
 Github
Github 论文
论文项目终止
Intel 将不再维护此项目。 此项目已被确定存在已知的安全漏洞。 Intel 已停止对该项目的开发和贡献,包括但不限于维护、错误修复、新版本发布或更新。 Intel 不再接受此项目的补丁。
在有限的计算/时间(学术)预算下训练 BERT
本仓库包含了在有限时间和计算预算下预训练和微调 BERT 类模型的脚本。 代码基于以下论文中提出的工作:
Peter Izsak, Moshe Berchansky, Omer Levy, 如何在学术预算内训练 BERT (EMNLP 2021)。
安装
预训练和微调脚本基于 Deepspeed 和 HuggingFace Transformers 库。
初步安装
我们建议创建一个包含 Python 3.6+、PyTorch 和 apex 的虚拟环境。
安装要求
pip install -r requirements.txt
我们建议运行 Deepspeed 的工具 ds_report 并验证 Deepspeed 组件是否可以编译(JIT)。
数据集
dataset 目录包含了用于预处理我们在实验中使用的数据集(维基百科、Bookcorpus)的脚本。详细信息请参阅专门的 README。
预训练
预训练脚本: run_pretraining.py
查看所有可能的预训练参数: python run_pretraining.py -h
我们强烈建议查看我们在库中提供的各种训练功能。
使用我们论文中提出的最佳配置进行训练的示例(24层/1024H/基于时间的学习率调度/fp16):
deepspeed run_pretraining.py \
--model_type bert-mlm --tokenizer_name bert-large-uncased \
--hidden_act gelu \
--hidden_size 1024 \
--num_hidden_layers 24 \
--num_attention_heads 16 \
--intermediate_size 4096 \
--hidden_dropout_prob 0.1 \
--attention_probs_dropout_prob 0.1 \
--encoder_ln_mode pre-ln \
--lr 1e-3 \
--train_batch_size 4096 \
--train_micro_batch_size_per_gpu 32 \
--lr_schedule time \
--curve linear \
--warmup_proportion 0.06 \
--gradient_clipping 0.0 \
--optimizer_type adamw \
--weight_decay 0.01 \
--adam_beta1 0.9 \
--adam_beta2 0.98 \
--adam_eps 1e-6 \
--total_training_time 24.0 \
--early_exit_time_marker 24.0 \
--dataset_path <数据集路径> \
--output_dir /tmp/training-out \
--print_steps 100 \
--num_epochs_between_checkpoints 10000 \
--job_name pretraining_experiment \
--project_name budget-bert-pretraining \
--validation_epochs 3 \
--validation_epochs_begin 1 \
--validation_epochs_end 1 \
--validation_begin_proportion 0.05 \
--validation_end_proportion 0.01 \
--validation_micro_batch 16 \
--deepspeed \
--data_loader_type dist \
--do_validation \
--use_early_stopping \
--early_stop_time 180 \
--early_stop_eval_loss 6 \
--seed 42 \
--fp16
基于时间的训练
通过定义 --total_training_time=24.0 (例如24小时),可以将预训练限制在基于时间的值内。
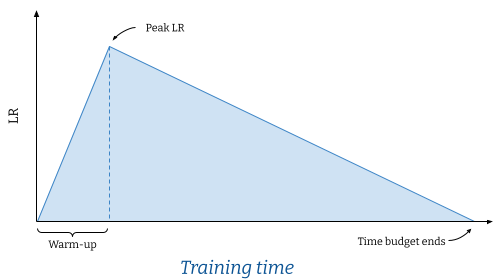
基于时间的学习率调度
学习率可以根据配置的总训练时间进行调度变化。参数 --total_training_time 控制分配给训练器运行的总时间,必须指定此参数才能使用基于时间的学习率调度。
检查点和微调检查点
可以启用两种类型的检查点:
- 训练检查点 - 保存模型权重、优化器状态和训练参数。由
--num_epochs_between_checkpoints定义。 - 微调检查点 - 保存模型权重和配置,以便稍后用于微调。由
--finetune_time_markers定义。
finetune_time_markers可以通过提供整体训练进度的时间标记列表来分配训练时间预算中的多个点。例如,--finetune_time_markers=0.5将在达到训练时间预算的50%时保存一个微调检查点。对于多个微调检查点,使用逗号而不带空格,如0.5,0.6,0.9。
验证调度
使用--do_validation在预训练时启用验证
使用--validation_epochs=<num>控制验证运行之间的epoch数
要控制开始和结束时的验证运行次数(运行次数多于validation_epochs),使用validation_begin_proportion和validation_end_proportion指定时间比例,并使用validation_epochs_begin和validation_epochs_end相应地控制自定义值。
混合精度训练
通过添加--fp16支持混合精度。使用--fp16_backend=ds来使用Deepspeed的混合精度后端,使用--fp16_backend=apex来使用apex(--fp16_opt控制优化级别)。
微调
使用run_glue.py对保存的检查点在GLUE任务上进行微调。
微调脚本与Huggingface提供的脚本相同,只是增加了我们的模型。
有关所有可能的预训练参数,请参见:python run_glue.py -h
MRPC微调示例:
python run_glue.py \
--model_name_or_path <模型路径> \
--task_name MRPC \
--max_seq_length 128 \
--output_dir /tmp/finetuning \
--overwrite_output_dir \
--do_train --do_eval \
--evaluation_strategy steps \
--per_device_train_batch_size 32 --gradient_accumulation_steps 1 \
--per_device_eval_batch_size 32 \
--learning_rate 5e-5 \
--weight_decay 0.01 \
--eval_steps 50 --evaluation_strategy steps \
--max_grad_norm 1.0 \
--num_train_epochs 5 \
--lr_scheduler_type polynomial \
--warmup_steps 50
生成预训练命令
我们提供了一个有用的脚本,通过使用python generate_training_commands.py来生成多个(或单个)预训练命令。
python generate_training_commands.py -h
--param_file PARAM_FILE 超参数和配置yaml
--job_name JOB_NAME 作业名称
--init_cmd INIT_CMD 初始化命令(deepspeed或直接python)
必须定义一个参数yaml,其中包含两个主要键:hyperparameters,其中参数值定义为可能值列表,以及default_parameters作为默认值。每个生成的命令将是hyperparameters部分中指定的各种参数的可能组合。
示例:
hyperparameters:
param1: [val1, val2]
param2: [val1, val2]
default_parameters:
param3: 0.0
将生成:
deepspeed run_pretraining.py --param1=val1 --param2=val1 --param3=0.0
deepspeed run_pretraining.py --param1=val1 --param2=val2 --param3=0.0
deepspeed run_pretraining.py --param1=val2 --param2=val1 --param3=0.0
deepspeed run_pretraining.py --param1=val2 --param2=val2 --param3=0.0
引用
如果你觉得这篇论文或这段代码有用,请引用这篇论文:
@inproceedings{izsak-etal-2021-train,
标题 = "如何在学术预算内训练BERT",
作者 = "Izsak, Peter 和
Berchansky, Moshe 和
Levy, Omer",
会议论文集 = "2021年自然语言处理实证方法会议论文集",
月份 = 11月,
年份 = "2021",
出版社 = "计算语言学协会",
网址 = "https://aclanthology.org/2021.emnlp-main.831",
}











