
 访问官网
访问官网 Github
Github 文档
文档
开放合同 (演示)
免费开源的文档分析平台 
| CI/CD |  |
| 元信息 |     |
它能做什么?
OpenContracts 是一个Apache-2 许可的企业文档分析工具。它提供以下几个关键功能:
- 管理文档 - 管理文档集合(
语料库) - 版面分析器 - 自动从PDF中提取版面特征
- 自动向量嵌入 - 为上传的PDF和提取的版面块生成
- 可插拔的微服务分析器架构 - 用于分析文档并自动注释
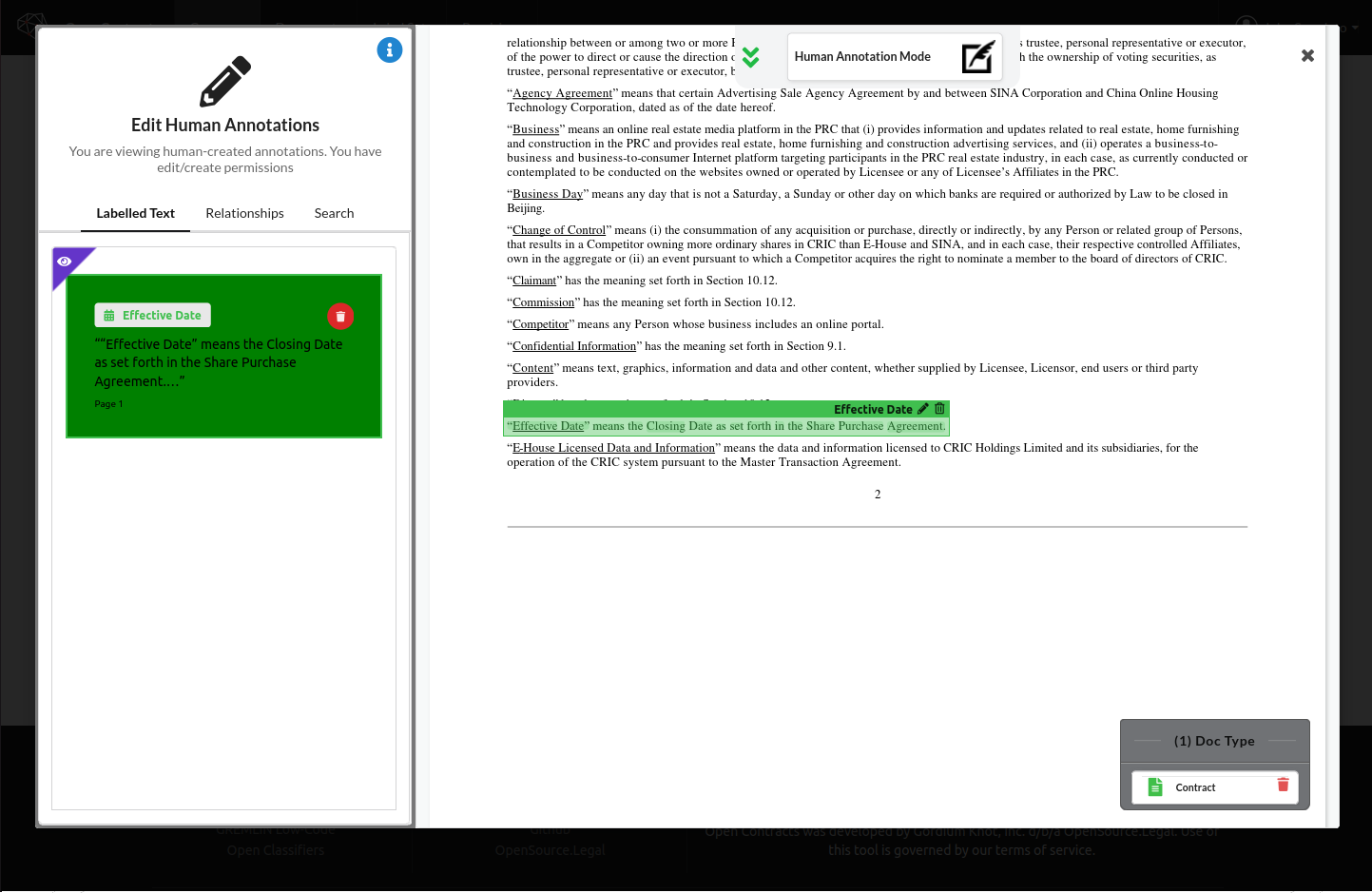
- 人工注释界面 - 用于手动注释文档,包括多页注释
- LlamaIndex 集成 - 使用我们的向量存储(由 pgvector 提供支持)和任何手动或自动注释的特征,让 LLM 智能回答问题
- 数据提取 - 使用复杂的 LLM 驱动的查询行为,在数百份文档中提出多个问题。我们的示例实现使用 LlamaIndex + Marvin
- 自定义数据提取 - 可以在前端使用自定义数据提取管道批量查询文档
关键文档
我们建议您通过我们的 Mkdocs 网站浏览我们的文档。您也可以在仓库中查看文档:
- 快速入门指南 - 如果您想快速上手,这是个不错的选择。如果您已经在运行 Docker,本地设置应该相当简单。
- 基本演练 - 查看演练以了解应用程序的基本使用,包括文档和注释管理。
- PDF 注释数据格式概述 - 您可能对我们如何在视觉上将文本映射到 PDF 以及我们使用的底层数据格式感兴趣。
- Django + Pgvector 驱动的混合向量数据库 - 我们使用了最新的开源工具在 postgres 中进行向量存储,使得在 API 驱动的应用程序中结合结构化元数据和向量嵌入变得几乎轻而易举。
- LlamaIndex 集成演练 - 我们为后端数据库和向量存储编写了一个包装器,使得将我们解析的注释、嵌入和文本加载到 LlamaIndex 中变得简单。更好的是,如果文档中有额外的注释,LLM 也可以访问这些注释。
- 编写自定义数据提取器 - 自定义数据提取任务(可以使用 LlamaIndex 或完全定制)会自动加载并显示在前端,让用户选择如何提问和从文档中提取数据。
架构和数据流概览
核心数据标准
除了提供一个分析合同的平台外,这里的核心思想是一个开放和标准化的架构,使数据极其便携。支持这一点的是一套描述 PDF 页面上文本和布局块的数据标准:

强大的 PDF 处理管道
我们有一个强大的 PDF 处理管道,它可以水平扩展,并为 PDF 输入一致地生成我们的标准化数据(我们正在努力添加更多格式的支持):
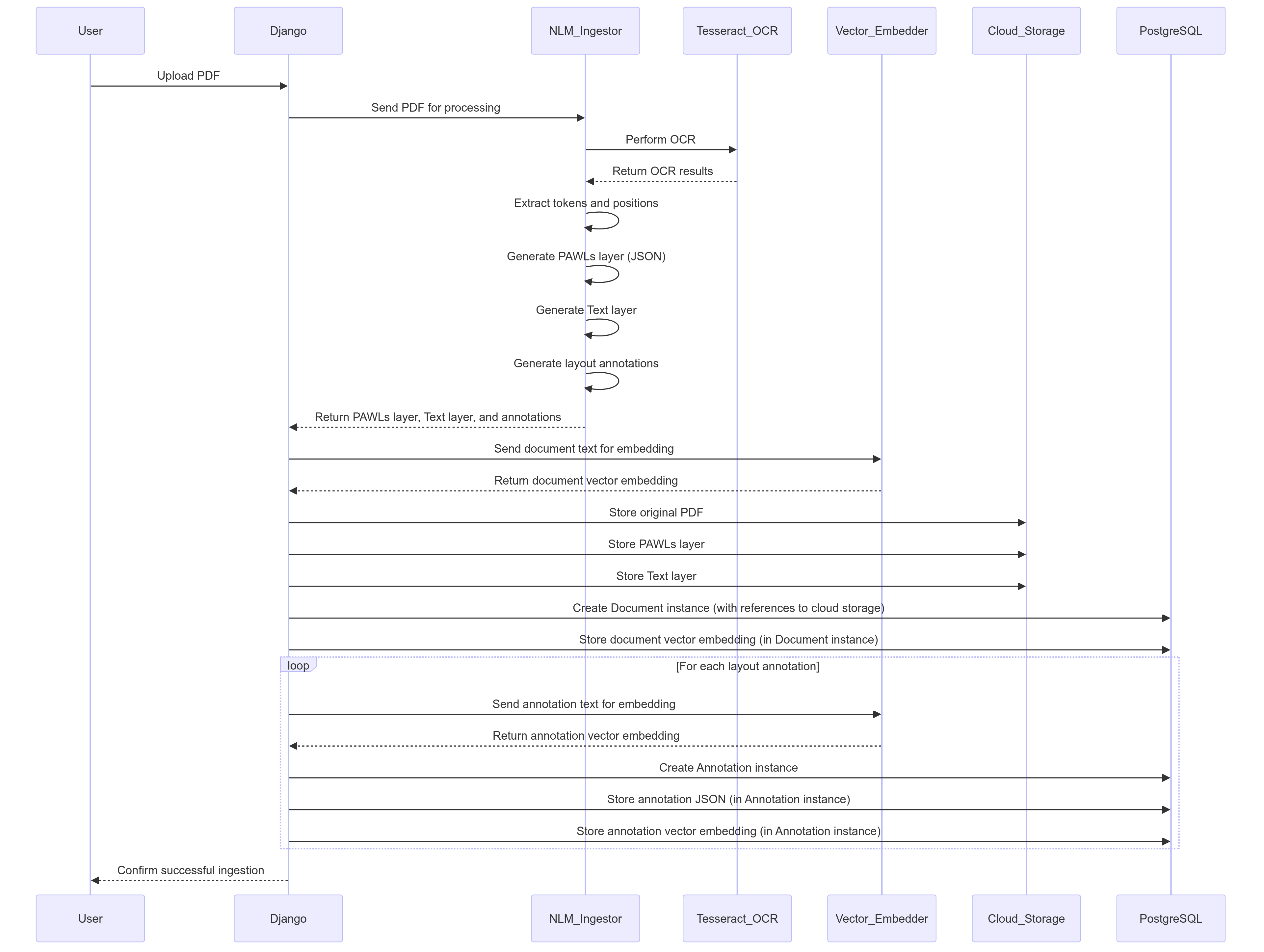
特别感谢 Nlmatics 和 nlm-ingestor 为版面解析和提取提供支持。
局限性
目前,它只能处理 PDF。未来,它将能够将其他文档类型转换为 PDF 以进行存储和标记。PDF 是一种优秀的格式,因为它引入了一种一致、可重复的格式,我们可以用它从头开始生成文本和 x-y 坐标层。
添加 OCR 和其他企业文档的摄取是一个优先事项。
致谢
特别感谢 AllenAI 的 PAWLS 项目 和 Nlmatics 的 nlm-ingestor。他们在应用程序的某些部分开创了许多功能和流程,我们正在使用他们的代码。











