
 访问官网
访问官网 Github
Github 文档
文档

LangTest:交付安全有效的语言模型







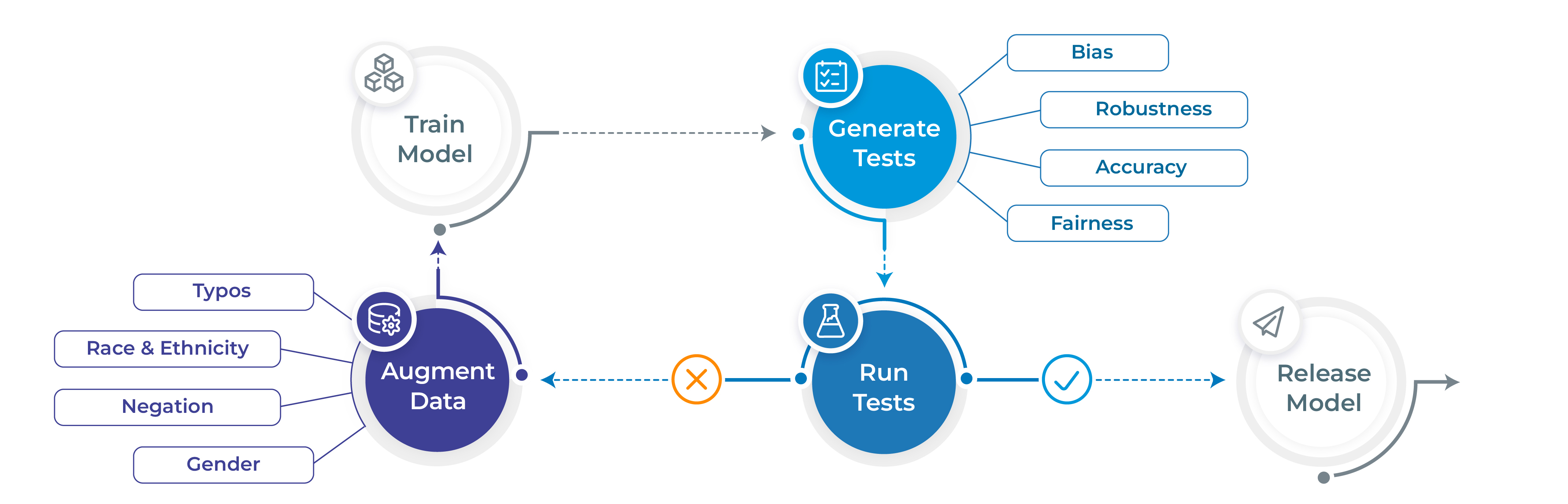
项目网站 • 主要特性 • 使用方法 • 基准数据集 • 社区支持 • 贡献 • 使命 • 许可证
项目网站
查看我们的官方网页获取用户文档和示例:langtest.org
主要特性
- 仅用1行代码即可生成并执行60多种不同类型的测试
- 测试模型质量的各个方面:鲁棒性、偏见、表示、公平性和准确性
- 根据测试结果自动增强训练数据(适用于特定模型)
- 支持流行的NLP框架,用于命名实体识别、翻译和文本分类:Spark NLP、Hugging Face和Transformers
- 支持测试大型语言模型(OpenAI、Cohere、AI21、Hugging Face推理API和Azure-OpenAI LLMs),用于问答、毒性检测、临床测试、法律支持、事实性、谄媚、摘要生成和其他流行测试
基准数据集
LangTest附带不同的数据集来测试您的模型,涵盖了广泛的用例和评估场景。您可以在这里探索所有可用的基准数据集,每个数据集都经过精心策划,以挑战和提升您的语言模型。无论您是专注于问答、文本摘要等,LangTest都能确保您拥有合适的数据来推动模型达到极限,并在各种语言任务中实现卓越性能。
使用方法
# 安装langtest
!pip install langtest[transformers]
# 导入并创建Harness对象
from langtest import Harness
h = Harness(task='ner', model={"model":'dslim/bert-base-NER', "hub":'huggingface'})
# 生成测试用例,运行它们并查看报告
h.generate().run().report()
注意 有关更多详细使用示例和文档,请访问langtest.org
负责任的AI博客
您可以查看以下LangTest文章:
| 博客 | 描述 |
|---|---|
| 自动测试大型语言模型生成的临床治疗方案中的人口统计偏见 | 帮助理解和测试大型语言模型生成的临床治疗方案中的人口统计偏见。 |
| LangTest:揭示并修复端到端自然语言处理流程中的偏见 | LangTest中的端到端语言流程使自然语言处理从业者能够以全面、数据驱动和迭代的方法解决语言模型中的偏见问题。 |
| 超越准确性:使用LangTest对命名实体识别模型进行鲁棒性测试 | 虽然准确性无疑至关重要,但鲁棒性测试将自然语言处理(NLP)模型评估提升到了一个新的水平,确保模型能够在各种真实世界条件下可靠一致地表现。 |
| 通过自动化数据增强提升您的自然语言处理模型性能 | 在本文中,我们讨论了如何通过自动化数据增强来提升自然语言处理模型的性能,以及我们如何使用LangTest来实现这一目标。 |
| 缓解人工智能中的性别-职业刻板印象:通过Langtest库使用Wino偏见测试评估模型 | 在本文中,我们讨论了如何使用LangTest测试"Wino偏见"。它特别指测试由性别-职业刻板印象引起的偏见。 |
| 自动化负责任的人工智能:整合Hugging Face和LangTest以构建更强大的模型 | 在本文中,我们探讨了Hugging Face(您获取最先进NLP模型和数据集的首选来源)与LangTest(您NLP流程的秘密测试和优化武器)之间的整合。 |
| 检测和评估谄媚偏见:对大型语言模型和人工智能解决方案的分析 | 在这篇博文中,我们讨论了人工智能行为中普遍存在的谄媚问题及其在人工智能世界中带来的挑战。我们探讨了语言模型有时如何优先考虑一致性而非真实性,从而阻碍有意义和无偏见的对话。此外,我们揭示了解决这一问题的潜在革命性方案——合成数据,它有望彻底改变人工智能伙伴参与讨论的方式,使它们在各种真实世界条件下更加可靠和准确。 |
| 揭示语言模型在否定和毒性评估中的敏感性 | 在这篇博文中,我们深入探讨了语言模型敏感性,研究模型如何处理语言中的否定和毒性。通过这些测试,我们深入了解了模型的适应性和响应能力,强调了NLP模型持续改进的必要性。 |
| 揭示语言模型中的偏见:性别、种族、残疾和社会经济视角 | 在这篇博文中,我们探讨了语言模型中的偏见,聚焦于性别、种族、残疾和社会经济因素。我们使用CrowS-Pairs数据集评估这种偏见,该数据集旨在衡量刻板印象偏见。为了解决这些偏见,我们讨论了像LangTest这样的工具在促进NLP系统公平性方面的重要性。 |
| 揭示人工智能内部的偏见:性别、种族、宗教和经济如何塑造自然语言处理及其他领域 | 在这篇博文中,我们探讨了人工智能偏见,讨论性别、种族、宗教和经济如何塑造NLP系统。我们讨论了减少偏见和促进人工智能系统公平性的策略。 |
| 使用Wino偏见测试评估大型语言模型中的性别-职业刻板印象 | 在这篇博文中,我们深入探讨了在大型语言模型上测试WinoBias数据集,研究语言模型如何处理性别和职业角色、评估指标以及更广泛的影响。让我们探索使用LangTest在WinoBias数据集上评估语言模型,并直面解决人工智能偏见的挑战。 |
| 简化机器学习工作流程:整合MLFlow跟踪与LangTest以增强模型评估 | 在这篇博文中,我们深入探讨了对透明、系统化和全面跟踪模型的日益增长的需求。介绍MLFlow和LangTest:这两个工具结合使用,为机器学习开发创造了革命性的方法。 |
| 测试大型语言模型的问答能力 | 在这篇博文中,我们深入探讨了使用LangTest库增强问答评估能力。探索LangTest提供的不同评估方法,以解决评估问答(QA)任务的复杂性。 |
| 使用LangTest评估刻板印象偏见 | 在这篇博文中,我们聚焦于使用StereoSet数据集来评估与性别、职业和种族相关的偏见。 |
| 测试基于LSTM的情感分析模型的稳健性 | 通过LangTest Insights探索自定义模型的稳健性。 |
| LangTest Insights:深入探究LLM在OpenBookQA上的稳健性 | 利用LangTest Insights探索语言模型(LLMs)在OpenBookQA数据集上的稳健性。 |
| LangTest:提升Transformers语言模型稳健性的秘密武器 | 通过LangTest Insights探索Transformers语言模型的稳健性。 |
| 掌握模型评估:介绍LangTest中的全面排名和排行榜系统 | John Snow Labs的LangTest提供的模型排名和排行榜系统为评估人工智能模型提供了系统化方法,包括全面排名、历史比较和特定数据集的洞察,使研究人员和数据科学家能够就模型性能做出数据驱动的决策。 |
| 使用Prometheus-Eval和Langtest评估长篇回复 | Prometheus-Eval和LangTest联手提供开源、可靠且经济高效的长篇回复评估解决方案,结合了Prometheus的GPT-4级性能和LangTest强大的测试框架,提供详细、可解释的反馈和高准确度的评估。 |
| 确保医疗领域LLMs的精确性:药品名称互换的挑战 | 准确识别药品名称对患者安全至关重要。使用LangTest的drug_generic_to_brand转换测试对GPT-4进行测试,发现当品牌名称被成分替代时,预测药品名称可能出现错误,突显了持续完善和严格测试的必要性,以确保医疗LLM的准确性和可靠性。 |
注意 要查看所有博客,请前往博客页面
社区支持
使命
尽管人们经常谈论需要训练安全、稳健和公平的AI模型,但很少有工具可供数据科学家用来实现这些目标。因此,生产系统中NLP模型的前沿状况令人遗憾。
我们在此提出一个早期的开源社区项目,旨在填补这一空白,并希望您能加入我们的使命。我们的目标是在先前研究的基础上进行构建,如Ribeiro等人(2020)、Song等人(2020)、Parrish等人(2021)、van Aken等人(2021)等多项研究。
John Snow Labs为该项目分配了一个完整的开发团队,并承诺在未来几年内持续改进该库,就像我们对其他开源库所做的那样。您可以期待频繁的发布,新的测试类型、任务、语言和平台将定期添加。我们期待与您合作,使安全、可靠和负责任的NLP成为日常现实。
注意 有关使用和文档,请前往langtest.org
为LangTest做出贡献
我们欢迎各种形式的贡献:
详细的贡献概述可以在**贡献指南**中找到。
如果您想开始使用LangTest代码库,请转到GitHub的"issues"标签,开始浏览有趣的问题。那里列出了一些您可以开始的问题。或者,通过使用LangTest,您可能有自己的想法,或者在文档中发现某些可以改进的地方......您可以采取行动!
如有疑问,请随时在问答讨论中提问。
作为本项目的贡献者和维护者,您应遵守LangTest的行为准则。更多信息可以在以下位置找到:贡献者行为准则
引用
我们已发表了一篇论文,您可以引用LangTest库:
@article{nazir2024langtest,
title={LangTest: A comprehensive evaluation library for custom LLM and NLP models},
author={Arshaan Nazir, Thadaka Kalyan Chakravarthy, David Amore Cecchini, Rakshit Khajuria, Prikshit Sharma, Ali Tarik Mirik, Veysel Kocaman and David Talby},
journal={Software Impacts},
pages={100619},
year={2024},
publisher={Elsevier}
}
贡献者
我们要感谢这个开源社区项目的所有贡献者。
许可证
LangTest根据Apache许可证2.0发布,该许可证保证商业使用、修改、分发、专利使用、私人使用,并对商标使用、责任和保证设置限制。











