
 访问官网
访问官网 Github
Github 论文
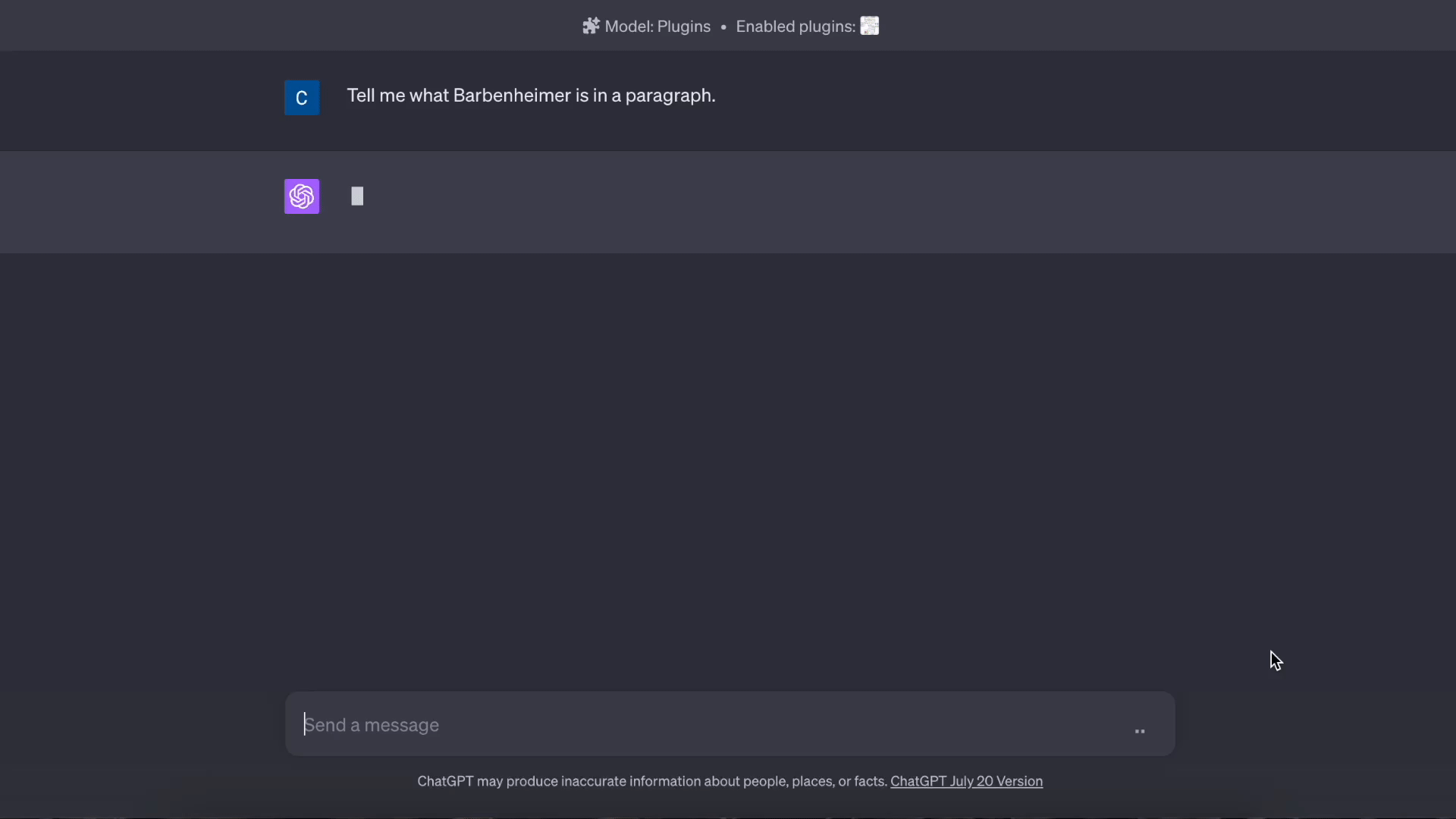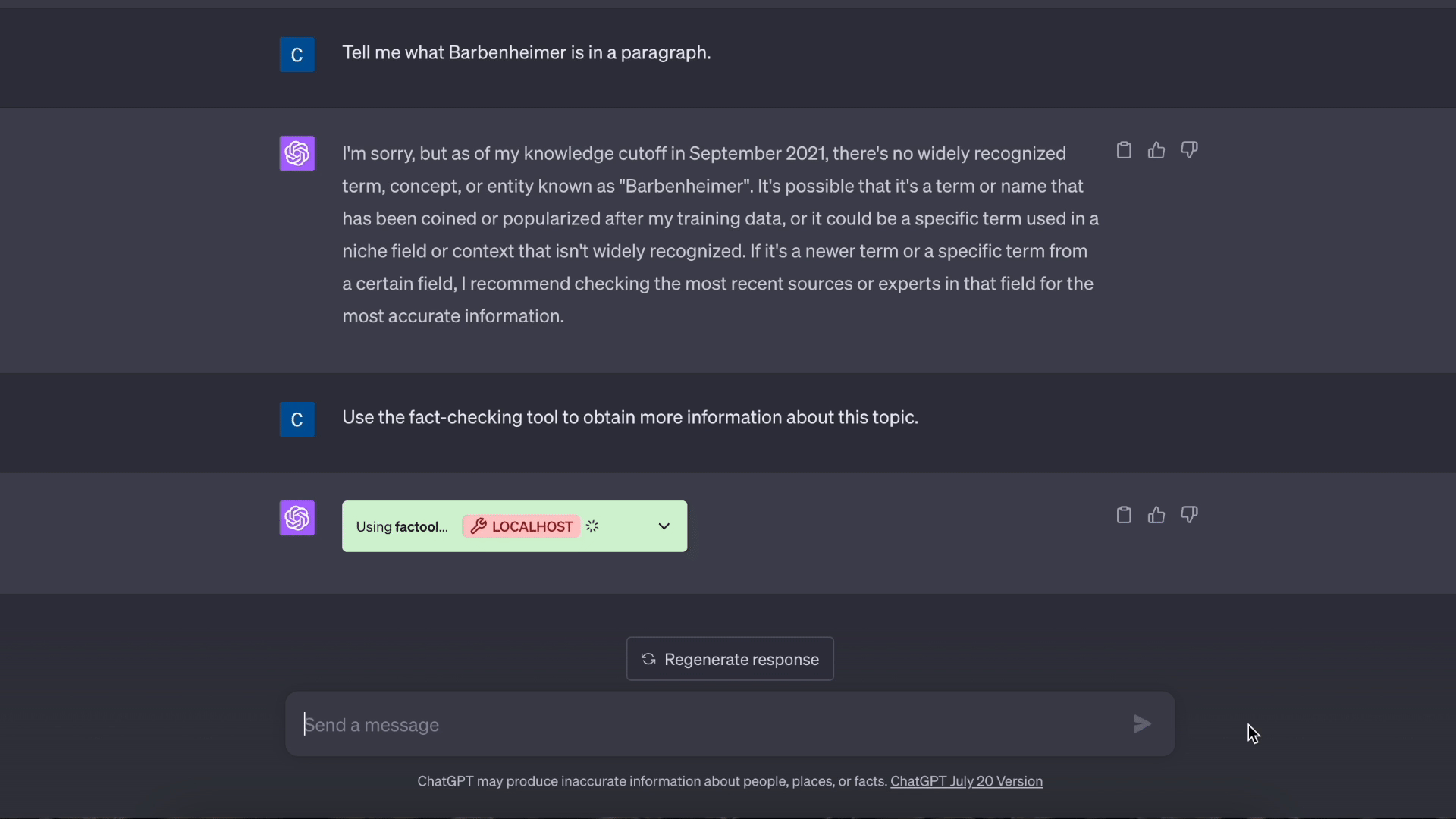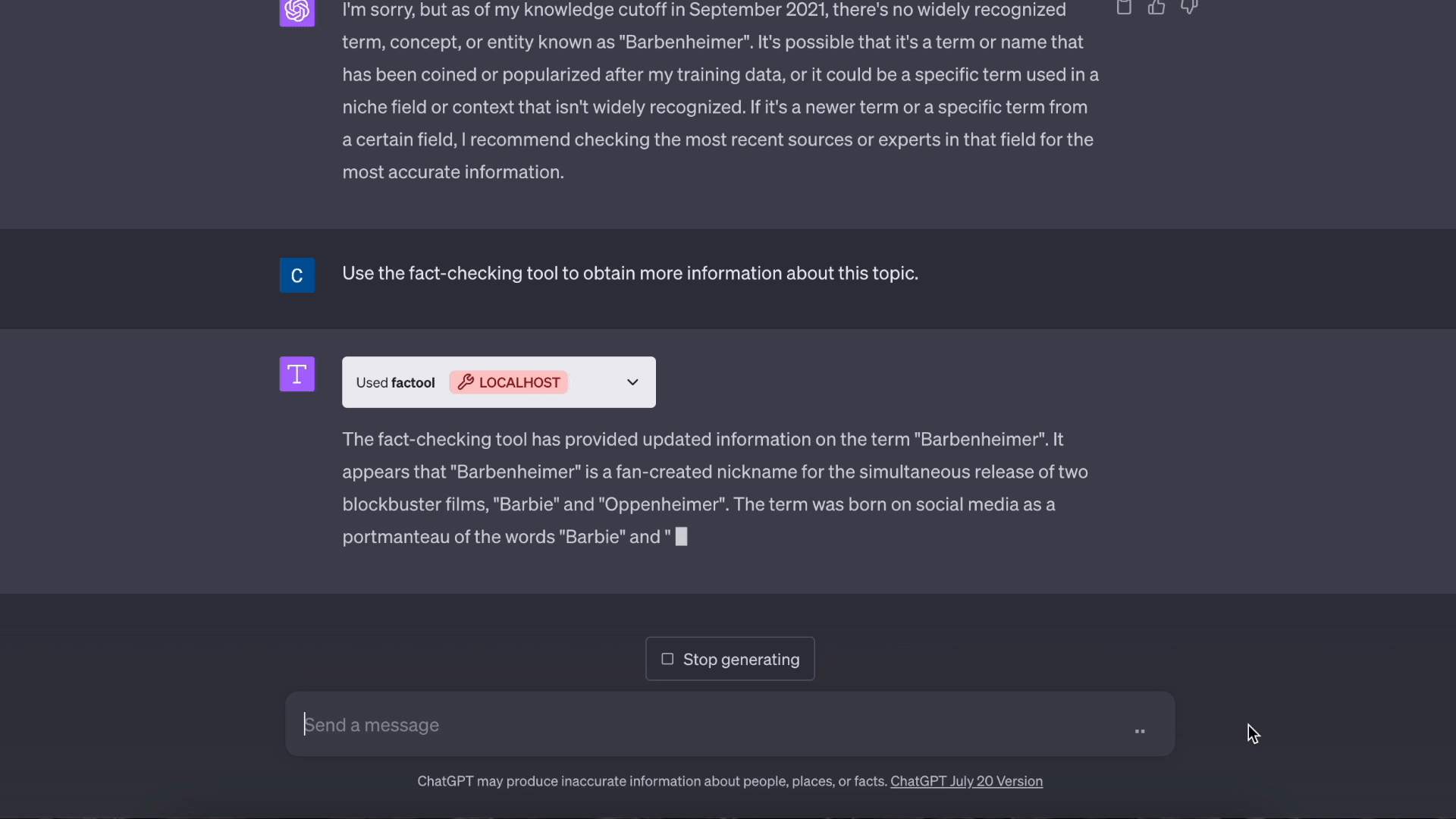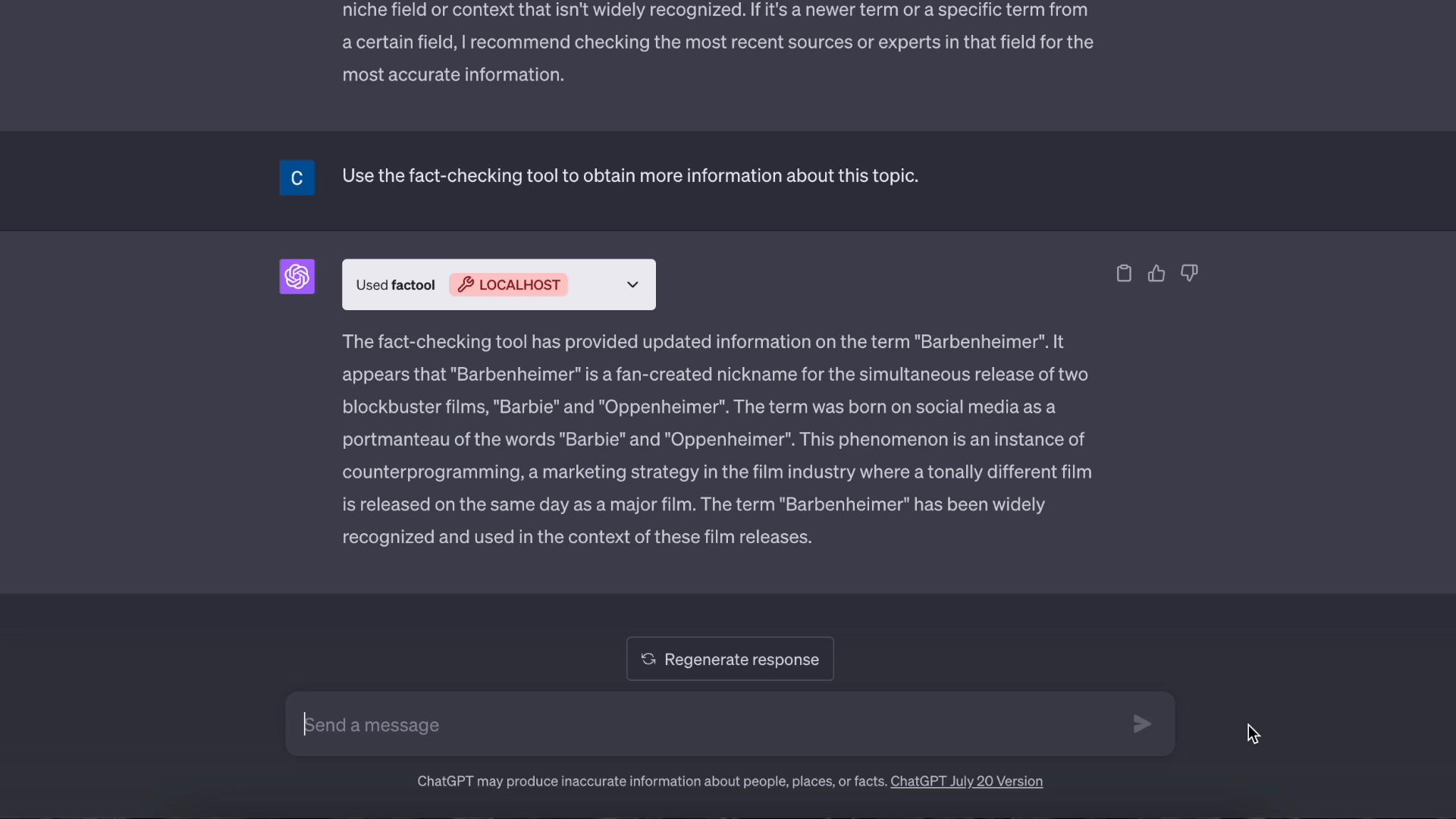
论文FacTool: 生成式人工智能的事实性检测工具
事实性排行榜 | 安装 | 快速开始 | FacTool ChatGPT 插件 | 引用 |
本仓库包含了我们论文的源代码和插件配置。
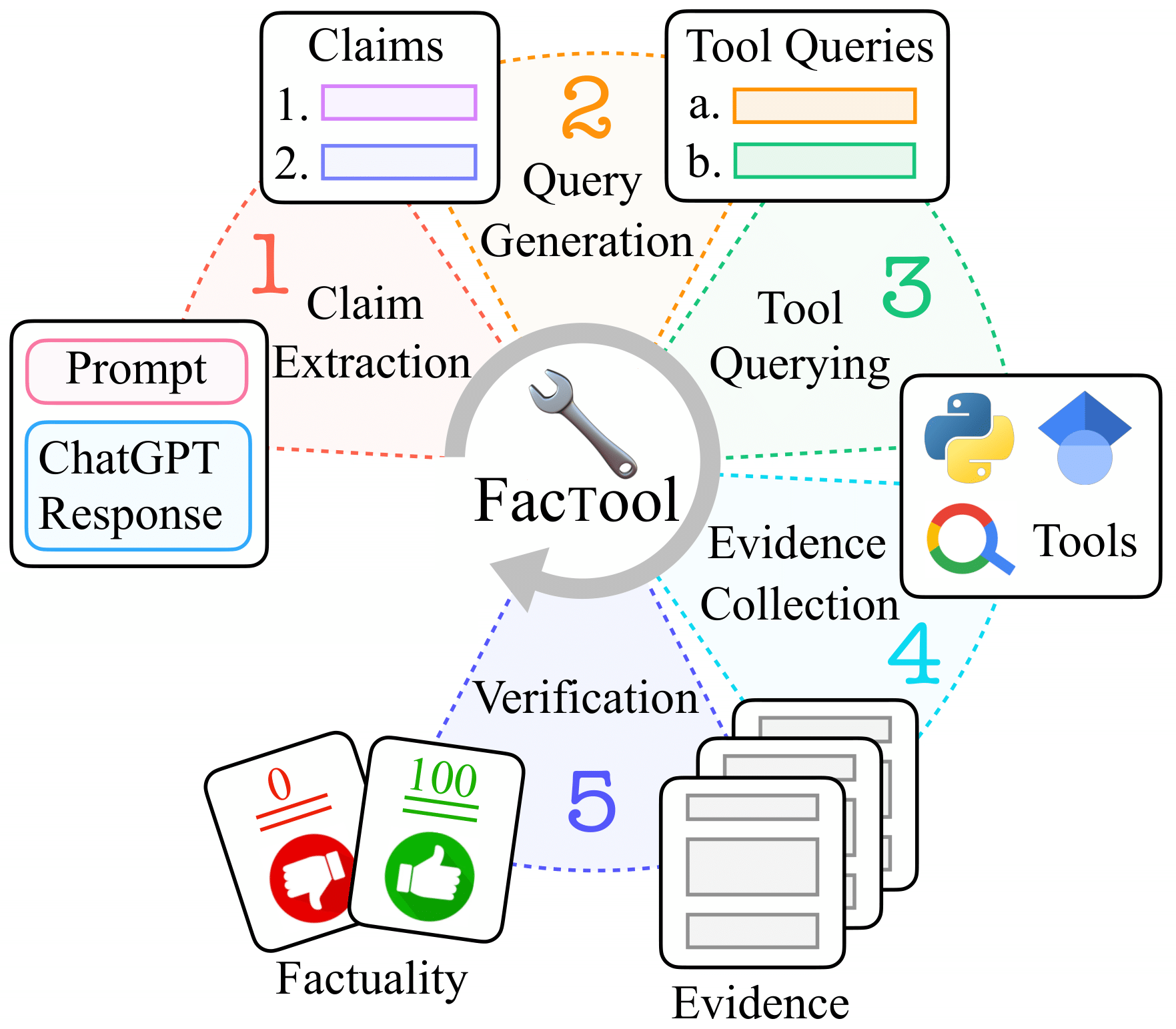
Factool 是一个工具增强型框架,用于检测大型语言模型(如ChatGPT)生成文本中的事实错误。 Factool 目前支持4项任务:
- 基于知识的问答: Factool 检测基于知识的问答中的事实错误。
- 代码生成: Factool 检测代码生成中的执行错误。
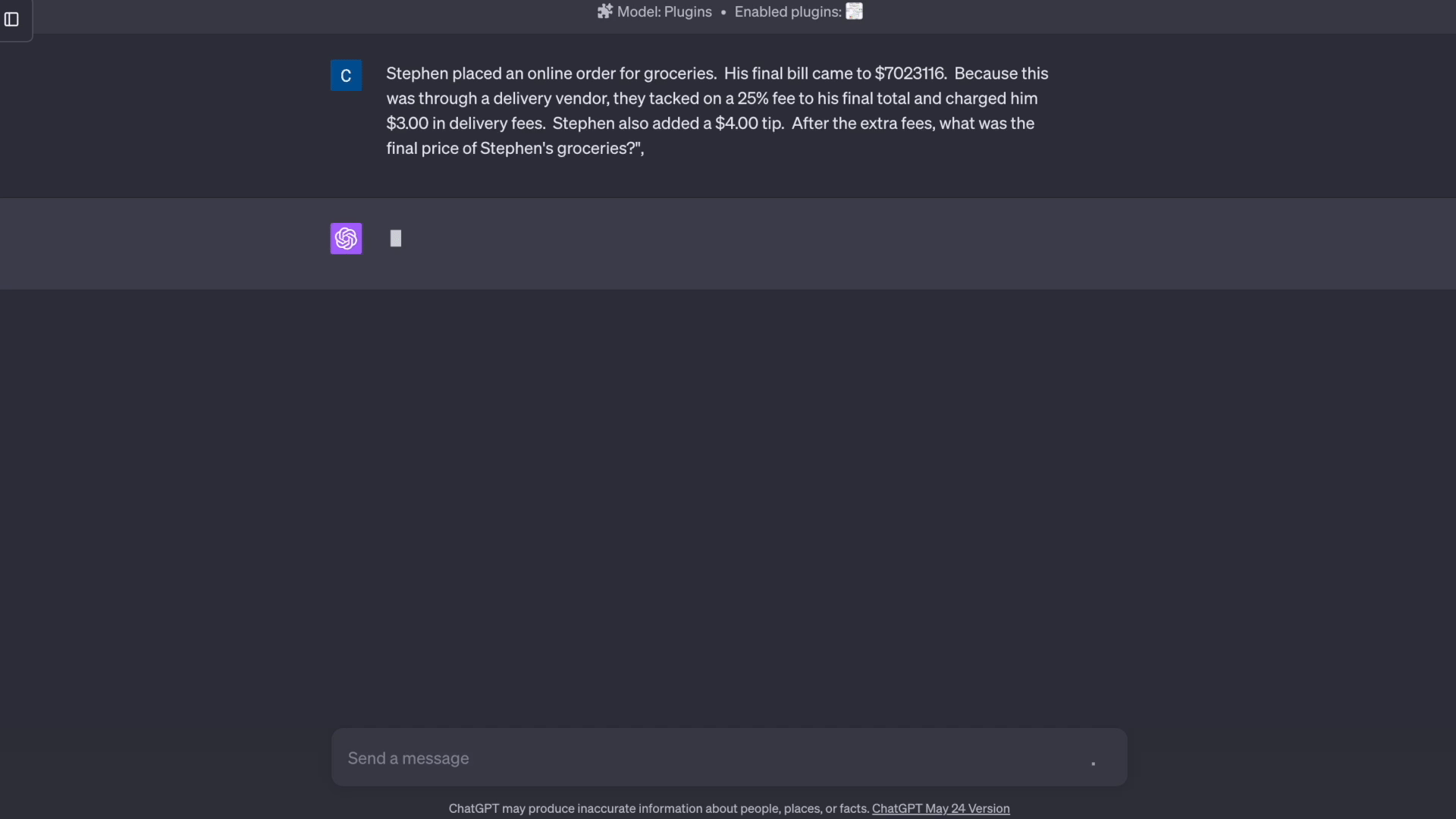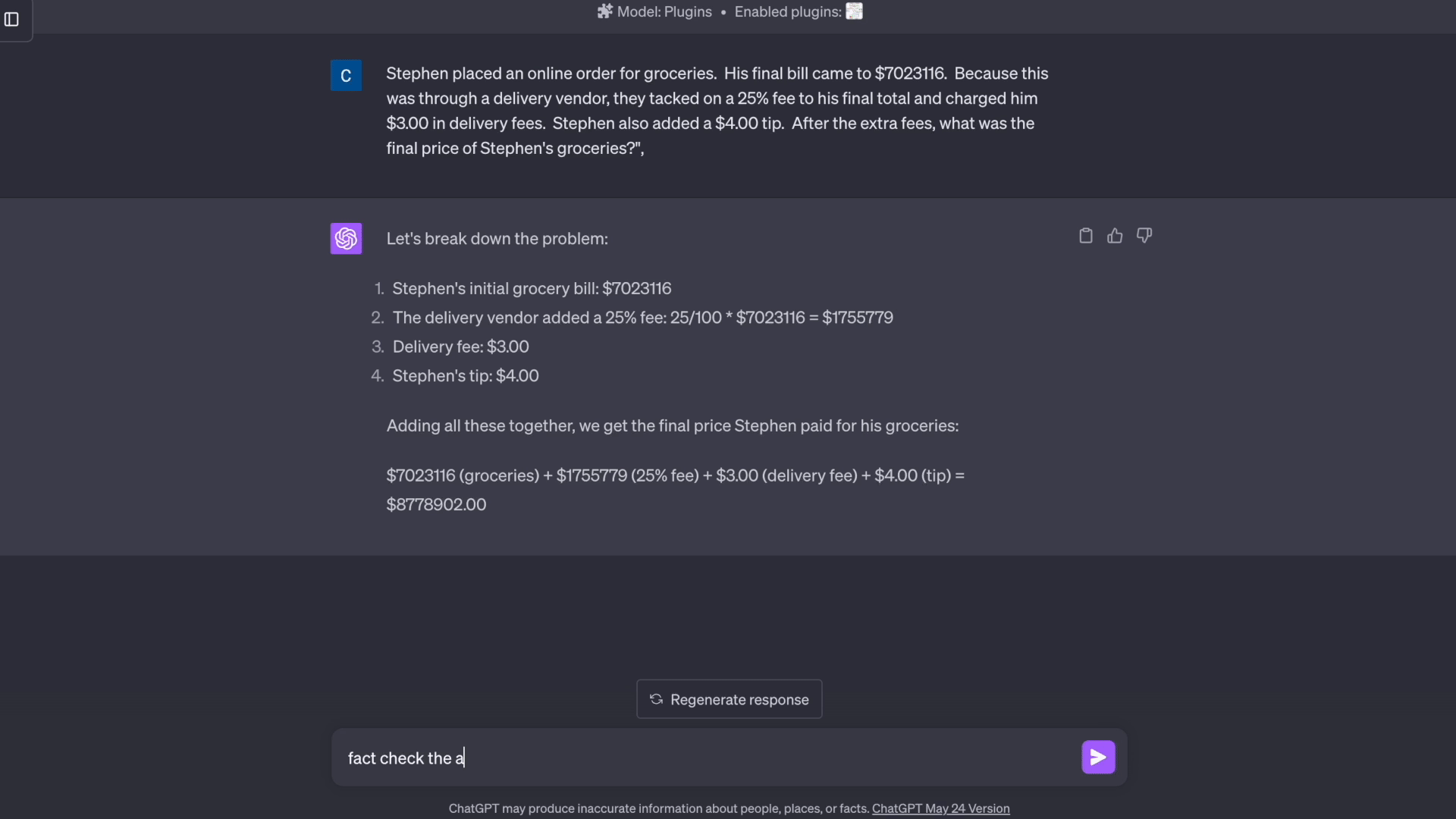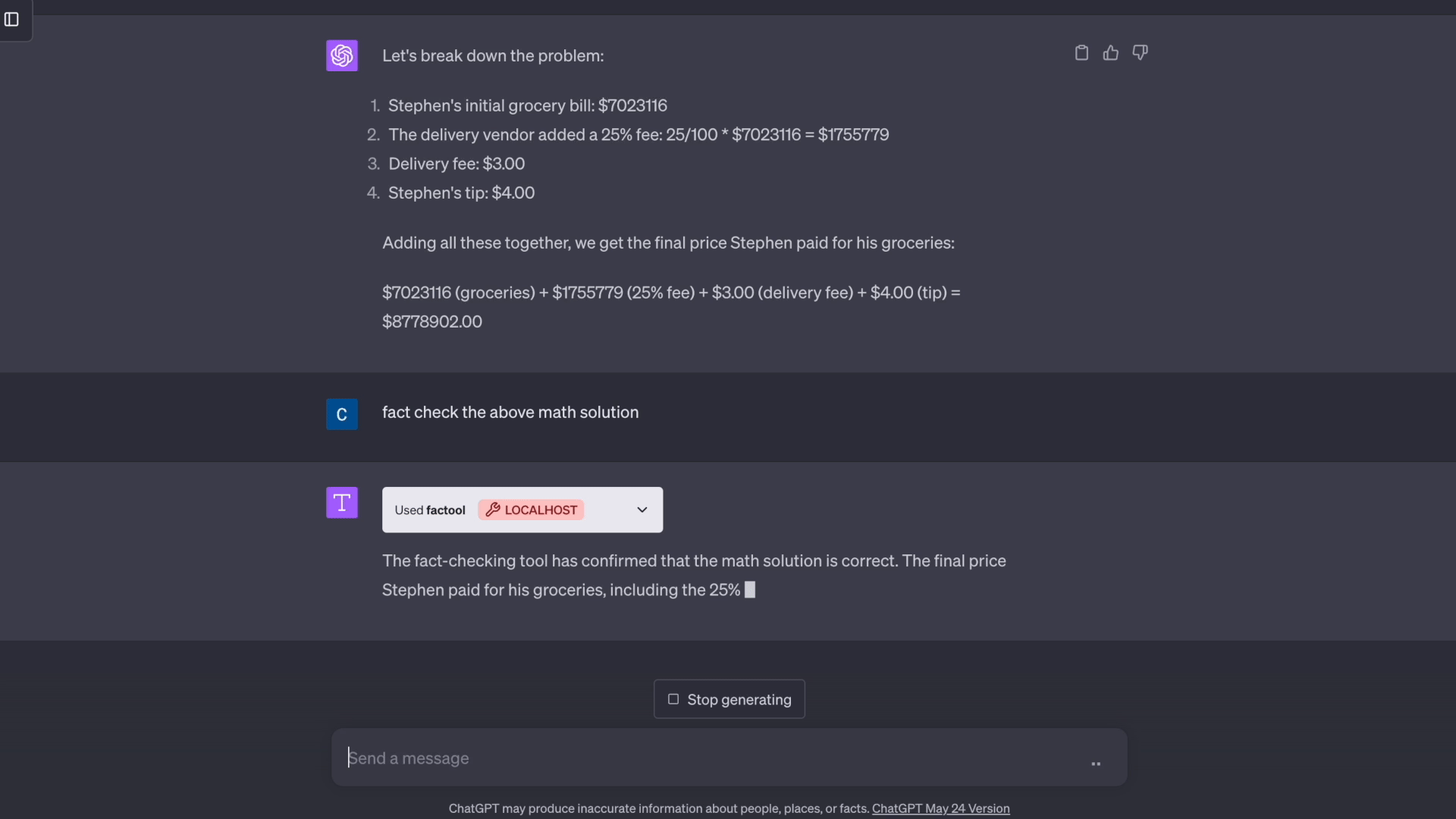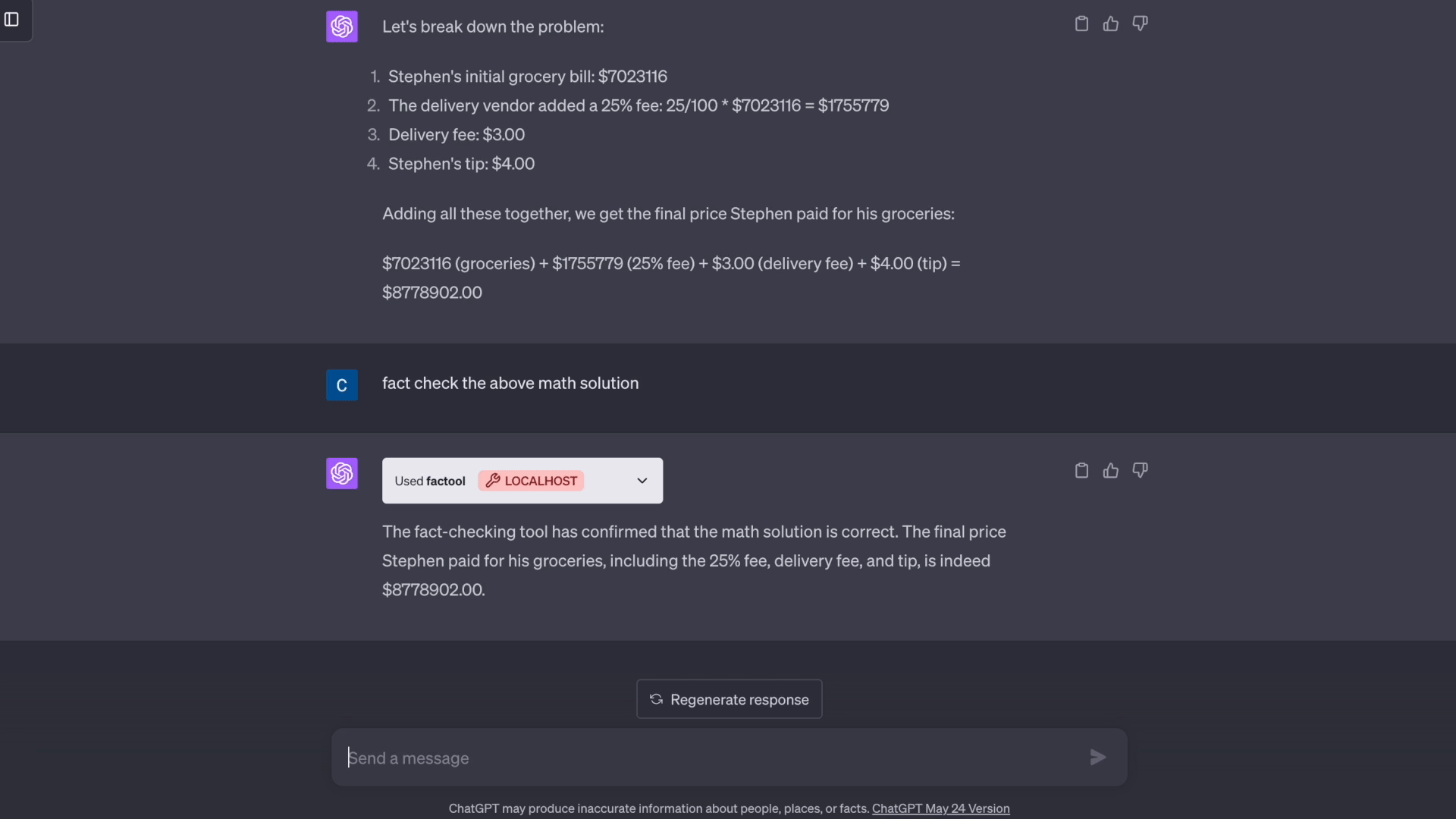
- 数学推理: Factool 检测数学推理中的计算错误。
- 科学文献综述: Factool 检测虚构的科学文献。
新闻
- [2023/09/25] 🔥 祝贺百川2-53B在中文大语言模型ChineseFactEval基准测试中取得最佳表现!
- [2023/09/13] 我们发布了ChineseFactEval,一个针对中文大语言模型的事实性基准测试
- [2023/07/25] 我们推出了FacTool,一个用于检测大语言模型生成文本事实错误的工具增强型框架
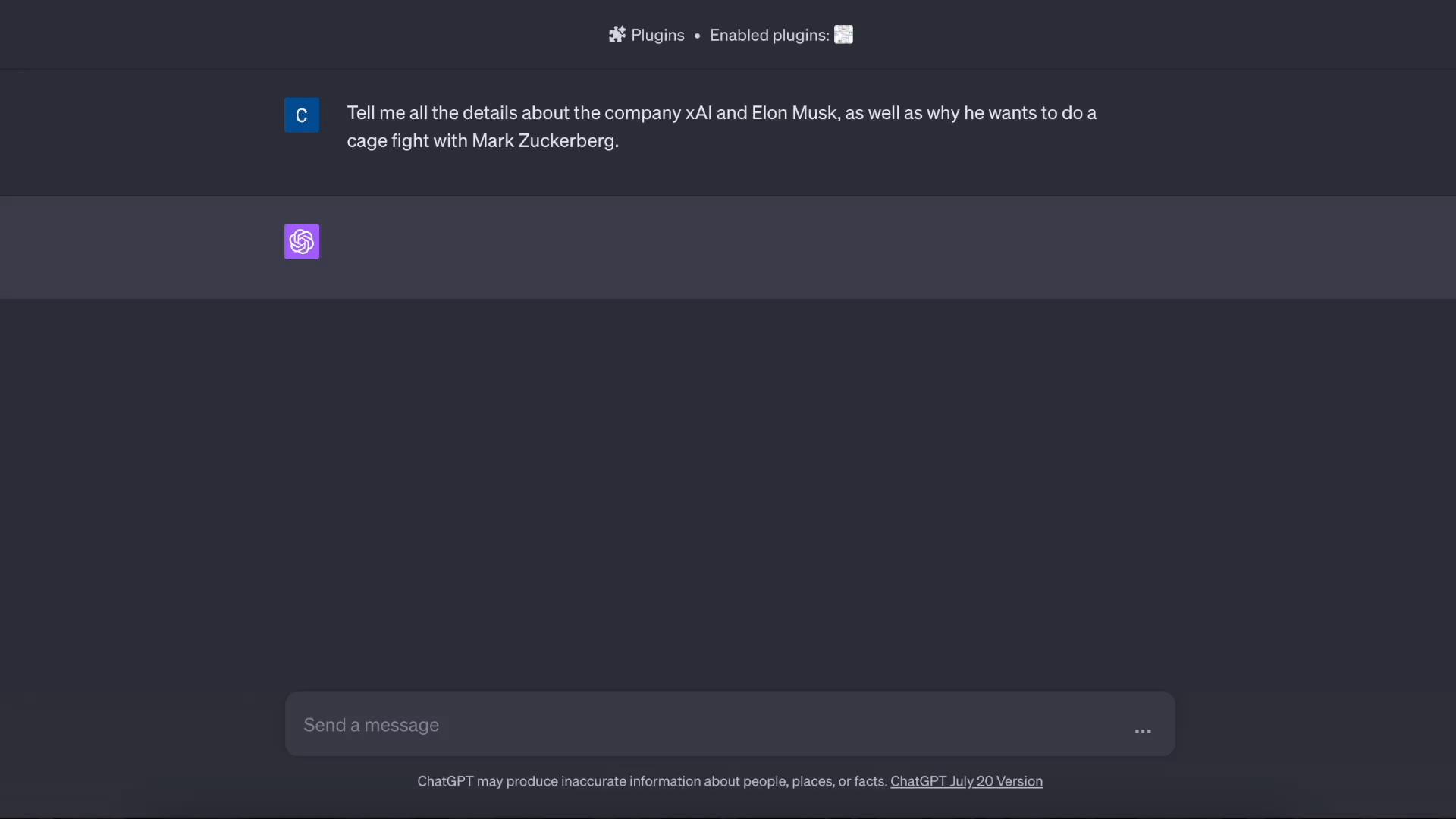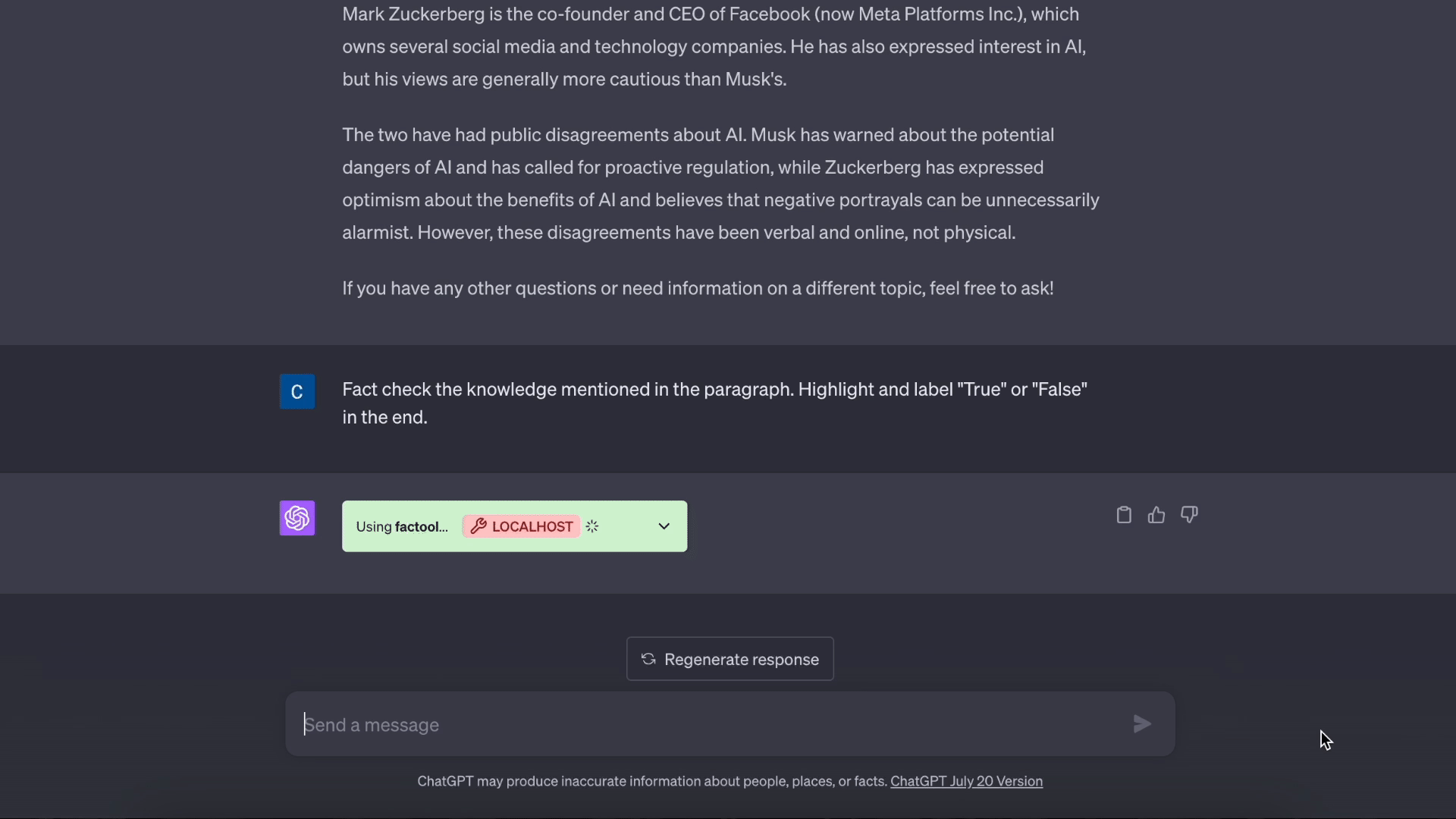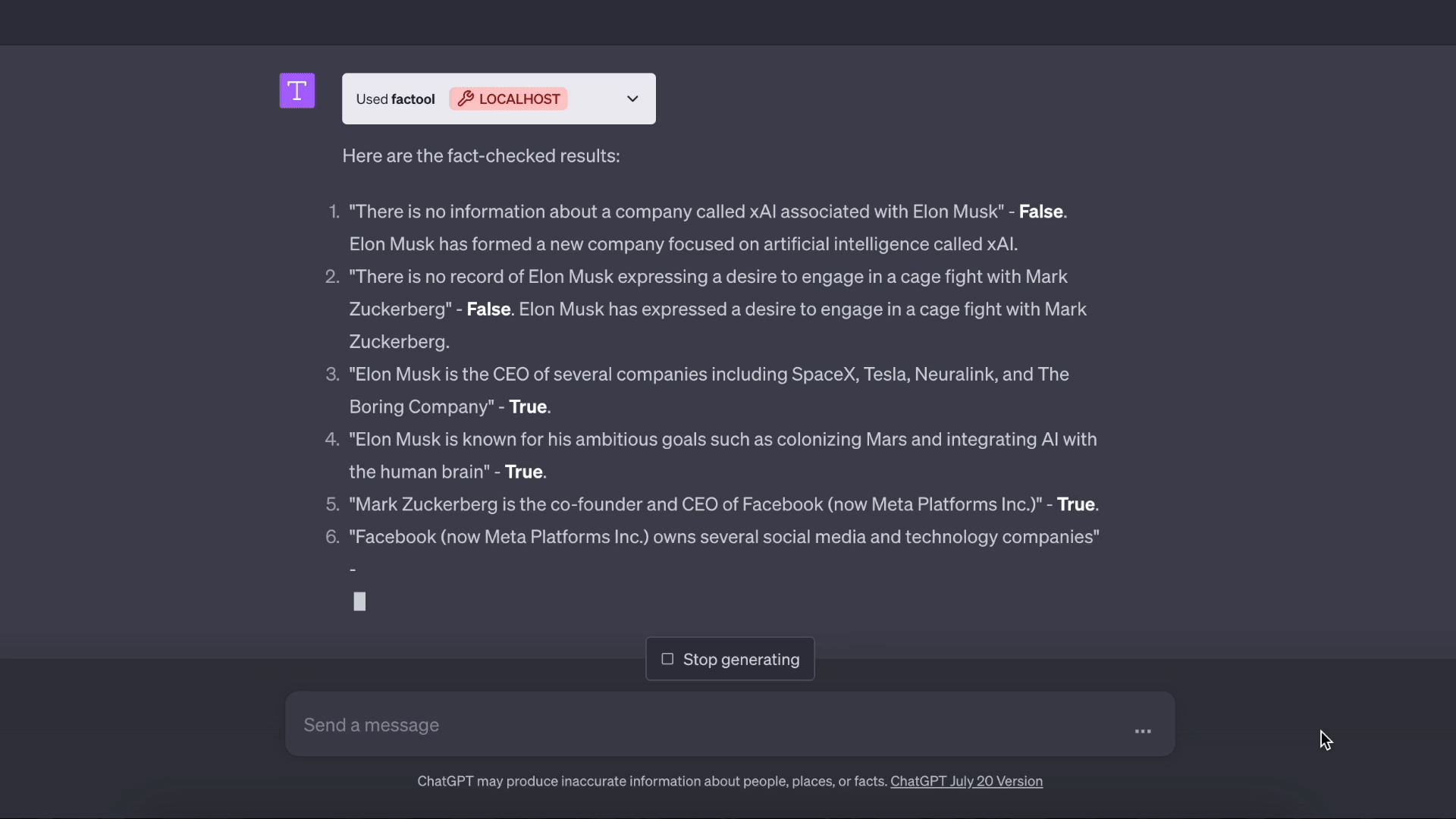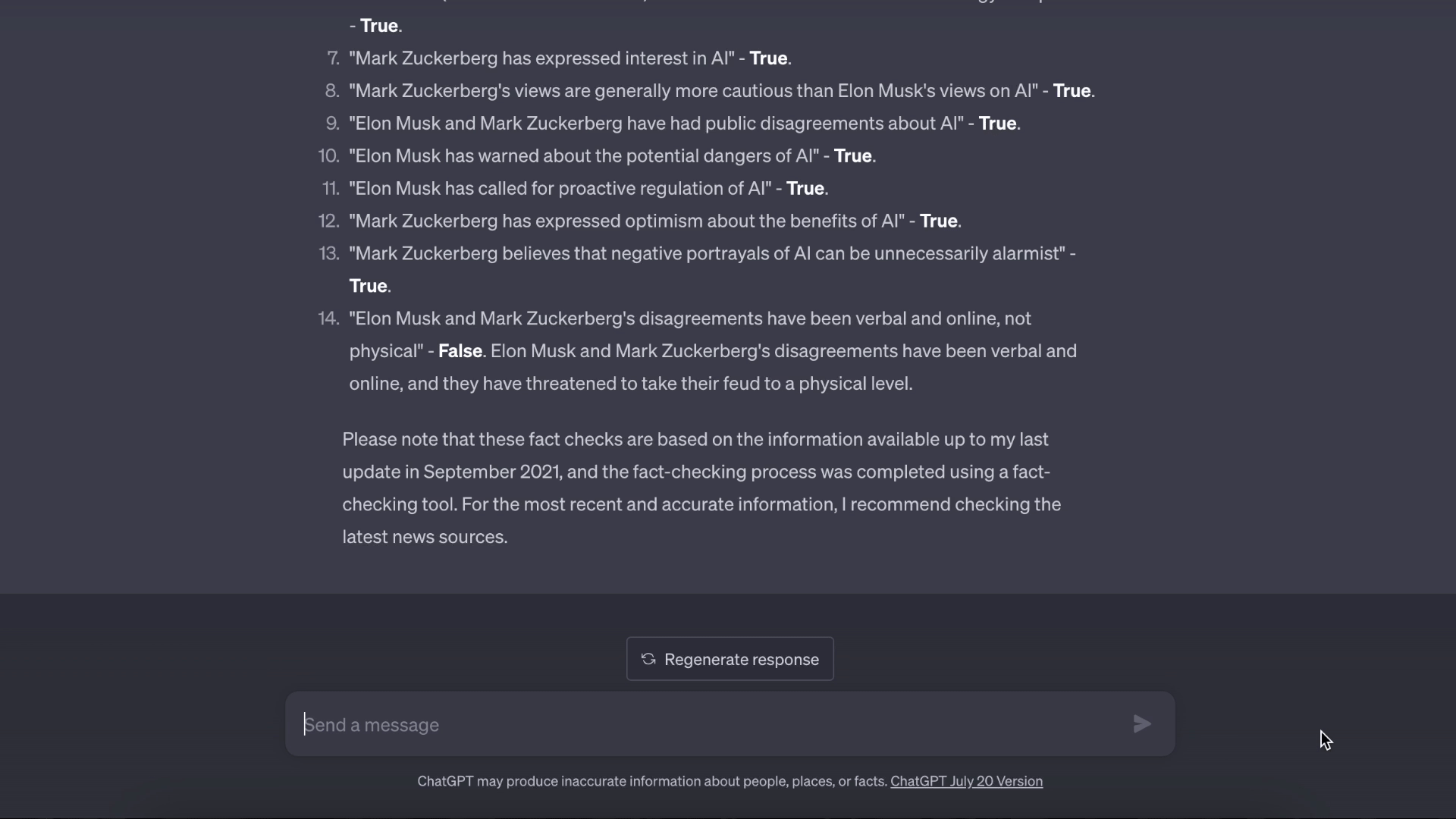
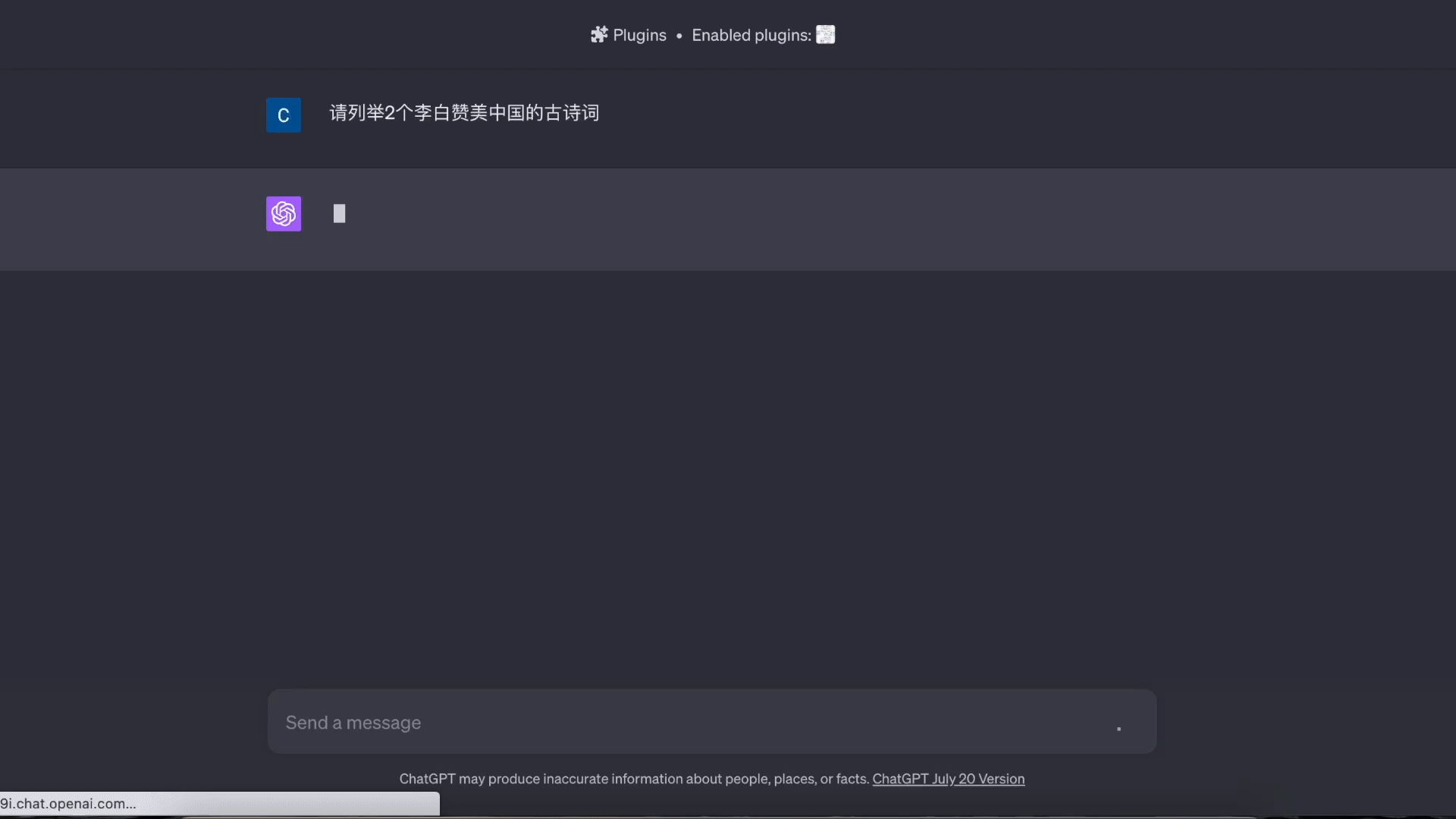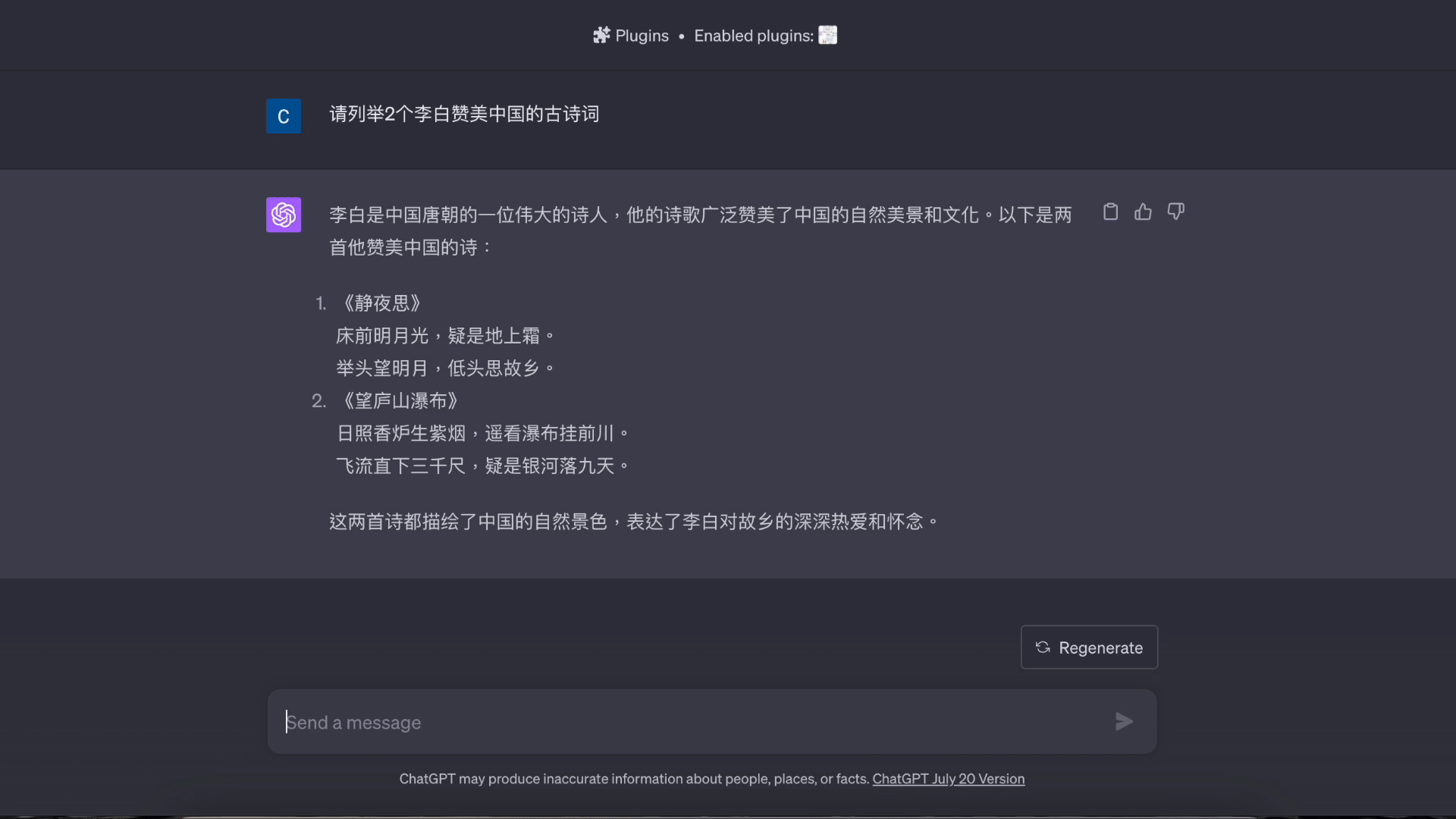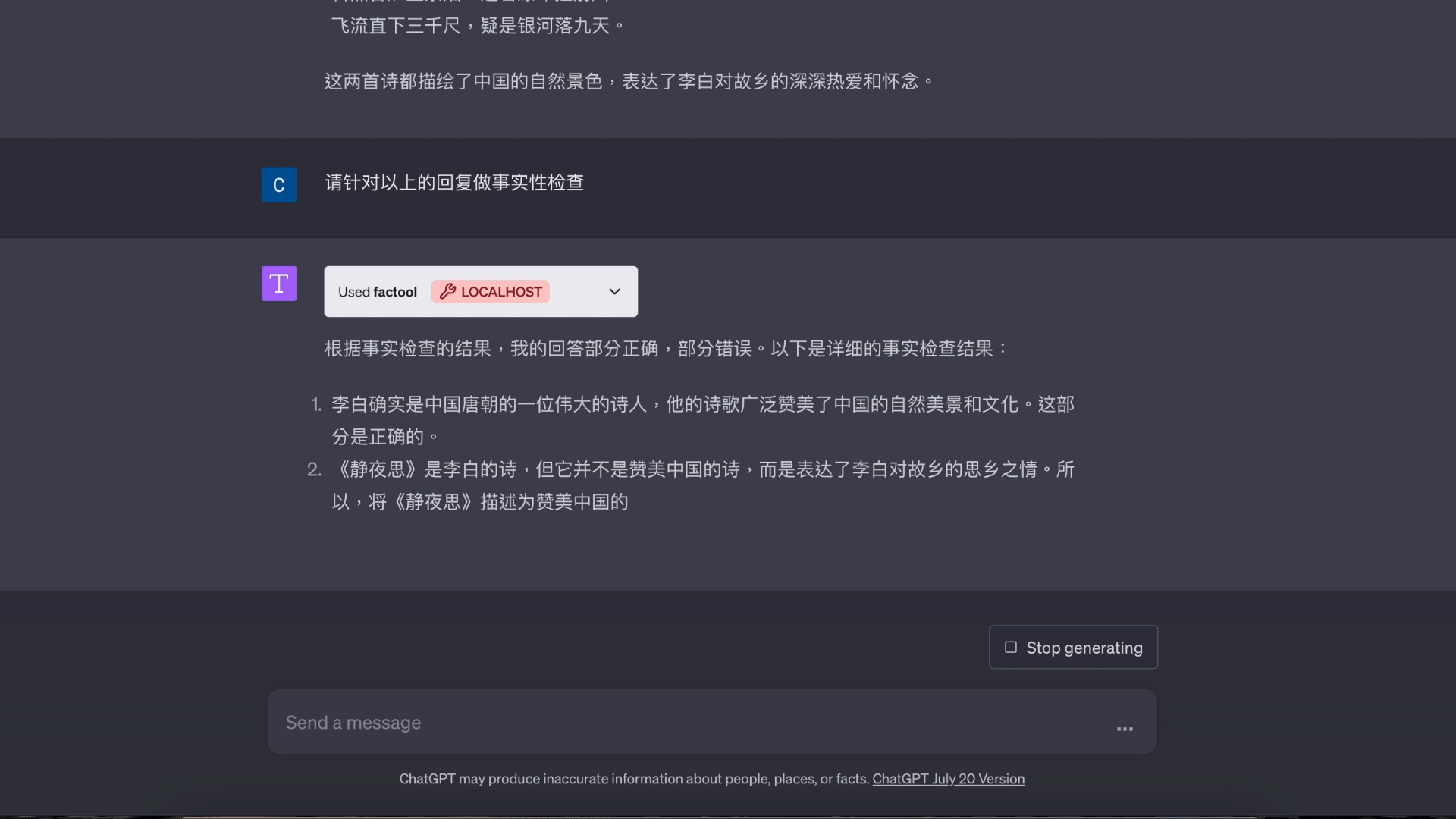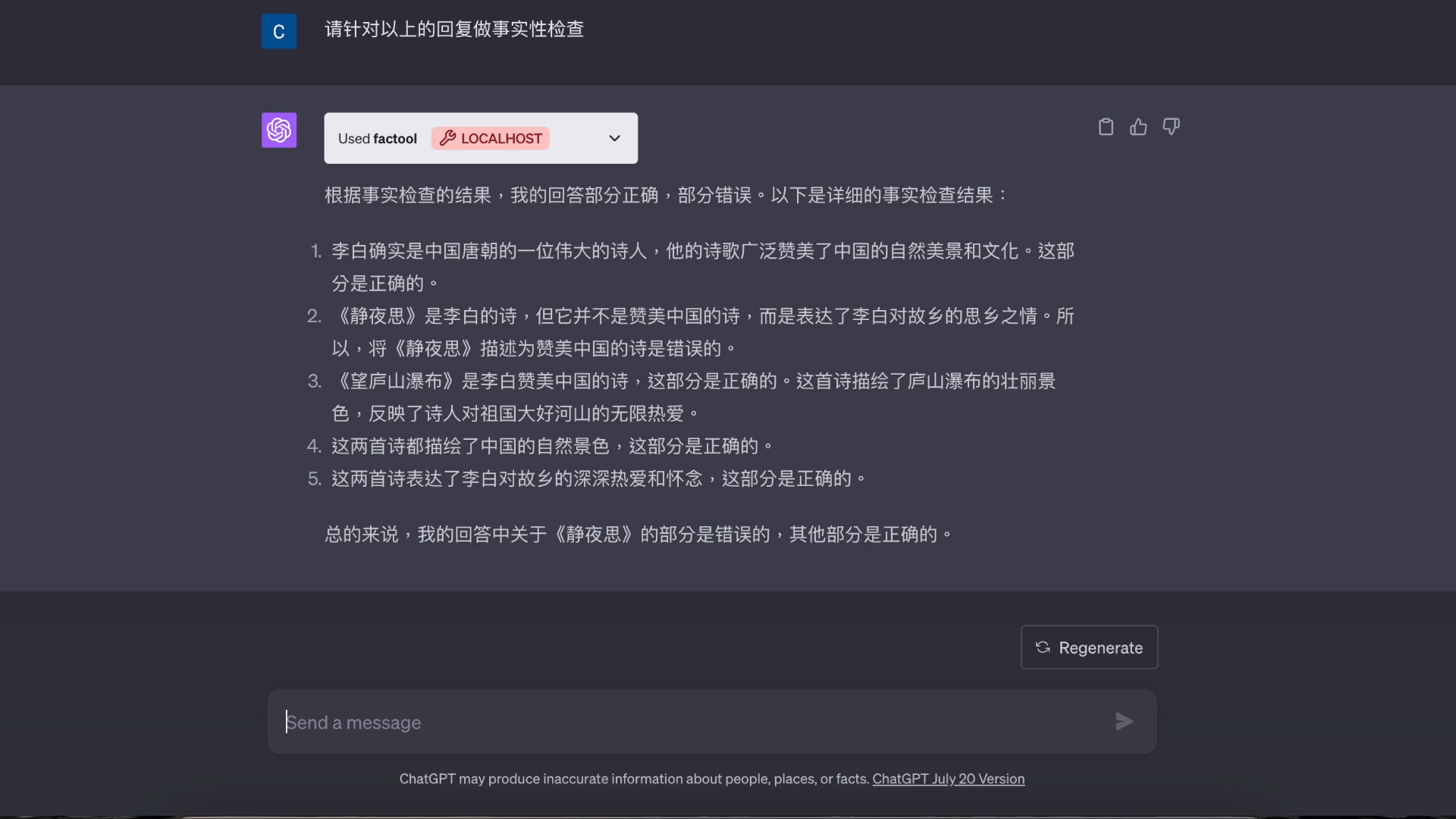
基于知识的问答演示:
事实性排行榜
我们的事实性排行榜展示了由FacTool评估的不同聊天机器人的事实准确性。
| 大语言模型 | 加权声明级准确率 | 响应级准确率 |
|---|---|---|
| GPT-4 | 75.60 | 43.33 |
| ChatGPT | 68.63 | 36.67 |
| Claude-v1 | 63.95 | 26.67 |
| Bard | 61.15 | 33.33 |
| Vicuna-13B | 50.35 | 21.67 |
安装
-
普通用户
pip install factool
-
开发者
git clone git@github.com:GAIR-NLP/factool.git
cd factool
pip install -e .
快速开始
API密钥准备
- 从这里获取你的OpenAI API密钥。这在所有场景中都需要使用(基于知识的问答、代码、数学、科学文献综述)。
- 从这里获取你的Serper API密钥。这仅在基于知识的问答中使用。
- 从这里获取你的Scraper API密钥。这仅在科学文献综述中使用。
通用用法
你也可以直接参考./example/example.py和example_inputs.jsonl了解通用用法。
通用用法(点击展开内容)
export OPENAI_API_KEY=... # 所有任务都需要
export SERPER_API_KEY=... # 仅基于知识的问答需要
export SCRAPER_API_KEY=... # 仅科学文献综述需要
# 初始化输入列表。"entry_point"仅在任务为"代码生成"时需要
# 请参考example_inputs.jsonl获取每个类别的示例输入
inputs = [
{"prompt": "<提示1>", "response": "<回答1>", "category": "<类别1>", "entry_point": "<入口点1>"},
{"prompt": "<提示2>", "response": "<回答2>", "category": "<类别2>", "entry_point": "<入口点2>"},
...
]
其中
prompt: 用于生成回答的提示。response: 模型生成的回答。category: 任务类别。可以是:kbqacodemathscientific
entry_point: 回答中需要进行事实检查的代码片段的函数名。如果任务类别不是code,可以为"null"。
from factool import Factool
# 使用指定的密钥初始化Factool实例。foundation_model可以是"gpt-3.5-turbo"或"gpt-4"
factool_instance = Factool("gpt-4")
inputs = [
{
"prompt": "介绍Graham Neubig",
"response": "Graham Neubig是MIT的教授",
"category": "kbqa"
},
...
]
response_list = factool_instance.run(inputs)
print(response_list)
基于知识的问答
Factool在基于知识的问答中的详细用法(点击展开内容)
export OPENAI_API_KEY=...
export SERPER_API_KEY=...
from factool import Factool
# 使用指定的密钥初始化Factool实例。foundation_model可以是"gpt-3.5-turbo"或"gpt-4"
factool_instance = Factool("gpt-4")
inputs = [
{
"prompt": "介绍Graham Neubig",
"response": "Graham Neubig是MIT的教授",
"category": "kbqa"
},
]
response_list = factool_instance.run(inputs)
print(response_list)
response_list应遵循以下格式: response_list 应遵循以下格式:
{
"average_claim_level_factuality": avg_claim_level_factuality
"average_response_level_factuality": avg_response_level_factuality
"detailed_information": [
{
'prompt': prompt_1,
'response': response_1,
'category': 'code',
'claims': [claim_11, claim_12, ..., claims_1n],
'queries': [[query_111, query_112], [query_121, query_122], ..[query_1n1, query_1n2]],
'evidences': [[evidences_with_source_11], [evidences_with_source_12], ..., [evidences_with_source_1n]],
'claim_level_factuality': [{claim_11, reasoning_11, error_11, correction_11, factuality_11}, {claim_12, reasoning_12, error_12, correction_12, factuality_12}, ..., {claim_1n, reasoning_1n, error_1n, correction_1n, factuality_1n}],
'response_level_factuality': factuality_1
},
{
'prompt': prompt_2,
'response': response_2,
'category': 'code',
'claims': [claim_21, claim_22, ..., claims_2n],
'queries': [[query_211, query_212], [query_221, query_222], ..., [query_2n1, query_2n2]],
'evidences': [[evidences_with_source_21], [evidences_with_source_22], ..., [evidences_with_source_2n]],
'claim_level_factuality': [{claim_21, reasoning_21, error_21, correction_21, factuality_21}, {claim_22, reasoning_22, error_22, correction_22, factuality_22}, ..., {claim_2n, reasoning_2n, error_2n, correction_2n, factuality_2n}],
'response_level_factuality': factuality_2,
},
...
]
}
在这种情况下,你将得到:
{
'average_claim_level_factuality': 0.0,
'average_response_level_factuality': 0.0,
'detailed_information': [
{
'prompt': '实现get_max_triples函数',
'response': 'def get_max_triples(n):\n a = [i * i - i + 1 for i in range(1, n+1)]\n count = 0\n for i in range(n-2):\n for j in range(i+1, n-1):\n for k in range(j+1, n):\n if (a[i] + a[j] + a[k]) % 3 == 0:\n count += 1\n return count\n\nprint(get_max_triples(5)) # 输出: 1',
'category': 'code', 'entry_point': 'get_max_triples',
'claims': [{'claim': '函数实现正确'}, {'claim': '函数输出正确'}],
'queries': [['get_max_triples函数是否正确实现?'], ['get_max_triples(5)的输出是否为1?']],
'evidences': [{'evidence': '函数实现正确。它创建了数组a,并正确计算了符合条件的三元组数量。', 'source': '代码分析'}, {'evidence': 'get_max_triples(5)的输出确实为1,这与给定的示例相符。', 'source': '代码执行'}],
'claim_level_factuality': [
{
'reasoning': '函数的实现遵循了问题描述中的要求。它创建了正确的数组a,并使用嵌套循环检查所有可能的三元组。',
'error': '无',
'correction': '无需修正',
'factuality': True,
'claim': '函数实现正确'
},
{
'reasoning': '代码执行结果显示get_max_triples(5)确实输出1,这与问题描述中的示例一致。',
'error': '无',
'correction': '无需修正',
'factuality': True,
'claim': '函数输出正确'
}
],
'response_level_factuality': True
}
]
}
response_list =
{
"average_claim_level_factuality": avg_claim_level_factuality,
"average_response_level_factuality": avg_response_level_factuality,
"detailed_information": [
{
'prompt': prompt_1,
'response': response_1,
'category': 'math',
'claim': claim_1,
'testcases_queries': [testcase_query_11, testcase_query_12, testcase_query_13],
'potential_solutions_queries': [potential_solution_query_11, potential_solution_query_12, potential_solution_query_13],
'exec_results': [[evidences_111, evidences_112, evidences_113], [evidences_121, evidences_122, evidences_123], [evidences_131, evidences_132, evidences_133]],
'claim_level_factuality': factuality_1,
'response_level_factuality': factuality_1,
},
{
'prompt': prompt_2,
'response': response_2,
'category': 'math',
'claim': claim_2,
'testcases_queries': [testcase_query_21, testcase_query_22, testcase_query_23],
'potential_solutions_queries': [potential_solution_query_21, potential_solution_query_22, potential_solution_query_23],
'exec_results': [[evidences_211, evidences_212, evidences_213], [evidences_221, evidences_222, evidences_223], [evidences_231, evidences_232, evidences_233]],
'claim_level_factuality': factuality_2,
'response_level_factuality': factuality_2,
},
]
...
}
在这种情况下,你将得到:
{
"average_claim_level_factuality": 0.0,
"average_response_level_factuality": 0.0,
"detailed_information": [
{
'prompt': '斯蒂芬在网上订购了杂货。他的最终账单为7023116美元。由于这是通过配送供应商完成的,他们在最终总额上加收了25%的费用,并收取了3.00美元的配送费。斯蒂芬还额外给了4.00美元的小费。在加上额外费用后,斯蒂芬的杂货最终价格是多少?',
'response': '好的,以下是解决这个问题的步骤:\n* 斯蒂芬的初始杂货账单是7023116美元\n* 配送供应商在此基础上加收25%的费用。7023116美元的25%是0.25 * 7023116美元 = 1755779美元\n* 他们还收取了3美元的固定配送费\n* 斯蒂芬额外给了4美元的小费\n* 所以总费用是:\n * 初始杂货费:7023116美元\n * 25%的费用:1755779美元\n * 配送费:3美元\n * 小费:4美元\n* 将所有这些加起来,最终总价是7023116美元 + 1755779美元 + 3美元 + 4美元 = 8779902美元\n\n所以斯蒂芬的杂货最终价格是8779902美元',
'category': 'math',
'claim': '斯蒂芬的杂货最终价格是8779902美元',
'testcases_queries': ['初始杂货账单是多少?', '配送供应商加收的25%费用是多少?', '最终总价是多少?'],
'potential_solutions_queries': ['初始杂货账单:7023116美元\n25%的费用:7023116 * 0.25 = 1755779美元\n配送费:3美元\n小费:4美元\n最终总价:7023116 + 1755779 + 3 + 4 = 8778902美元', '初始杂货账单:7023116美元\n25%的费用:7023116 * 0.25 = 1755779美元\n配送费:3美元\n小费:4美元\n最终总价:7023116 + 1755779 + 3 + 4 = 8778902美元\n\n因此,斯蒂芬的杂货最终价格是8778902美元', '初始杂货账单 = 7023116美元\n25%费用 = 7023116 * 0.25 = 1755779美元\n配送费 = 3美元\n小费 = 4美元\n最终总价 = 7023116 + 1755779 + 3 + 4 = 8778902美元\n\n斯蒂芬的杂货最终价格是8778902美元'],
'exec_results': [['7023116美元', '7023116美元', '7023116美元'], ['1755779美元', '1755779美元', '1755779美元'], ['8778902美元', '8778902美元', '8778902美元']],
'claim_level_factuality': False,
'response_level_factuality': False
}
]
}
{
"average_claim_level_factuality": avg_claim_level_factuality,
"average_response_level_factuality": avg_response_level_factuality,
"detailed_information": [
{
'prompt': prompt_1,
'response': response_1,
'category': 'scientific',
'claims': [claim_11, claim_12, ..., claims_1n],
'queries': [query_11, query_12, ..., query_1n],
'execution_results': [exec_result_11, exec_result_12, ..., exec_result_1n],
'claim_level_factuality': [factuality_11, factuality_12, ..., factuality_1n],
'response_level_factuality': factuality_1
},
{
'prompt': prompt_2,
'response': response_2,
'category': 'scientific',
'claims': [claim_21, claim_22, ..., claims_2n],
'queries': [query_21, query_22, ..., query_2n],
'execution_results': [exec_result_21, exec_result_22, ..., exec_result_2n],
'claim_level_factuality': [factuality_21, factuality_22, ..., factuality_2n],
'response_level_factuality': factuality_2
},
...
]
}
在这种情况下,你将得到:
{
"average_claim_level_factuality": 0.5,
"average_response_level_factuality": 0.0,
"detailed_information": [
{
'prompt': "详细说明机器学习算法如何应用于数据分析以及训练这些算法所涉及的过程。请引用相关研究论文或教科书来支持你的观点,包括作者姓名、作品标题和出版年份。",
'category': 'scientific',
'response': "机器学习算法在数据分析中发挥着至关重要的作用。它们被用来从大型数据集中提取洞察和知识,这些洞察和知识可用于做出明智的决策和预测。以下是训练机器学习算法所涉及的过程:\n\n1. 数据预处理:训练机器学习算法的第一步是预处理数据。这涉及清理数据、处理缺失值、编码分类变量和缩放数据。预处理的目的是确保数据以机器学习算法可以使用的格式呈现。\n2. 特征选择:数据预处理完成后,下一步是选择将用于训练机器学习算法的相关特征。这涉及识别对预测目标变量最重要的特征。特征选择可以使用各种技术进行,如过滤方法、包装方法和嵌入方法。\n3. 模型选择:特征选择之后,下一步是选择适当的机器学习算法使用。有各种类型的机器学习算法,如监督学习、非监督学习和强化学习。算法的选择取决于问题的性质和可用数据的类型。\n4. 训练模型:选择模型后,下一步是使用预处理的数据训练机器学习算法。这涉及使用一组训练数据来优化模型的参数,以便它能准确预测目标变量。\n5. 模型评估:模型训练完成后,下一步是评估其性能。这涉及在单独的测试数据集上测试模型,并测量其准确性、精确度、召回率和其他性能指标。\n6. 模型部署:模型经过评估和微调后,可以部署到生产环境中。这涉及将模型集成到更大的系统或工作流程中,并随时间监控其性能。\n\n支持上述观点的研究论文和教科书包括:\n\n* Alpaydin, B.(2010)的《机器学习导论》,提供了机器学习算法及其应用的全面概述。\n* Han, J., Kamber, B., & Pei, J.(2011)的《数据挖掘:概念与技术》,提供了数据挖掘及其应用的详细介绍。\n* Kamber, B., & Pei, J.(2012)的《机器学习:趋势、观点和前景》,概述了机器学习的当前趋势和未来前景。\n* He, C., & Wang, Y.(2015)的《数据挖掘的机器学习》,深入介绍了机器学习算法及其在数据挖掘中的应用。",
'claims': [
{'citation': 'Alpaydin, B. (2010). An Introduction to Machine Learning'},
{'citation': 'Han, J., Kamber, B., & Pei, J. (2011). Data Mining: Concepts and Techniques'},
{'citation': 'Kamber, B., & Pei, J. (2012). Machine Learning: Trends, Perspectives, and Prospects'},
{'citation': 'He, C., & Wang, Y. (2015). Machine Learning for Data Mining'}
],
'queries': [
{'google_scholar_search': 'Alpaydin, B. (2010). An Introduction to Machine Learning'},
{'google_scholar_search': 'Han, J., Kamber, B., & Pei, J. (2011). Data Mining: Concepts and Techniques'},
{'google_scholar_search': 'Kamber, B., & Pei, J. (2012). Machine Learning: Trends, Perspectives, and Prospects'},
{'google_scholar_search': 'He, C., & Wang, Y. (2015). Machine Learning for Data Mining'}
],
'execution_results': [
'Citation found: Alpaydin, E. (2010). Introduction to machine learning. MIT press.',
'Citation found: Han, J., Pei, J., & Kamber, M. (2011). Data mining: concepts and techniques. Elsevier.',
'Citation not found',
'Citation not found'
],
'claim_level_factuality': [True, True, False, False],
'response_level_factuality': False
}
]
}
{
"average_claim_level_factuality": avg_claim_level_factuality,
"average_response_level_factuality": avg_response_level_factuality,
"detailed_information": [
{
'prompt': prompt_1,
'response': response_1,
'category': '科学',
'claims': [claim_11, claim_12, ..., claims_1n],
'queries': [query_11, query_12, ..., query_1n],
'evidences': [evidences_11, evidences_12, ..., evidences_1n],
'claim_level_factuality': [{claim_11, evidence_11, error_11, factuality_11}, {claim_12, evidence_12, error_12, factuality_12}, ..., {claim_1n, evidence_1n, error_1n, factuality_1n}],
'response_level_factuality': factuality_1
},
{
'prompt': prompt_2,
'response': response_2,
'category': '科学',
'claims': [claim_21, claim_22, ..., claims_2n],
'queries': [query_21, query_22, ..., query_2n],
'evidences': [evidences_21, evidences_22, ..., evidences_2n],
'claim_level_factuality': [{claim_21, evidence_21, error_21, factuality_21}, {claim_22, evidence_22, error_22, factuality_22}, ..., {claim_2n, evidence_2n, error_2n, factuality_2n}],
'response_level_factuality': factuality_2
},
...
]
}
在这种情况下,你将得到:
{
"average_claim_level_factuality": 0.0,
"average_response_level_factuality": 0.0,
"detailed_information": [
{
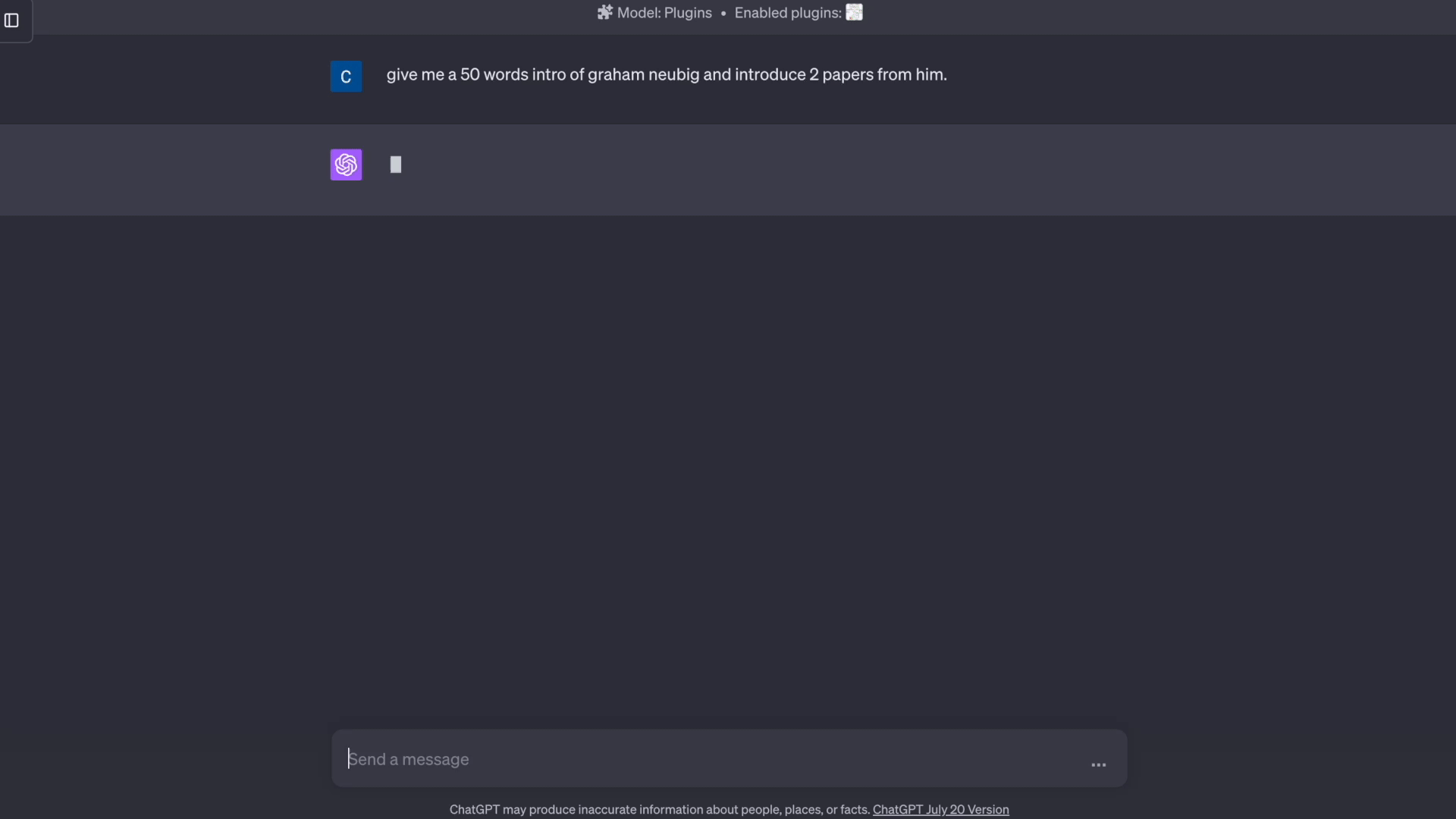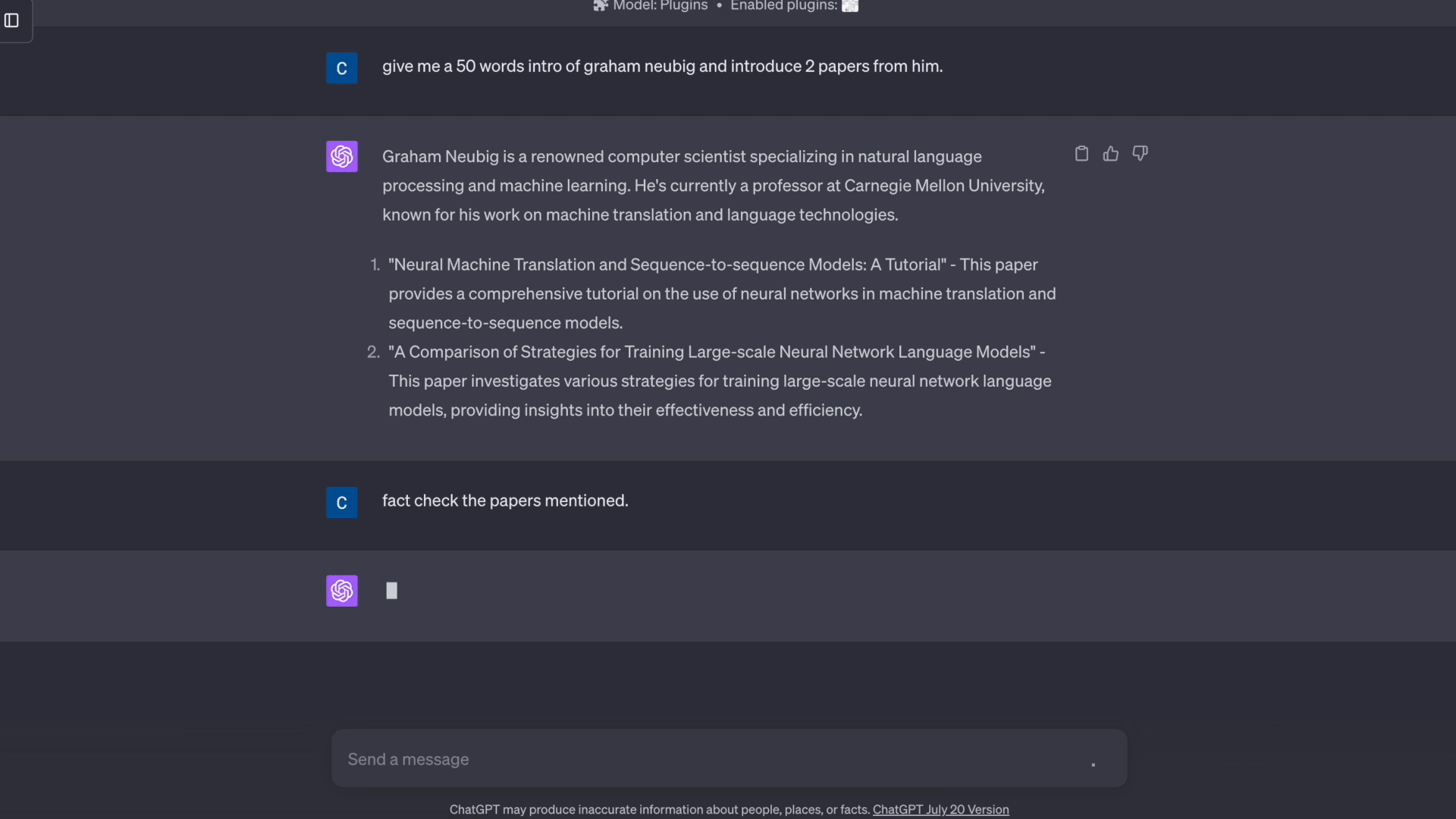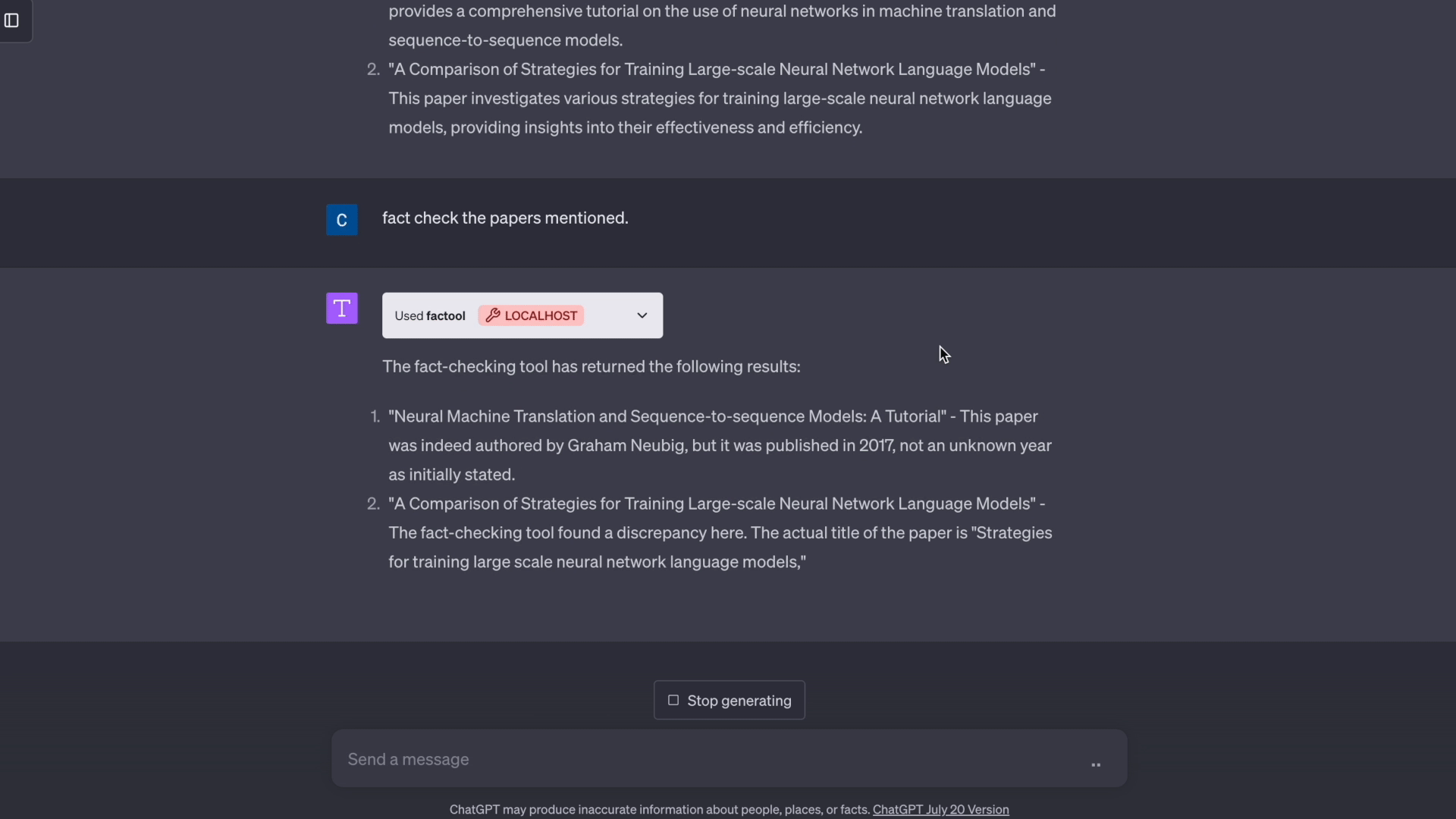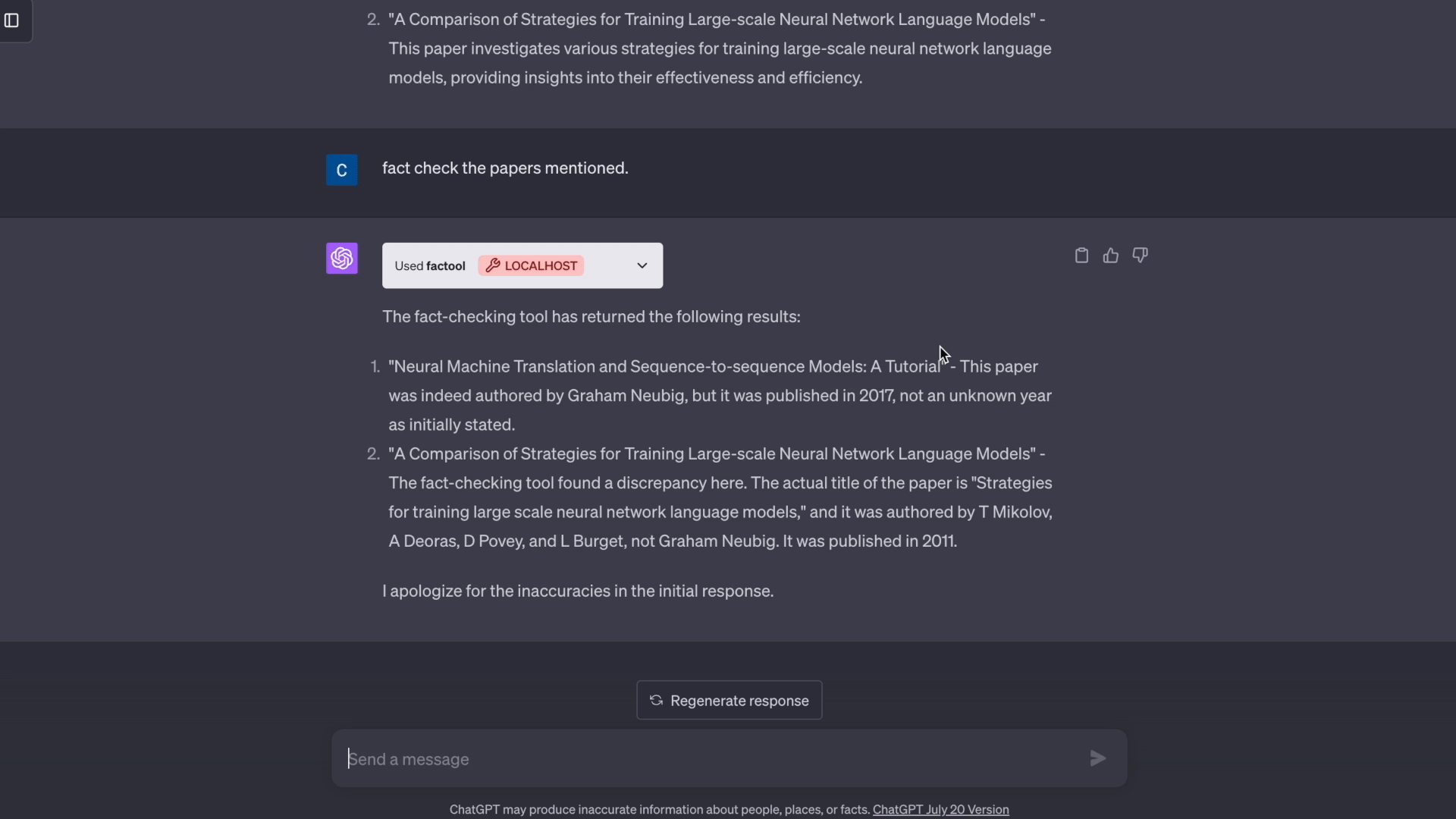
'prompt': "详细说明机器学习算法如何应用于数据分析以及训练这些算法所涉及的过程。请引用相关研究论文或教科书来支持你的观点,包括作者姓名、作品标题和出版年份。",
'response': '机器学习算法在数据分析中发挥着至关重要的作用。它们用于从大型数据集中提取洞察和知识,这些洞察和知识可用于做出明智的决策和预测。以下是训练机器学习算法所涉及的过程:\n\n1. 数据预处理:训练机器学习算法的第一步是预处理数据。这涉及清理数据、处理缺失值、编码分类变量和缩放数据。预处理的目的是确保数据格式适合机器学习算法使用。\n2. 特征选择:数据预处理完成后,下一步是选择用于训练机器学习算法的相关特征。这涉及识别对预测目标变量最重要的特征。特征选择可以使用各种技术完成,如过滤方法、包装方法和嵌入方法。\n3. 模型选择:特征选择之后,下一步是选择适当的机器学习算法。有各种类型的机器学习算法,如监督学习、无监督学习和强化学习。算法的选择取决于问题的性质和可用数据的类型。\n4. 训练模型:选择模型后,下一步是使用预处理的数据训练机器学习算法。这涉及使用训练数据集来优化模型的参数,以便准确预测目标变量。\n5. 模型评估:模型训练完成后,下一步是评估其性能。这涉及在单独的测试数据集上测试模型,并衡量其准确性、精确度、召回率和其他性能指标。\n6. 模型部署:模型经过评估和微调后,可以部署到生产环境中。这涉及将模型集成到更大的系统或工作流程中,并随时间监控其性能。\n\n支持上述观点的研究论文和教科书包括:\n\n* Alpaydin, B.(2010年)的《机器学习导论》,该书全面概述了机器学习算法及其应用。\n* Han, J.、Kamber, B.和Pei, J.(2011年)的《数据挖掘:概念与技术》,该书详细介绍了数据挖掘及其应用。\n* Kamber, B.和Pei, J.(2012年)的《机器学习:趋势、展望和前景》,该书概述了机器学习的当前趋势和未来前景。\n* He, C.和Wang, Y.(2015年)的《数据挖掘的机器学习》,该书深入介绍了机器学习算法及其在数据挖掘中的应用。',
'category': '科学',
'claims': [{'paper_title': '机器学习导论', 'paper_author(s)': 'Alpaydin, B.', 'paper_pub_year': '2010'}, {'paper_title': '数据挖掘:概念与技术', 'paper_author(s)': 'Han, J., Kamber, B., & Pei, J.', 'paper_pub_year': '2011'}, {'paper_title': '机器学习:趋势、展望和前景', 'paper_author(s)': 'Kamber, B., & Pei, J.', 'paper_pub_year': '2012'}, {'paper_title': '数据挖掘的机器学习', 'paper_author(s)': 'He, C., & Wang, Y.', 'paper_pub_year': '2015'}],
'queries': ['机器学习导论', '数据挖掘:概念与技术', '机器学习:趋势、展望和前景', '数据挖掘的机器学习'],
'evidences': [{'title': '机器学习导论', 'author': ['Y Baştanlar', 'M Özuysal'], 'pub_year': '2014'}, {'title': '数据挖掘:数据挖掘概念与技术', 'author': ['S Agarwal'], 'pub_year': '2013'}, {'title': '机器学习:趋势、展望和前景', 'author': ['MI Jordan', 'TM Mitchell'], 'pub_year': '2015'}, {'title': '机器学习与数据挖掘', 'author': ['TM Mitchell'], 'pub_year': '1999'}],
'claim_level_factuality': [{'generated_paper_title': '机器学习导论', 'generated_paper_author(s)': 'Alpaydin, B.', 'generated_paper_pub_year': '2010', 'actual_paper_title': '机器学习导论', 'actual_paper_author(s)': ['Y Baştanlar', 'M Özuysal'], 'actual_paper_pub_year': '2014', 'error': ['wrong_paper_author(s)', 'wrong_paper_pub_year'], 'factuality': False}, {'generated_paper_title': '数据挖掘:概念与技术', 'generated_paper_author(s)': 'Han, J., Kamber, B., & Pei, J.', 'generated_paper_pub_year': '2011', 'actual_paper_title': '数据挖掘:数据挖掘概念与技术', 'actual_paper_author(s)': ['S Agarwal'], 'actual_paper_pub_year': '2013', 'error': ['wrong_paper_title', 'wrong_paper_author(s)', 'wrong_paper_pub_year'], 'factuality': False}, {'generated_paper_title': '机器学习:趋势、展望和前景', 'generated_paper_author(s)': 'Kamber, B., & Pei, J.', 'generated_paper_pub_year': '2012', 'actual_paper_title': '机器学习:趋势、展望和前景', 'actual_paper_author(s)': ['MI Jordan', 'TM Mitchell'], 'actual_paper_pub_year': '2015', 'error': ['wrong_paper_author(s)', 'wrong_paper_pub_year'], 'factuality': False}, {'generated_paper_title': '数据挖掘的机器学习', 'generated_paper_author(s)': 'He, C., & Wang, Y.', 'generated_paper_pub_year': '2015', 'actual_paper_title': '机器学习与数据挖掘', 'actual_paper_author(s)': ['TM Mitchell'], 'actual_paper_pub_year': '1999', 'error': ['wrong_paper_title', 'wrong_paper_author(s)', 'wrong_paper_pub_year'], 'factuality': False}],
'response_level_factuality': False
}
]
}
视频(点击切换内容)
基于知识的问答:
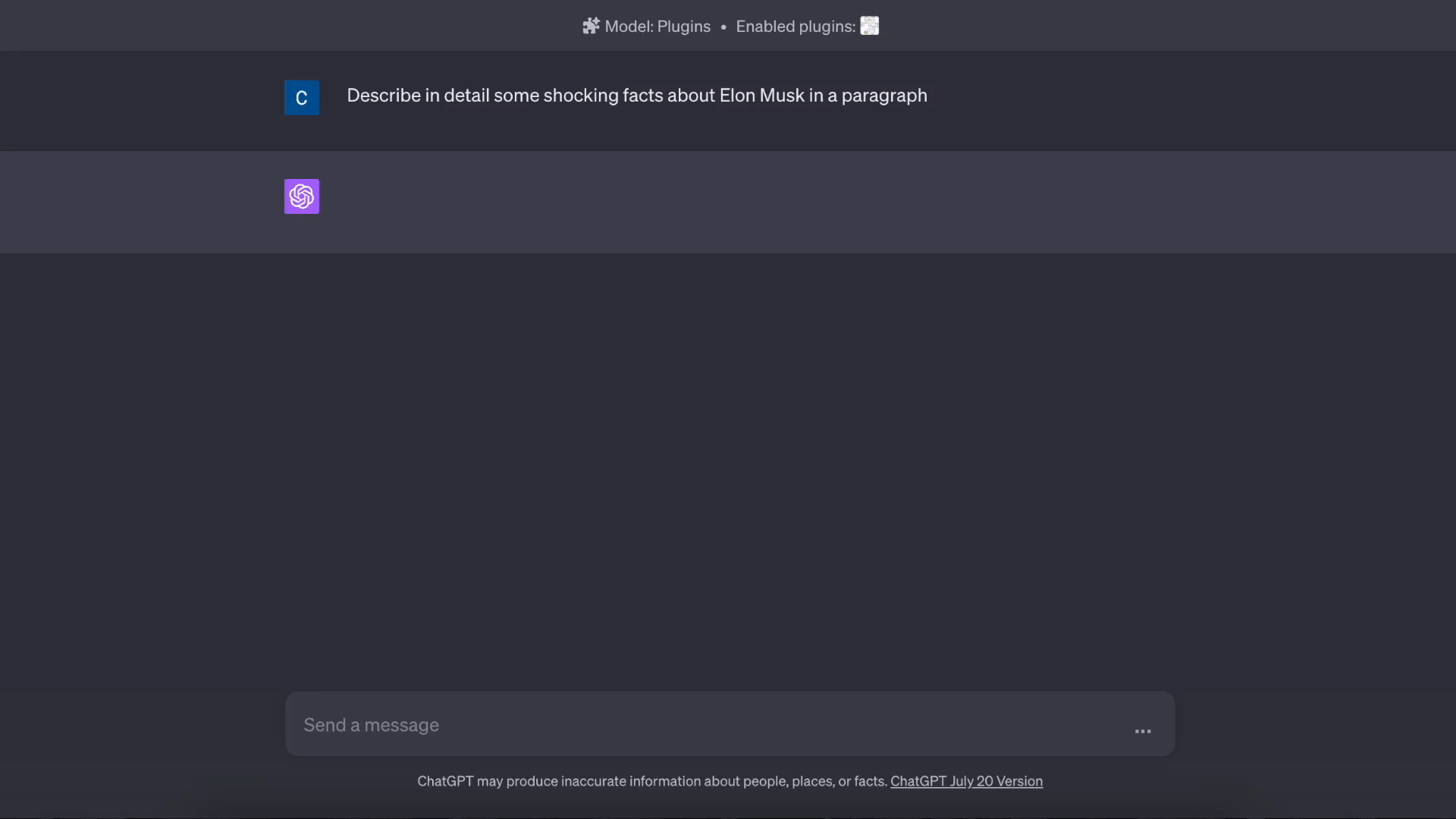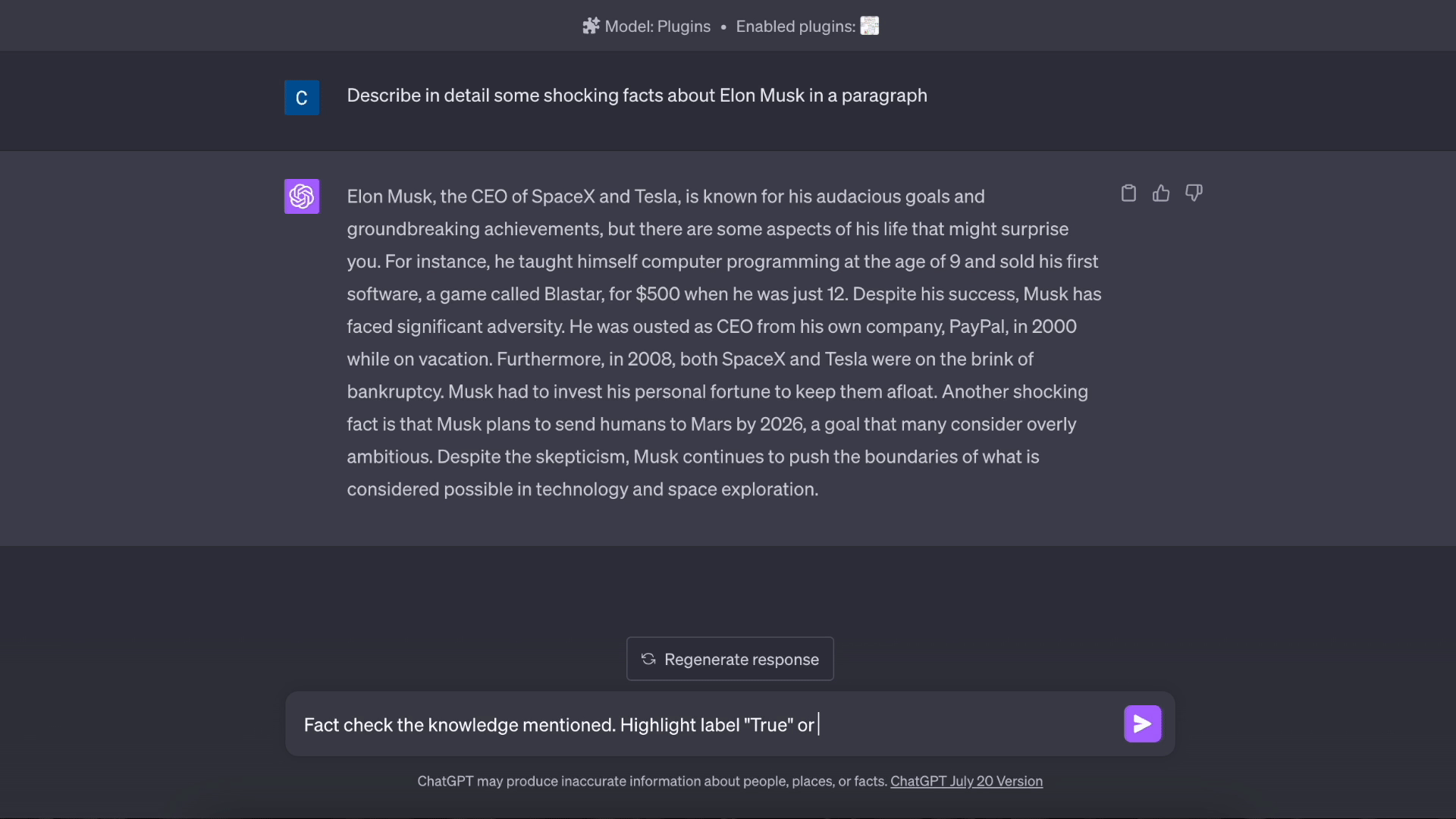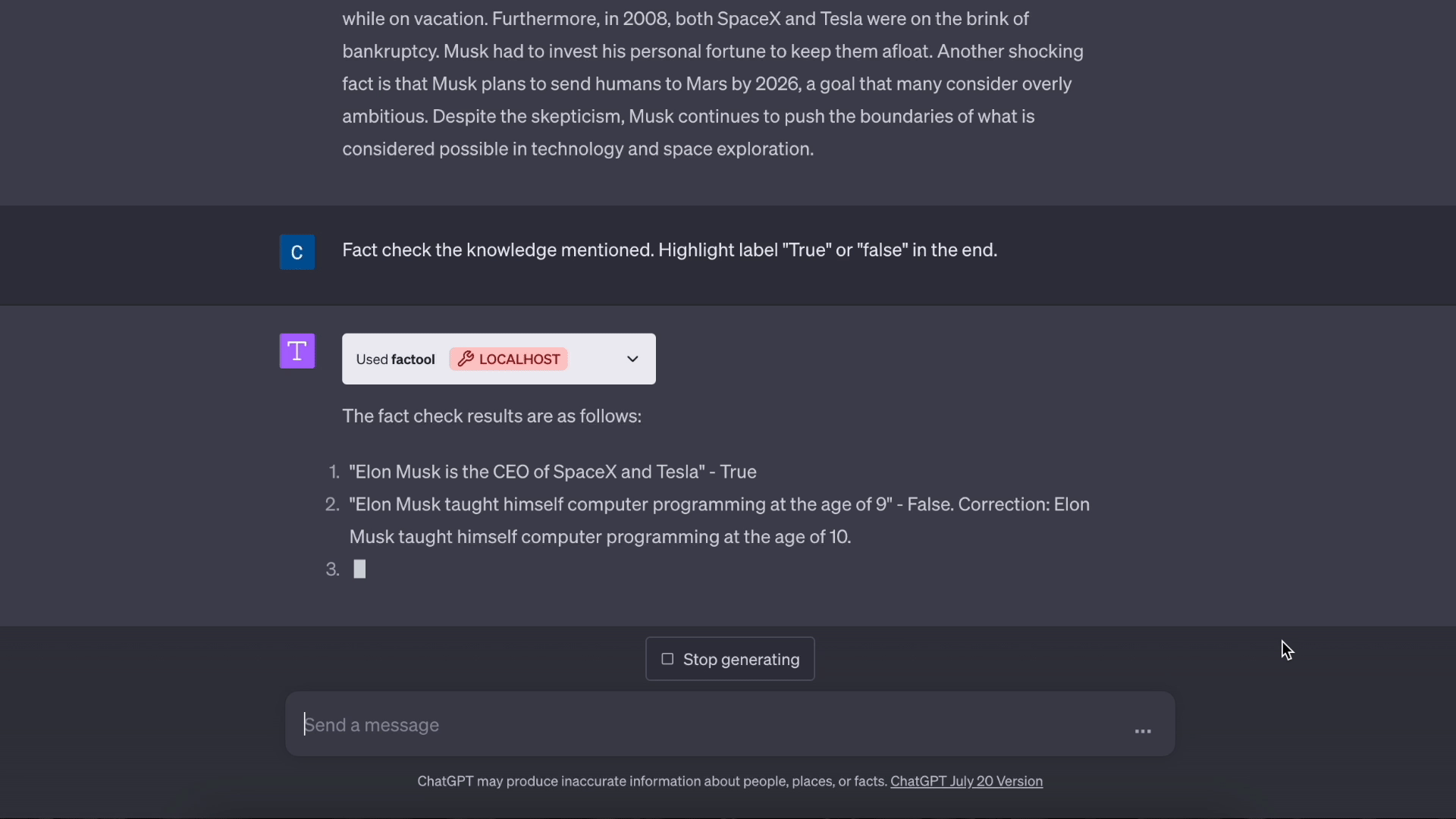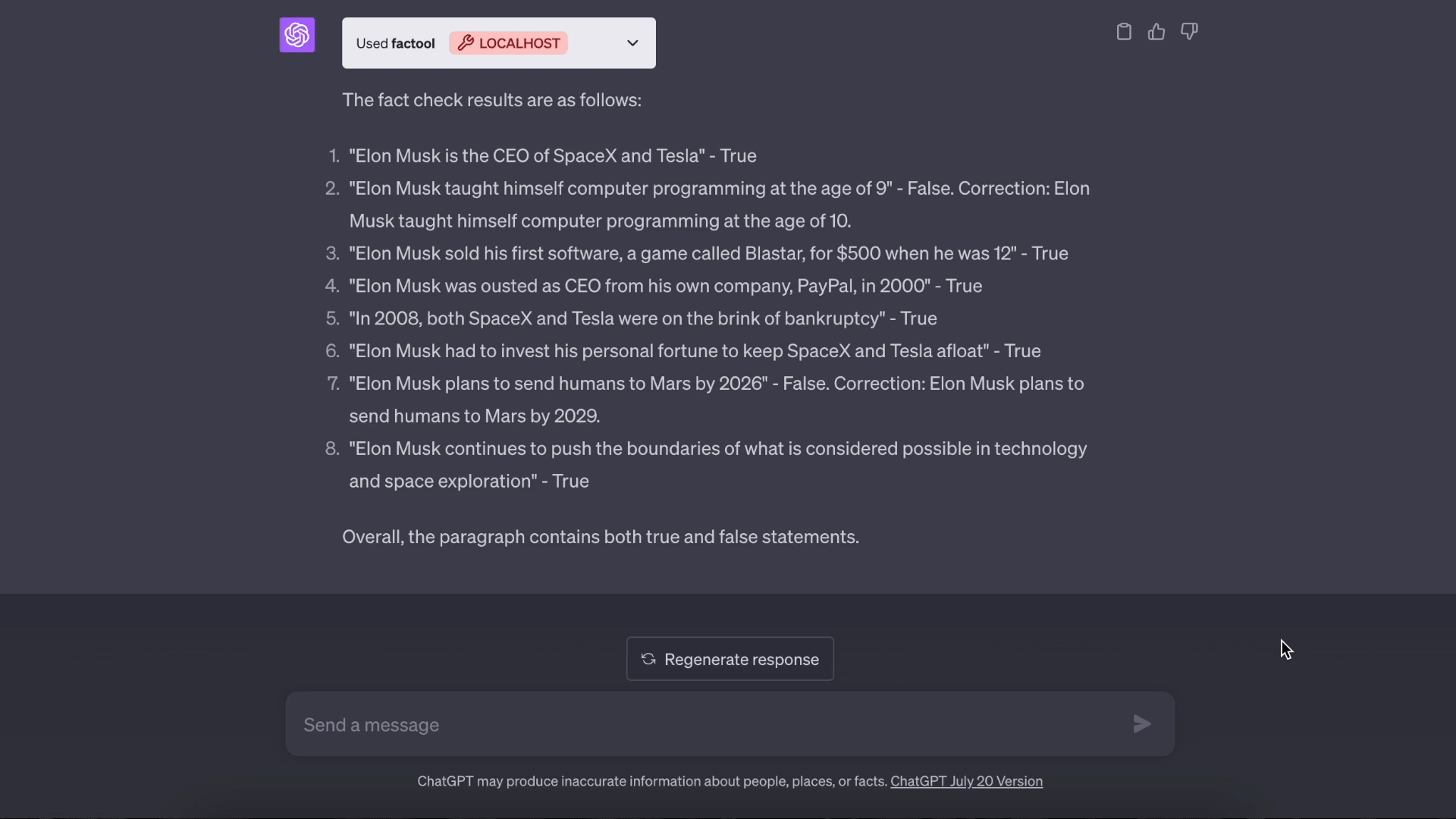
代码:
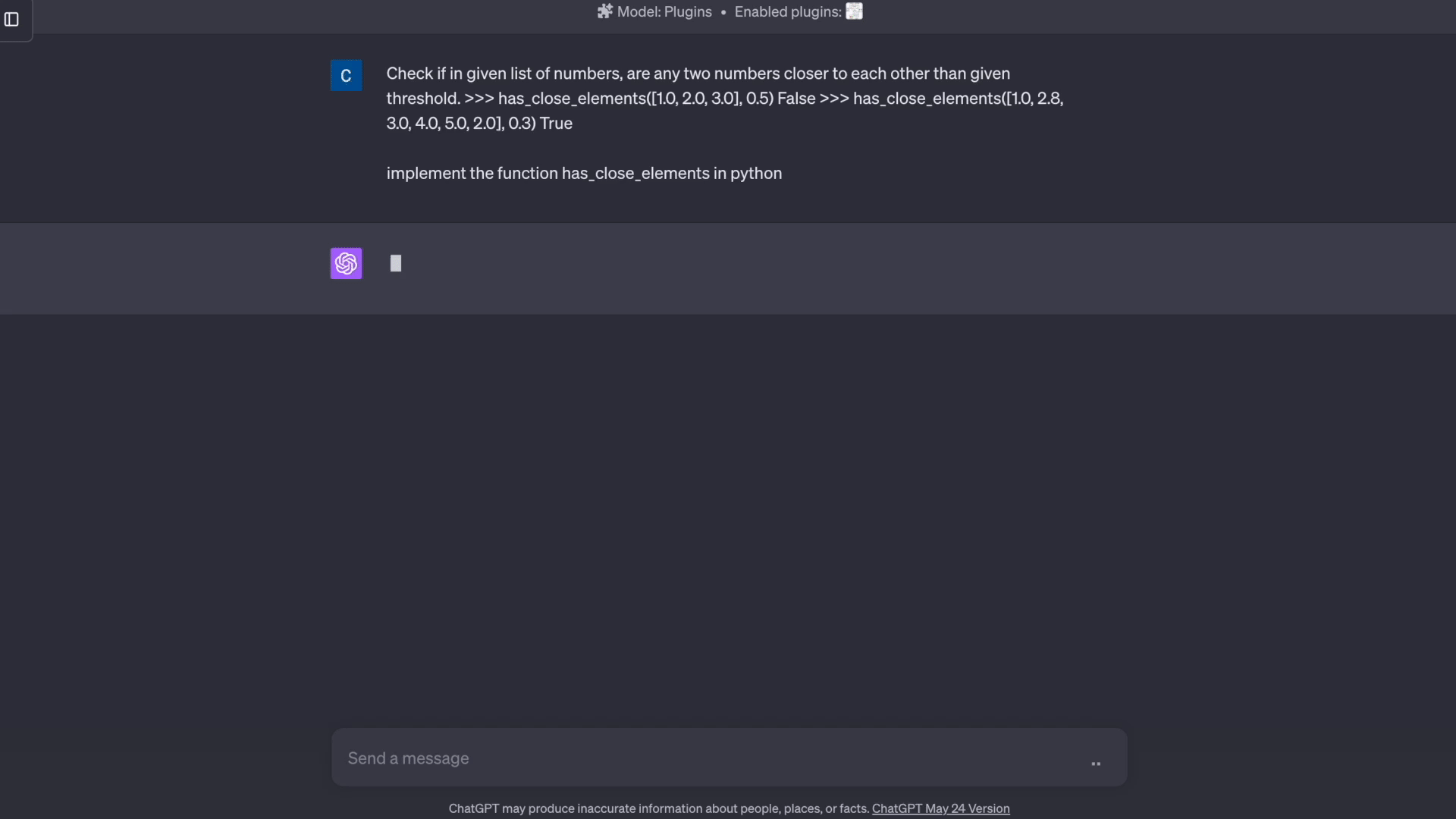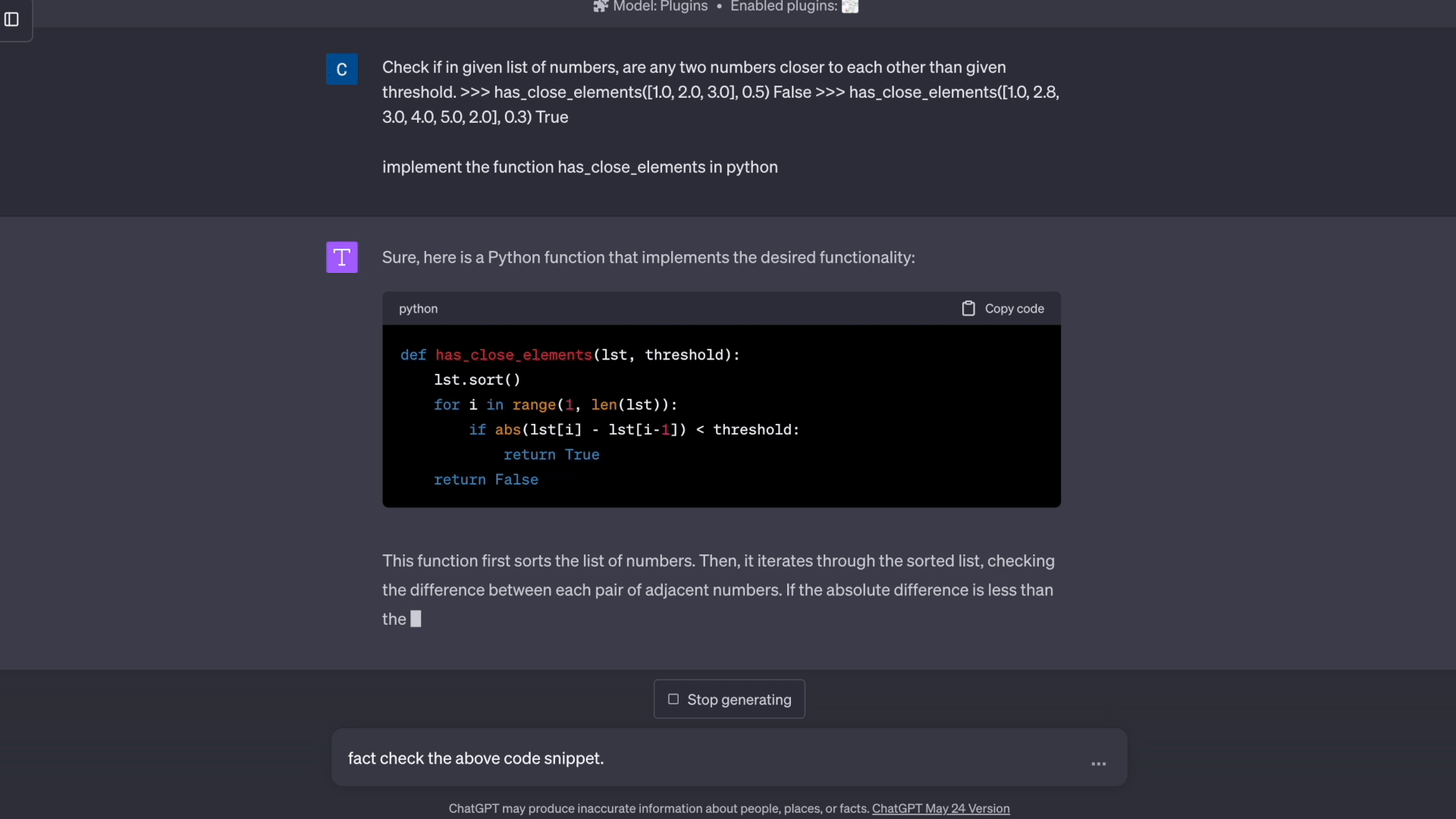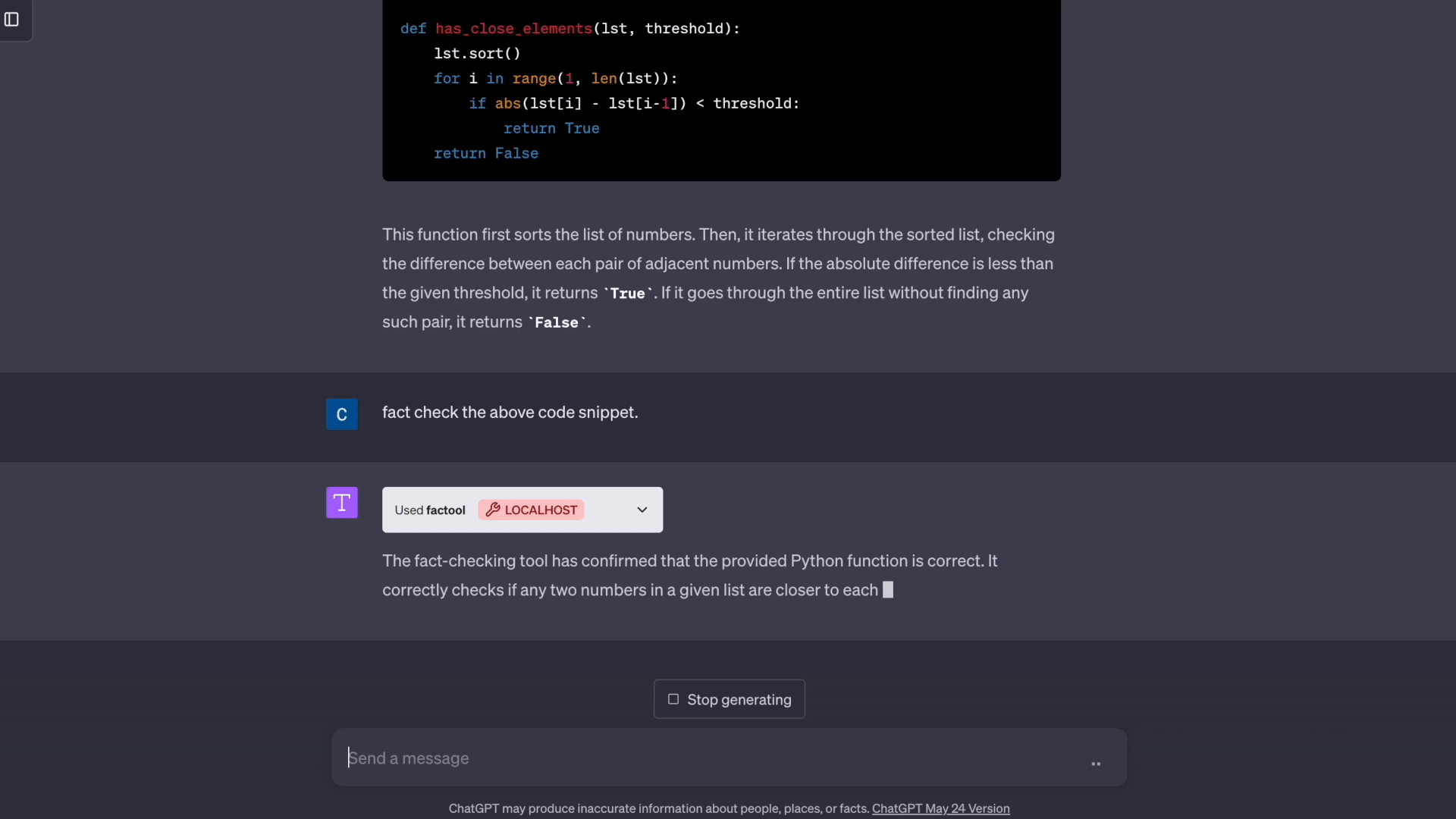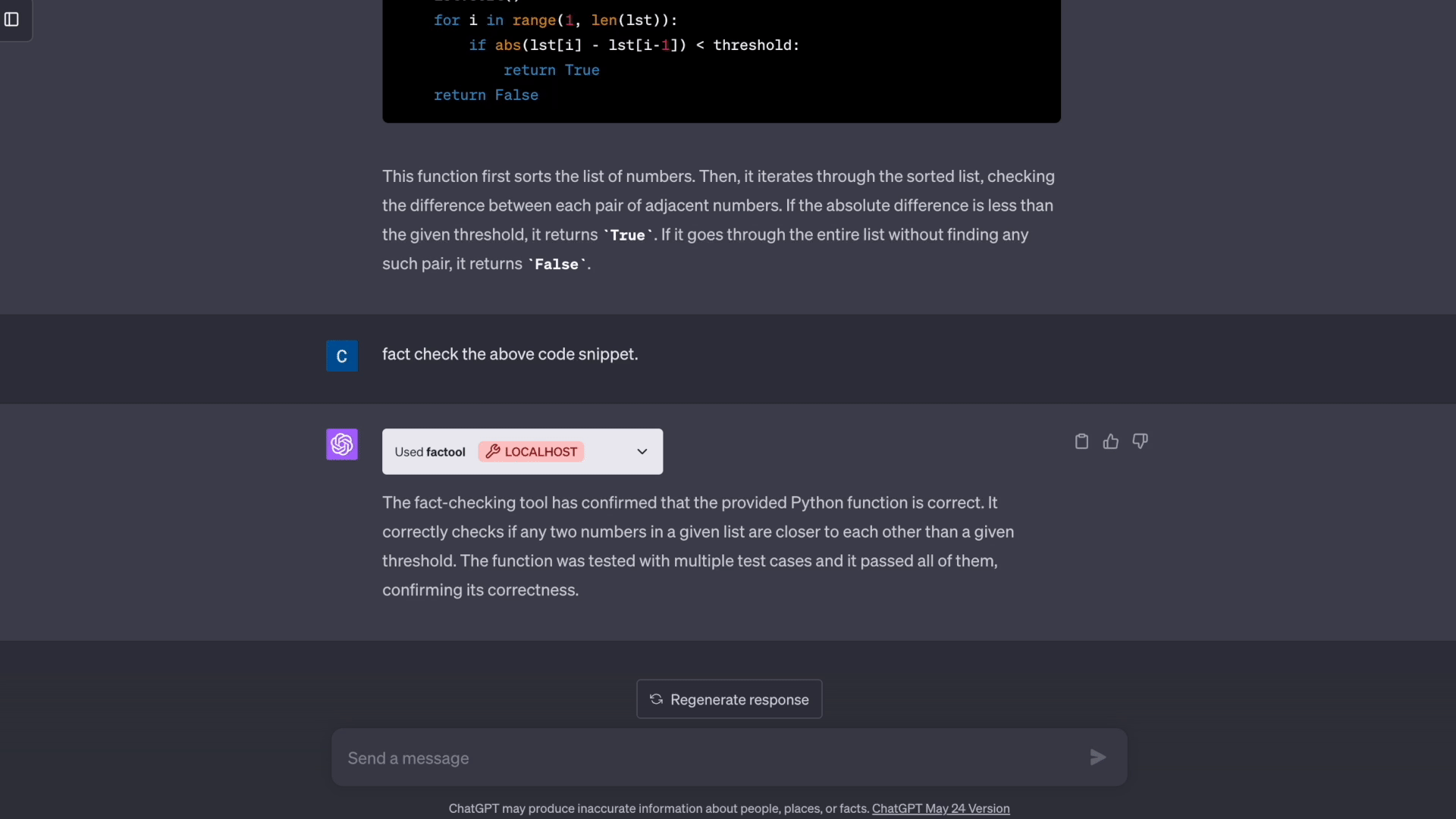
数学:
科学文献综述:
引用
如果您觉得本仓库有帮助,请引用我们的论文。
@article{chern2023factool,
title={FacTool: Factuality Detection in Generative AI--A Tool Augmented Framework for Multi-Task and Multi-Domain Scenarios},
author={Chern, I-Chun and Chern, Steffi and Chen, Shiqi and Yuan, Weizhe and Feng, Kehua and Zhou, Chunting and He, Junxian and Neubig, Graham and Liu, Pengfei and others},
journal={arXiv preprint arXiv:2307.13528},
year={2023}
}











