
 Github
Github 文档
文档 论文
论文密集目标检测的定位知识蒸馏
英文 | 简体中文
旋转目标检测的Rotated-LD-mmRotate和Rotated-LD-Jittor已发布。
本仓库基于mmDetection。
LD在知乎上的分析:目标检测-定位蒸馏 (LD, CVPR 2022)和目标检测-定位蒸馏续集——logit蒸馏与feature蒸馏之争
这是我们论文的代码:
- 密集目标检测的定位蒸馏
- 目标检测的定位蒸馏期刊扩展版。
@Inproceedings{LD,
title={密集目标检测的定位蒸馏},
author={郑昭慧 and 叶荣光 and 王平 and 任东伟 and 左旺孟 and 侯启彬 and 程明明},
booktitle={IEEE/CVF计算机视觉与模式识别会议论文集(CVPR)},
pages={9407--9416},
year={2022}
}
@Article{zheng2023rotatedLD,
title={目标检测的定位蒸馏},
author= {郑昭慧 and 叶荣光 and 侯启彬 and 任东伟 and 王平 and 左旺孟 and 程明明},
journal={IEEE模式分析与机器智能汇刊},
year={2023},
volume={45},
number={8},
pages={10070-10083},
doi={10.1109/TPAMI.2023.3248583}}
[2022.12.3] Rotated-LD-Jittor现已可用。
[2022.4.13] Rotated-LD-mmRotate现已可用。
[2021.3.30] LD正式纳入MMDetection V2,非常感谢@jshilong、@Johnson-Wang和@ZwwWayne协助迁移代码。
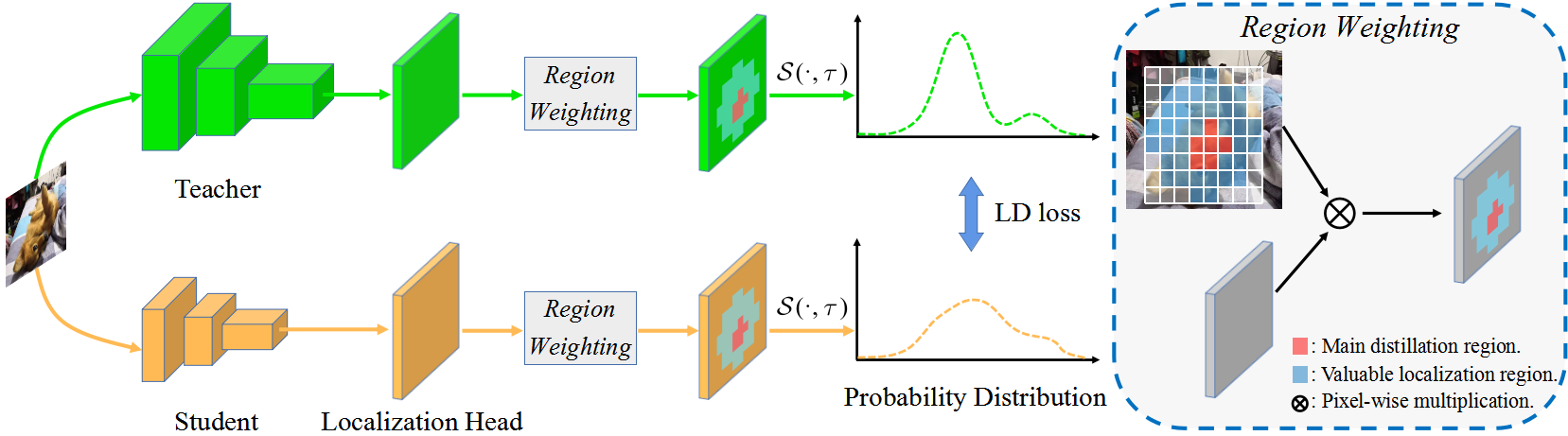
LD是定位任务知识蒸馏的扩展,利用学习到的边界框分布将定位暗知识从教师模型传递给学生模型。
LD稳定地将GFocalV1的性能提高了约2.0的AP,而不增加任何计算成本!
简介
知识蒸馏(KD)在学习目标检测的紧凑模型方面展现了强大的能力。之前的目标检测KD方法主要集中在模仿特定区域内的深层特征,而不是模仿分类logits,因为后者在蒸馏定位信息方面效率不高。在本文中,通过重新制定定位任务的知识蒸馏过程,我们提出了一种新颖的定位蒸馏(LD)方法,可以有效地将定位知识从教师模型传递给学生模型。此外,我们还启发式地引入了有价值定位区域的概念,可以帮助选择性地为特定区域蒸馏语义和定位知识。结合这两个新组件,我们首次表明,logit模仿可以优于特征模仿,而且对于蒸馏目标检测器来说,定位知识蒸馏比语义知识更重要和高效。我们的蒸馏方案既简单又有效,可以轻松应用于不同的密集目标检测器。实验表明,我们的LD可以将单尺度1x训练计划的GFocal-ResNet-50的AP分数从40.1提高到42.1,而不会牺牲任何推理速度。
安装
请参考INSTALL.md进行安装和数据集准备。推荐使用Pytorch=1.7和cudatoolkits=11。
入门
请参阅GETTING_STARTED.md了解MMDetection的基本用法。
训练
# 假设你在项目的根目录下,
# 并且已经激活了虚拟环境(如果需要的话)。
# COCO数据集位于'data/coco/'目录下
./tools/dist_train.sh configs/ld/ld_r50_gflv1_r101_fpn_coco_1x.py 8
学习率和批量大小设置
lr=(samples_per_gpu * num_gpu) / 16 * 0.01
对于2个GPU和每个GPU的mini-batch大小为6,配置文件的相关部分如下:
optimizer = dict(type='SGD', lr=0.00375, momentum=0.9, weight_decay=0.0001)
data = dict(
samples_per_gpu=3,
对于8个GPU和每个GPU的mini-batch大小为16,配置文件的相关部分如下:
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
data = dict(
samples_per_gpu=2,
不要将samples_per_gpu设置大于3!
特征模仿方法
我们提供了几种特征模仿方法,包括FitNets fitnet、DeFeat decouple、Fine-Grained finegrain、GI location gibox。
bbox_head=dict(
loss_im=dict(type='IMLoss', loss_weight=2.0),
imitation_method='finegrained' # gibox, finegrain, decouple, fitnet
)
转换模型
如果你发现训练好的模型很大,请参考publish_model.py
python tools/model_converters/publish_model.py your_model.pth your_new_model.pth
速度测试(FPS)
CUDA_VISIBLE_DEVICES=0 python3 ./tools/benchmark.py configs/ld/ld_gflv1_r101_r50_fpn_coco_1x.py work_dirs/ld_gflv1_r101_r50_fpn_coco_1x/epoch_24.pth
评估
./tools/dist_test.sh configs/ld/ld_gflv1_r101_r50_fpn_coco_1x.py work_dirs/ld_gflv1_r101_r50_fpn_coco_1x/epoch_24.pth 8 --eval bbox
COCO
- 轻量级检测器的LD
仅在主要蒸馏区域进行评估。
| 教师模型 | 学生模型 | 训练计划 | AP (验证集) | AP50 (验证集) | AP75 (验证集) | AP (测试开发集) | AP50 (测试开发集) | AP75 (测试开发集) | AR100 (测试开发集) |
|---|---|---|---|---|---|---|---|---|---|
| -- | R-18 | 1x | 35.8 | 53.1 | 38.2 | 36.0 | 53.4 | 38.7 | 55.3 |
| R-101 | R-18 | 1x | 36.5 | 52.9 | 39.3 | 36.8 | 53.5 | 39.9 | 56.6 |
| -- | R-34 | 1x | 38.9 | 56.6 | 42.2 | 39.2 | 56.9 | 42.3 | 58.0 |
| R-101 | R-34 | 1x | 39.8 | 56.6 | 43.1 | 40.0 | 57.1 | 43.5 | 59.3 |
| -- | R-50 | 1x | 40.1 | 58.2 | 43.1 | 40.5 | 58.8 | 43.9 | 59.0 |
| R-101 | R-50 | 1x | 41.1 | 58.7 | 44.9 | 41.2 | 58.8 | 44.7 | 59.8 |
| -- | R-101 | 2x | 44.6 | 62.9 | 48.4 | 45.0 | 63.6 | 48.9 | 62.3 |
| R-101-DCN | R-101 | 2x | 45.4 | 63.1 | 49.5 | 45.6 | 63.7 | 49.8 | 63.3 |
- 自蒸馏LD
仅在主要蒸馏区域进行评估。
| 教师模型 | 学生模型 | 训练计划 | AP (验证集) | AP50 (验证集) | AP75 (验证集) |
|---|---|---|---|---|---|
| -- | R-18 | 1x | 35.8 | 53.1 | 38.2 |
| R-18 | R-18 | 1x | 36.1 | 52.9 | 38.5 |
| -- | R-50 | 1x | 40.1 | 58.2 | 43.1 |
| R-50 | R-50 | 1x | 40.6 | 58.2 | 43.8 |
| -- | X-101-32x4d-DCN | 1x | 46.9 | 65.4 | 51.1 |
| X-101-32x4d-DCN | X-101-32x4d-DCN | 1x | 47.5 | 65.8 | 51.8 |
- 逻辑模仿vs特征模仿
本方法 = 主要KD + 主要LD + VLR LD。"主要"表示主要蒸馏区域,"VLR"表示有价值的定位区域。教师模型为R-101,学生模型为R-50。
| 方法 | 训练计划 | AP (验证集) | AP50 (验证集) | AP75 (验证集) | APs (验证集) | APm (验证集) | APl (验证集) |
|---|---|---|---|---|---|---|---|
| -- | 1x | 40.1 | 58.2 | 43.1 | 23.3 | 44.4 | 52.5 |
| FitNets | 1x | 40.7 | 58.6 | 44.0 | 23.7 | 44.4 | 53.2 |
| 真实边界框内 | 1x | 40.7 | 58.6 | 44.2 | 23.1 | 44.5 | 53.5 |
| 主要区域 | 1x | 41.1 | 58.7 | 44.4 | 24.1 | 44.6 | 53.6 |
| 细粒度 | 1x | 41.1 | 58.8 | 44.8 | 23.3 | 45.4 | 53.1 |
| DeFeat | 1x | 40.8 | 58.6 | 44.2 | 24.3 | 44.6 | 53.7 |
| GI 模仿 | 1x | 41.5 | 59.6 | 45.2 | 24.3 | 45.7 | 53.6 |
| 本方法 | 1x | 42.1 | 60.3 | 45.6 | 24.5 | 46.2 | 54.8 |
PASCAL VOC
-
轻量级检测器的LD
仅在主要蒸馏区域进行评估。
教师网络 学生网络 训练轮数 AP AP50 AP75 -- R-18 4 51.8 75.8 56.3 R-101 R-18 4 53.0 75.9 57.6 -- R-50 4 55.8 79.0 60.7 R-101 R-50 4 56.1 78.5 61.2 -- R-34 4 55.7 78.9 60.6 R-101-DCN R-34 4 56.7 78.4 62.1 -- R-101 4 57.6 80.4 62.7 R-101-DCN R-101 4 58.4 80.2 63.7 这是一个评估结果示例(R-101→R-18)。
+-------------+------+-------+--------+-------+ | 类别 | gts | dets | recall | ap | +-------------+------+-------+--------+-------+ | 飞机 | 285 | 4154 | 0.081 | 0.030 | | 自行车 | 337 | 7124 | 0.125 | 0.108 | | 鸟 | 459 | 5326 | 0.096 | 0.018 | | 船 | 263 | 8307 | 0.065 | 0.034 | | 瓶子 | 469 | 10203 | 0.051 | 0.045 | | 公共汽车 | 213 | 4098 | 0.315 | 0.247 | | 汽车 | 1201 | 16563 | 0.193 | 0.131 | | 猫 | 358 | 4878 | 0.254 | 0.128 | | 椅子 | 756 | 32655 | 0.053 | 0.027 | | 奶牛 | 244 | 4576 | 0.131 | 0.109 | | 餐桌 | 206 | 13542 | 0.150 | 0.117 | | 狗 | 489 | 6446 | 0.196 | 0.076 | | 马 | 348 | 5855 | 0.144 | 0.036 | | 摩托车 | 325 | 6733 | 0.052 | 0.017 | | 人 | 4528 | 51959 | 0.099 | 0.037 | | 盆栽植物 | 480 | 12979 | 0.031 | 0.009 | | 羊 | 242 | 4706 | 0.132 | 0.060 | | 沙发 | 239 | 9640 | 0.192 | 0.060 | | 火车 | 282 | 4986 | 0.142 | 0.042 | | 电视监视器 | 308 | 7922 | 0.078 | 0.045 | +-------------+------+-------+--------+-------+ | mAP | | | | 0.069 | +-------------+------+-------+--------+-------+ AP: 0.530091167986393 ['AP50: 0.759393', 'AP55: 0.744544', 'AP60: 0.724239', 'AP65: 0.693551', 'AP70: 0.639848', 'AP75: 0.576284', 'AP80: 0.489098', 'AP85: 0.378586', 'AP90: 0.226534', 'AP95: 0.068834'] {'mAP': 0.7593928575515747}
注意:
- 有关更多实验细节,请参考 GFocalV1、GFocalV2 和 mmdetection。
预训练权重
VOC 07+12
GFocal V1
百度网盘 密码: ufc8,教师网络 R101
百度网盘 密码: 5qra,教师网络 R101DCN
百度网盘 密码: 1bd3,主要LD R101→R18,框AP = 53.0
百度网盘 密码: thuw,主要LD R101DCN→R34,框AP = 56.5
百度网盘 密码: mp8t,主要LD R101DCN→R101,框AP = 58.4
谷歌云盘 主要LD + VLR LD + VLR KD R101→R18,框AP = 54.0
谷歌云盘 主要LD + VLR LD + VLR KD + GI模仿 R101→R18,框AP = 54.4
COCO
GFocal V1
百度网盘 密码: hj8d,主要LD R101→R18 1x,框AP = 36.5
百度网盘 密码: bvzz,主要LD R101→R50 1x,框AP = 41.1 GoogleDrive 主要KD + 主要LD + VLR LD R101→R18 1x,框AP = 37.5
GoogleDrive 主要KD + 主要LD + VLR LD R101→R34 1x,框AP = 41.0
GoogleDrive 主要KD + 主要LD + VLR LD R101→R50 1x,框AP = 42.1
GoogleDrive 主要KD + 主要LD + VLR LD + GI模仿 R101→R50,框AP = 42.4
GFocal V2
GoogleDrive 主要KD + 主要LD + VLR LD R101→R50 1x,框AP = 42.7
GoogleDrive | 训练日志 主要KD + 主要LD + VLR LD R101-DCN→R101 2x,框AP(测试开发集)= 47.1
GoogleDrive | 训练日志 主要KD + 主要LD + VLR LD Res2Net101-DCN→X101-32x4d-DCN 2x,框AP(测试开发集)= 50.5
对于其他任何教师模型,您可以在GFocalV1、GFocalV2和mmdetection下载。
AP全景图
如果您想绘制AP全景图,请用AP_landscape中的文件替换相关文件,并运行
# config1和checkpoint1对应您想通过的头部
./tools/dist_test.py config1 config2 checkpoint1 checkpoint2 1
得分投票聚类DIoU-NMS
我们提供了得分投票聚类DIoU-NMS,这是得分投票NMS的加速版本,并与DIoU-NMS相结合。对于GFocalV1和GFocalV2,得分投票聚类DIoU-NMS将带来0.1-0.3的AP增加,0.2-0.5的AP75增加和<=0.4的AP50减少,同时它比mmdetection中的得分投票NMS快得多。配置文件的相关部分如下:
# 得分投票聚类DIoU-NMS
test_cfg = dict(
nms=dict(type='voting_cluster_diounms', iou_threshold=0.6),
# 原始NMS
test_cfg = dict(
nms=dict(type='nms', iou_threshold=0.6),











