
 访问官网
访问官网 Github
Github 论文
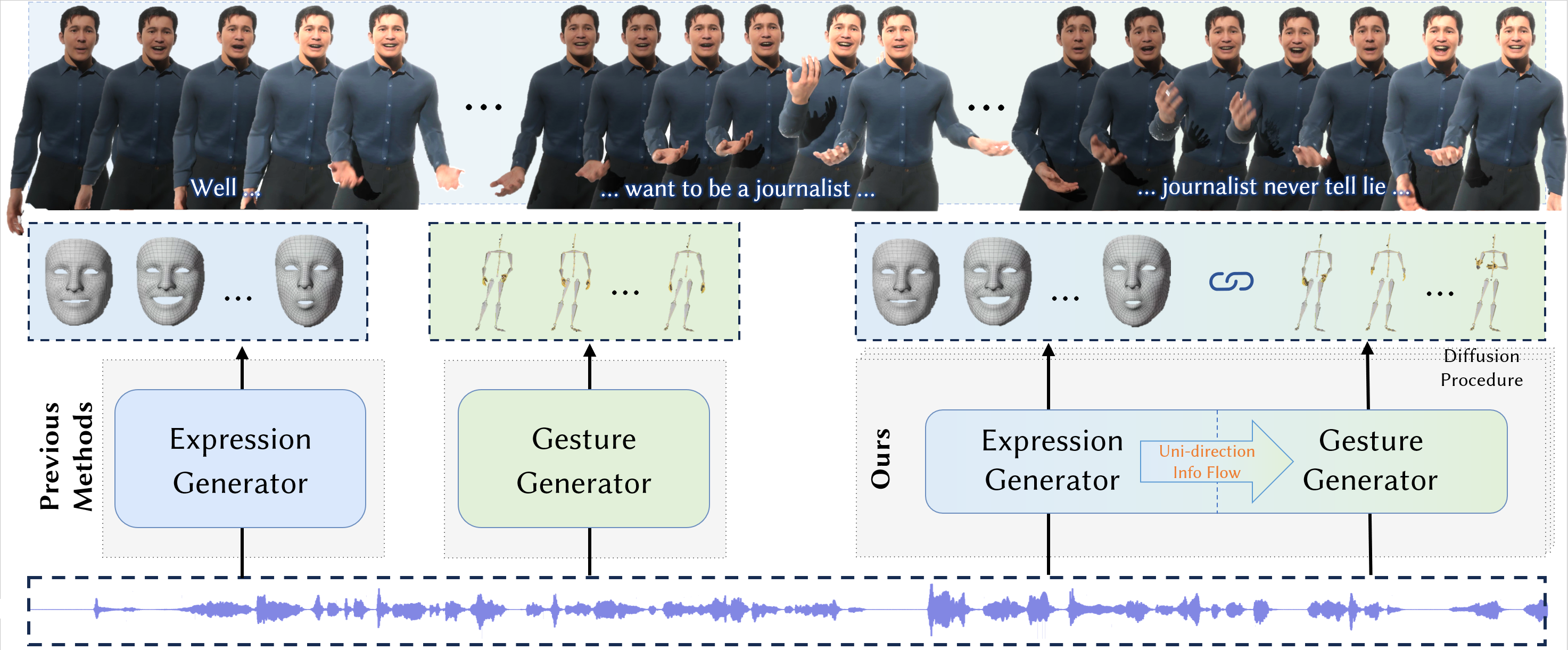
论文DiffSHEG:基于扩散的实时语音驱动整体3D表情和手势生成方法
(CVPR 2024 官方代码库)
陈俊铭†1,2,刘云飞2,王嘉楠2,曾爱玲2,李煜*2,陈启峰*1
1香港科技大学 2国际数字经济研究院(IDEA)
*通讯作者 †此工作在IDEA实习期间完成
项目主页 · 论文 · 视频
环境配置
我们在Ubuntu 18.04和20.04上进行了测试。
cd assets
- 选项1:使用conda安装
conda env create -f environment.yml
conda activate diffsheg
- 选项2:使用pip安装
conda create -n "diffsheg" python=3.9
conda activate diffsheg
pip install -r requirements.txt
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117
- 解压data.tar.gz以获取数据统计信息
tar zxvf data.tar.gz
mv data ../
检查点
自定义音频推理
首先在以下提到的bash文件中指定'--test_audio_path'参数为您的测试音频路径。请注意,音频应为.wav文件。
- 使用在BEAT数据集上训练的模型:
bash inference_custom_audio_beat.sh
- 使用在SHOW数据集上训练的模型:
bash inference_custom_audio_talkshow.sh
训练
在BEAT数据集上训练
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
OMP_NUM_THREADS=10 CUDA_VISIBLE_DEVICES=0,1,2,3,4 python -u runner.py \
--dataset_name beat \
--name beat_diffsheg \
--batch_size 2500 \
--num_epochs 1000 \
--save_every_e 20 \
--eval_every_e 40 \
--n_poses 34 \
--ddim \
--multiprocessing-distributed \
--dist-url 'tcp://127.0.0.1:6666'
在SHOW数据集上训练
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
OMP_NUM_THREADS=10 CUDA_VISIBLE_DEVICES=0,1,2,3,4 python -u runner.py \
--dataset_name talkshow \
--name talkshow_diffsheg \
--batch_size 950 \
--num_epochs 4000 \
--save_every_e 20 \
--eval_every_e 40 \
--n_poses 88 \
--classifier_free \
--multiprocessing-distributed \
--dist-url 'tcp://127.0.0.1:6667' \
--ddim \
--max_eval_samples 200
测试
在BEAT数据集上测试
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
OMP_NUM_THREADS=10 CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -u runner.py \
--dataset_name talkshow \
--name talkshow_GesExpr_unify_addHubert_encodeHubert_mdlpIncludeX_condRes_LN_ClsFree \
--PE pe_sinu \
--n_poses 88 \
--multiprocessing-distributed \
--dist-url 'tcp://127.0.0.1:8889' \
--classifier_free \
--cond_scale 1.25 \
--ckpt ckpt_e2599.tar \
--mode test_arbitrary_len \
--ddim \
--timestep_respacing ddim25 \
--overlap_len 10
在SHOW数据集上测试
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
OMP_NUM_THREADS=10 CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -u runner.py \
--dataset_name talkshow \
--name talkshow_GesExpr_unify_addHubert_encodeHubert_mdlpIncludeX_condRes_LN_ClsFree \
--PE pe_sinu \
--n_poses 88 \
--multiprocessing-distributed \
--dist-url 'tcp://127.0.0.1:8889' \
--classifier_free \
--cond_scale 1.25 \
--ckpt ckpt_e2599.tar \
--mode test_arbitrary_len \
--ddim \
--timestep_respacing ddim25 \
--overlap_len 10
可视化
在测试或自定义音频测试模式下运行后,手势和表情结果将保存在./results目录中。
BEAT
- 在本地计算机上使用最新版本的Blender打开
assets/beat_visualize.blend。 - 在Blender的脚本中指定音频、BVH(用于手势)、JSON(用于表情)和视频保存路径。
- (可选)点击窗口 --> 切换系统控制台以查看可视化进度。
- 在Blender中运行脚本。
SHOW
请参考TalkSHOW代码以可视化我们生成的动作。
致谢
我们的实现部分基于BEAT、TalkSHOW和MotionDiffuse。
引用
如果您使用我们的代码或发现此代码库有用,请考虑引用我们的论文:
@inproceedings{chen2024diffsheg,
title = {DiffSHEG: A Diffusion-Based Approach for Real-Time Speech-driven Holistic 3D Expression and Gesture Generation},
author = {Chen, Junming and Liu, Yunfei and Wang, Jianan and Zeng, Ailing and Li, Yu and Chen, Qifeng},
booktitle = {CVPR},
year = {2024}
}











