: https://github.com/AI-Yash/st-chat
- Sentence-transformers: https://github.com/UKPLab/sentence-transformers
- ChatGPT Chatbot Wrapper: https://github.com/acheong08/ChatGPT
How to cite
If you want to cite this work, please refer to the present GitHub project with BibTeX:
@misc{ChatPaper,
title = {ChatPaper},
howpublished = {\url{https://github.com/liuyixin-louis/ChatPaper}},
publisher = {GitHub},
year = {2023},
}











