
 Github
Github 文档
文档 论文
论文检查清单
本仓库包含了测试自然语言处理模型的代码,如下论文所述:
超越准确率:使用检查清单对NLP模型进行行为测试
Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, Sameer Singh 计算语言学协会(ACL), 2020
引用的BibTeX:
@inproceedings{checklist:acl20,
author = {Marco Tulio Ribeiro and Tongshuang Wu and Carlos Guestrin and Sameer Singh},
title = {超越准确率:使用检查清单对NLP模型进行行为测试},
booktitle = {计算语言学协会(ACL)},
year = {2020}
}
目录
安装
从pypi安装:
pip install checklist
jupyter nbextension install --py --sys-prefix checklist.viewer
jupyter nbextension enable --py --sys-prefix checklist.viewer
注意:使用--sys-prefix安装到Python的sys.prefix,这在虚拟环境(如conda或virtualenv)中很有用。如果不在这些环境中,请改用--user安装到用户的主目录下的Jupyter目录。
从源代码安装:
git clone git@github.com:marcotcr/checklist.git
cd checklist
pip install -e .
无论哪种方式,如果你想使用掩码语言模型建议,都需要安装pytorch或tensorflow:
pip install torch
对于大多数教程,你还需要下载spacy模型:
python -m spacy download en_core_web_sm
教程
请注意,可视化是通过ipywidgets实现的,在colab或JupyterLab上无法工作(请使用jupyter notebook)。其他所有内容都应该可以在这些平台上运行。
论文中的测试
笔记本:我们如何创建论文中的测试
复现论文测试,或使用新模型运行测试
对于所有这些,你需要在克隆主仓库文件夹后解压发布数据:
tar xvzf release_data.tar.gz
情感分析
加载测试套件:
import checklist
from checklist.test_suite import TestSuite
suite_path = 'release_data/sentiment/sentiment_suite.pkl'
suite = TestSuite.from_file(suite_path)
使用预计算的bert预测运行测试(将pred_path中的bert替换为amazon、google、microsoft或roberta以测试其他模型):
pred_path = 'release_data/sentiment/predictions/bert'
suite.run_from_file(pred_path, overwrite=True)
suite.summary() # 或 suite.visual_summary_table()
要测试你自己的模型,请获取release_data/sentiment/tests_n500中文本的预测结果,并将它们保存在一个文件中,每行包含4个数字:预测(0表示负面,1表示中性,2表示正面)以及(负面、中性、正面)的预测概率。
然后,用这个文件更新pred_path并运行上面的代码行。
QQP
import checklist
from checklist.test_suite import TestSuite
suite_path = 'release_data/qqp/qqp_suite.pkl'
suite = TestSuite.from_file(suite_path)
使用预计算的bert预测运行测试(如果需要,将pred_path中的bert替换为roberta):
pred_path = 'release_data/qqp/predictions/bert'
suite.run_from_file(pred_path, overwrite=True, file_format='binary_conf')
suite.visual_summary_table()
要测试你自己的模型,请获取release_data/qqp/tests_n500(格式:tsv)中句对的预测结果,并将它们输出到一个文件中,每行包含一个数字:句对是重复的概率。
SQuAD
import checklist
from checklist.test_suite import TestSuite
suite_path = 'release_data/squad/squad_suite.pkl'
suite = TestSuite.from_file(suite_path)
使用预计算的bert预测运行测试:
pred_path = 'release_data/squad/predictions/bert'
suite.run_from_file(pred_path, overwrite=True, file_format='pred_only')
suite.visual_summary_table()
要测试你自己的模型,请获取release_data/squad/squad.jsonl(格式:jsonl)或release_data/squad/squad.json(格式:json,类似SQuAD开发集)中句对的预测结果,并将它们输出到一个文件中,每行包含一个字符串:预测的跨度。
测试huggingface transformer管道
请参阅此笔记本。
代码片段
模板
有关更多详细信息,请参阅1. 生成数据。
import checklist
from checklist.editor import Editor
import numpy as np
editor = Editor()
ret = editor.template('{first_name}是来自{country}的{a:profession}。',
profession=['律师', '医生', '会计师'])
np.random.choice(ret.data, 3)
['玛丽是来自阿富汗的医生。', '乔丹是来自印度尼西亚的会计师。', '凯拉是来自塞拉利昂的律师。']
RoBERTa建议
有关更多详细信息,请参阅1. 生成数据。 在模板中:
ret = editor.template('这是{a:adj}{mask}。',
adj=['好的', '坏的', '很棒的', '糟糕的'])
ret.data[:3]
['这是好的主意。', '这是好的迹象。', '这是好的事情。']
多个掩码:
ret = editor.template('这是{a:adj}{mask}{mask}。',
adj=['好的', '坏的', '很棒的', '糟糕的'])
ret.data[:3]
['这是好的历史教训。', '这是好的国际象棋步骤。', '这是好的新闻故事。']
获取建议而不是填写模板:
editor.suggest('这是{a:adj}{mask}。',
adj=['好的', '坏的', '很棒的', '糟糕的'])[:5]
['主意', '迹象', '事情', '例子', '开始']
获取替换建议(仅允许单个文本,不允许使用模板):
editor.suggest_replace('这是一部好电影。', '好')[:5]
['很棒', '恐怖', '糟糕', '可怕', 'cult']
通过Jupyter可视化获取建议:
editor.visual_suggest('这是{a:mask}电影。')
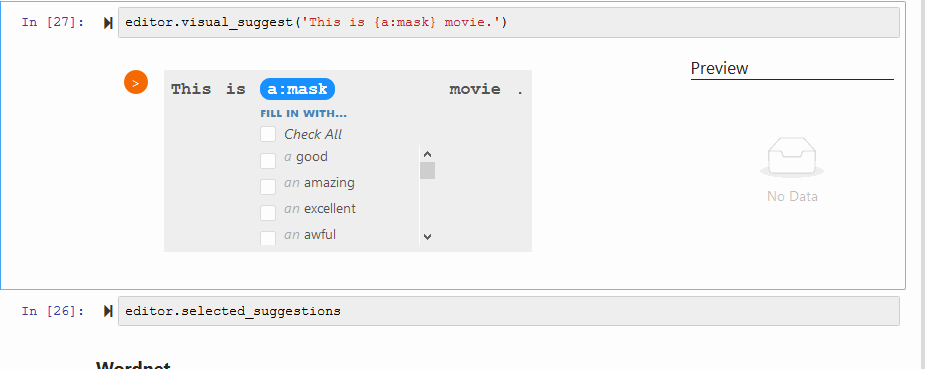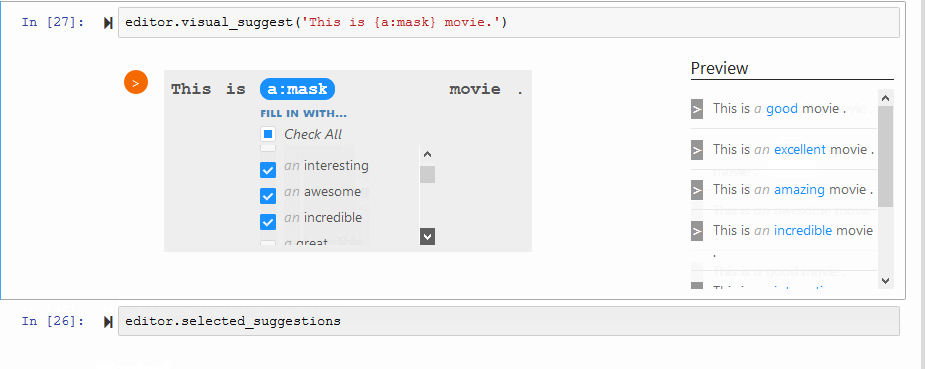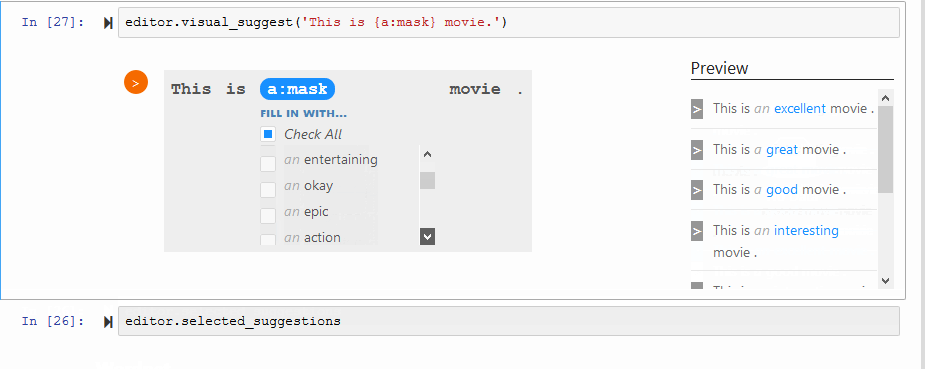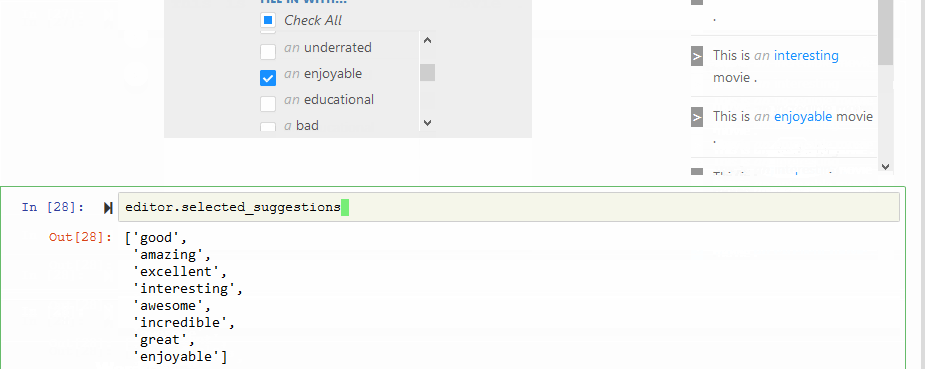
多语言建议
只需使用language参数初始化编辑器(应该适用于语言名称和ISO 639-1代码):
import checklist
from checklist.editor import Editor
import numpy as np
# 葡萄牙语
editor = Editor(language='portuguese')
ret = editor.template('O João é um {mask}.',)
ret.data[:3]
['O João é um português.', 'O João é um poeta.', 'O João é um brasileiro.']
# 中文
editor = Editor(language='chinese')
ret = editor.template('西游记的故事很{mask}。',)
ret.data[:3]
['西游记的故事很精彩。', '西游记的故事很真实。', '西游记的故事很经典。']
我们使用FlauBERT处理法语,German BERT处理德语,以及XLM-RoBERTa处理其他所有语言(点击链接查看支持的语言列表)。我们无法保证其他语言建议的质量,但对于我们会说的语言(尽管不如英语)似乎效果还不错。
词典(部分多语言支持)
editor.lexicons是一个可以在模板中使用的字典。例如:
import checklist
from checklist.editor import Editor
import numpy as np
# 默认:英语
editor = Editor()
ret = editor.template('{male1}去看望{male2},他在{city}。', remove_duplicates=True)
list(np.random.choice(ret.data, 3))
['丹去看望休,他在里弗赛德。', '斯蒂芬去看望埃里克,他在奥马哈。', '帕特里克去看望尼克,他在堪萨斯城。']
人名和地点(国家、城市)名称是多语言的,取决于editor的语言。我们从维基数据获取数据,所以存在偏向维基百科上的名称的倾向。
editor = Editor(language='german')
ret = editor.template('{male1}去看望{male2},他在{city}。', remove_duplicates=True)
list(np.random.choice(ret.data, 3))
['罗尔夫去看望克劳斯,他在莱比锡。', '理查德去看望约尔格,他在马尔。', '格尔德去看望弗里茨,他在什未林。']
可用词典列表:
editor.lexicons.keys()
dict_keys(['male', 'female', 'first_name', 'first_pronoun', 'last_name', 'country', 'nationality', 'city', 'religion', 'religion_adj', 'sexual_adj', 'country_city', 'male_from', 'female_from', 'last_from'])
其中一些不能直接在模板中使用,因为它们本身就是字典。例如,male_from、female_from、last_from和country_city是从国家到男性名字、女性名字、姓氏和人口最多的城市的字典。
你可以调用editor.lexicons.male_from.keys()来获取国家名称列表。使用示例:
import numpy as np
countries = ['法国', '德国', '巴西']
for country in countries:
ts = editor.template('{male} {last}来自{city}',
male=editor.lexicons.male_from[country],
last=editor.lexicons.last_from[country],
city=editor.lexicons.country_city[country],
)
print('国家:%s' % country)
print('\n'.join(np.random.choice(ts.data, 3)))
print()
国家:法国 让-雅克·布伦来自阿维尼翁 布鲁诺·德尚来自维特里-叙尔塞纳 欧内斯特·皮卡尔来自尚贝里
国家:德国 赖纳·布劳恩来自什未林 马库斯·勃兰特来自格拉 莱因哈德·布施来自埃尔兰根
国家:巴西 吉尔伯托·马丁斯来自阿纳波利斯 阿尔弗雷多·吉马良斯来自因达亚图巴 Jorge Barreto来自福塔莱萨
扰动INV和DIR的数据
有关更多详细信息,请参阅2.扰动数据。 自定义扰动函数:
import re
import checklist
from checklist.perturb import Perturb
def replace_john_with_others(x, *args, **kwargs):
# 如果不存在John则返回空,否则返回将John替换为Luke和Mark的字符串列表
if not re.search(r'\bJohn\b', x):
return None
return [re.sub(r'\bJohn\b', n, x) for n in ['Luke', 'Mark']]
dataset = ['John is a man', 'Mary is a woman', 'John is an apostle']
ret = Perturb.perturb(dataset, replace_john_with_others)
ret.data
[['John is a man', 'Luke is a man', 'Mark is a man'],
['John is an apostle', 'Luke is an apostle', 'Mark is an apostle']]
通用扰动(更多详情见教程):
import spacy
nlp = spacy.load('en_core_web_sm')
pdataset = list(nlp.pipe(dataset))
ret = Perturb.perturb(pdataset, Perturb.change_names, n=2)
ret.data
[['John is a man', 'Ian is a man', 'Robert is a man'],
['Mary is a woman', 'Katherine is a woman', 'Alexandra is a woman'],
['John is an apostle', 'Paul is an apostle', 'Gabriel is an apostle']]
ret = Perturb.perturb(pdataset, Perturb.add_negation)
ret.data
[['John is a man', 'John is not a man'],
['Mary is a woman', 'Mary is not a woman'],
['John is an apostle', 'John is not an apostle']]
创建和运行测试
有关更多详细信息,请参阅3. 测试类型、期望函数、运行测试。
MFT:
import checklist
from checklist.editor import Editor
from checklist.perturb import Perturb
from checklist.test_types import MFT, INV, DIR
editor = Editor()
t = editor.template('This is {a:adj} {mask}.',
adj=['good', 'great', 'excellent', 'awesome'])
test1 = MFT(t.data, labels=1, name='Simple positives',
capability='Vocabulary', description='')
INV:
dataset = ['This was a very nice movie directed by John Smith.',
'Mary Keen was brilliant.',
'I hated everything about this.',
'This movie was very bad.',
'I really liked this movie.',
'just bad.',
'amazing.',
]
t = Perturb.perturb(dataset, Perturb.add_typos)
test2 = INV(**t)
DIR:
from checklist.expect import Expect
def add_negative(x):
phrases = ['Anyway, I thought it was bad.', 'Having said this, I hated it', 'The director should be fired.']
return ['%s %s' % (x, p) for p in phrases]
t = Perturb.perturb(dataset, add_negative)
monotonic_decreasing = Expect.monotonic(label=1, increasing=False, tolerance=0.1)
test3 = DIR(**t, expect=monotonic_decreasing)
直接运行测试:
from checklist.pred_wrapper import PredictorWrapper
# wrapped_pp返回一个元组,包含(预测结果,softmax置信度)
wrapped_pp = PredictorWrapper.wrap_softmax(model.predict_proba)
test.run(wrapped_pp)
从文件运行:
# 每行一个示例
test.to_raw_file('/tmp/raw_file.txt')
# 每行包含预测概率(softmax)
test.run_from_file('/tmp/softmax_preds.txt', file_format='softmax', overwrite=True)
结果摘要:
test.summary(n=1)
测试用例: 400
失败(比率): 200 (50.0%)失败示例:
0.2 This is a good idea
可视化摘要:
test.visual_summary()
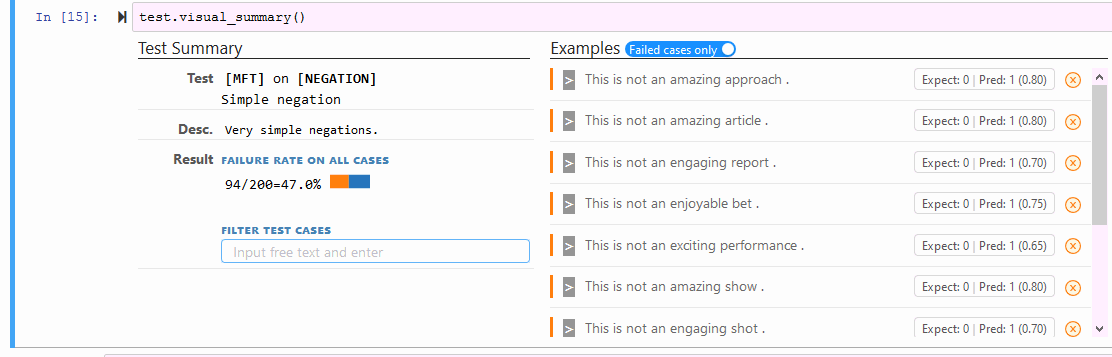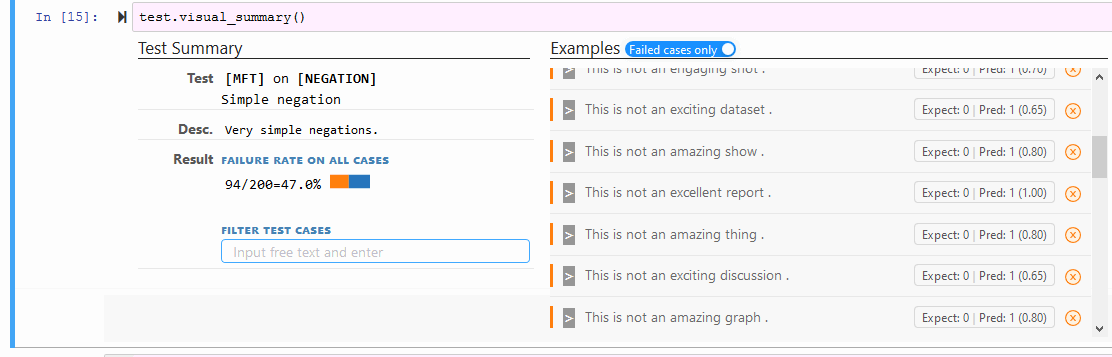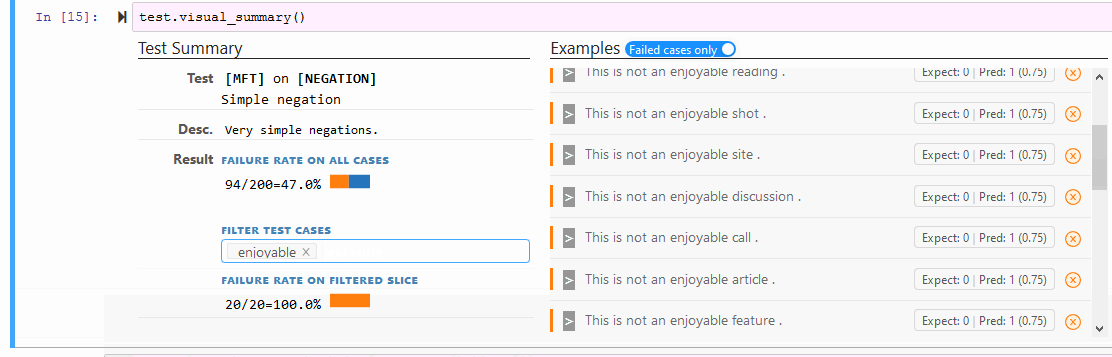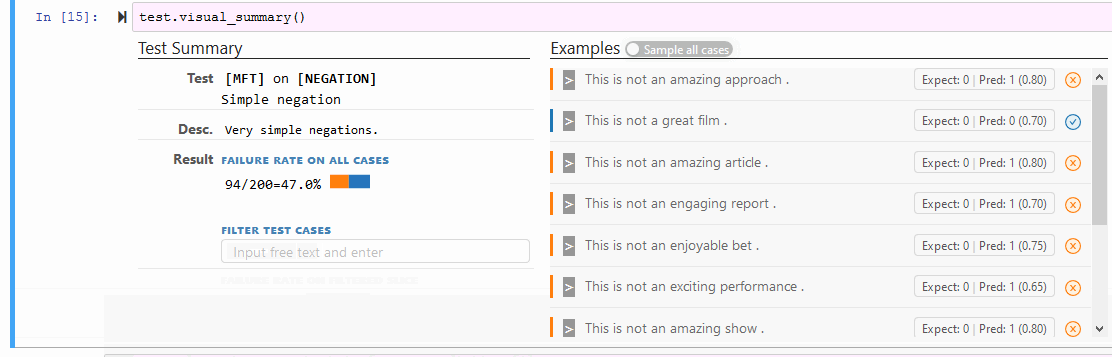
保存和加载单个测试:
# 保存
test.save(path)
# 加载
test = MFT.from_file(path)
自定义期望函数
有关更多详细信息,请参阅3. 测试类型、期望函数、运行测试。
如果您正在编写自定义期望函数,它必须为每个示例返回一个浮点数或布尔值,使得:
> 0(或True)表示通过,<= 0或False表示失败,并且(可选)失败的程度由与0的距离表示,例如-10比-1更糟糕None表示测试不适用,不应计入统计
单个示例的期望:
def high_confidence(x, pred, conf, label=None, meta=None):
return conf.max() > 0.95
expect_fn = Expect.single(high_confidence)
(orig, new)示例对的期望(用于INV和DIR):
def changed_pred(orig_pred, pred, orig_conf, conf, labels=None, meta=None):
return pred != orig_pred
expect_fn = Expect.pairwise(changed_pred)
还有Expect.testcase和Expect.test等许多其他选项。
查看expect.py了解更多详情。
测试套件
有关更多详细信息,请参阅4. CheckList流程。
添加测试:
from checklist.test_suite import TestSuite
# 假设测试已存在:
suite.add(test)
运行套件与运行单个测试相同,可以直接运行或通过文件运行:
from checklist.pred_wrapper import PredictorWrapper
# wrapped_pp返回一个元组,包含(预测结果,softmax置信度)
wrapped_pp = PredictorWrapper.wrap_softmax(model.predict_proba)
suite.run(wrapped_pp)
# 或suite.run_from_file,请参见上面的示例
要可视化结果,您可以调用suite.summary()(与test.summary相同),或者suite.visual_summary_table()。以下是后者在BERT情感分析上的效果:
suite.visual_summary_table()

最后,保存、加载和分享测试套件非常简单:
# 保存
suite.save(path)
# 加载
suite = TestSuite.from_file(path)











