
 访问官网
访问官网 Github
Github 文档
文档深度学习算法教程



最近我一直在学习机器学习和算法,并不断总结和记录笔记,记录下自己学习AI与算法的历程。 机器学习(Machine Learning, ML)是一门多学科交叉领域,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多个学科。它专门研究计算机如何模拟或实现人类的学习行为,以获取新知识或技能,重新组织已有的知识结构,从而不断提高自身的性能。
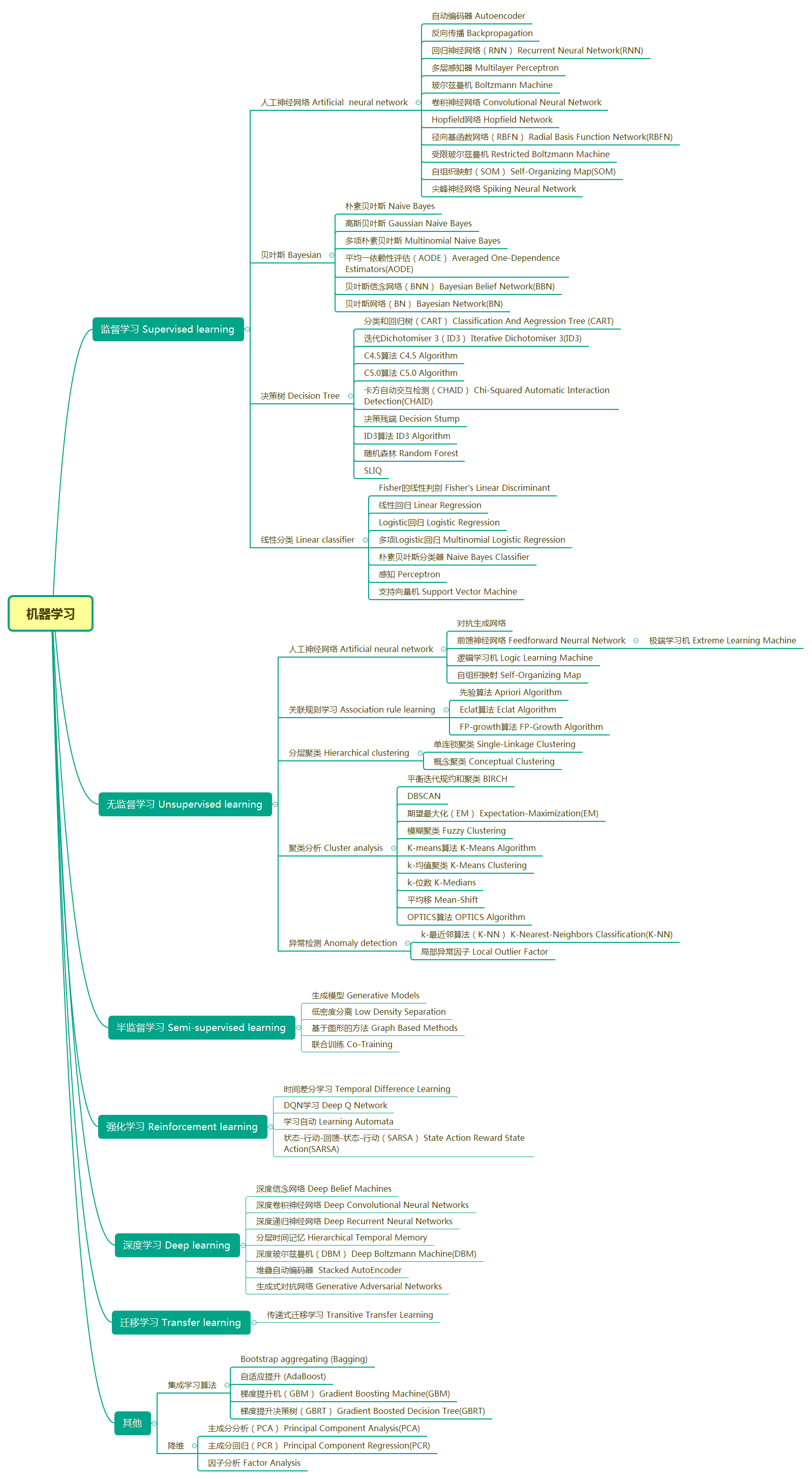
- 机器学习是计算机科学的一个分支,在人工智能领域,机器学习逐渐发展成为模式识别和计算科学理论的研究方向。
- 机器学习:多学科交叉领域,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多个学科。
- 机器学习的应用:语音识别、自动驾驶、语言翻译、计算机视觉、推荐系统、无人机、垃圾邮件识别、人脸识别、电商推荐系统。
- 机器学习的基本概念:训练集、测试集、特征值、监督学习、非监督学习、分类、回归
目前国内在AI感知层面的应用已经百花齐放,主要集中在无人驾驶、智能音箱、嵌入式等领域。但在认知层面还比较缺乏,因此新入行的AI应用团队可以着重关注认知层。如前所述,认知层最重要的是算法,因此需要阅读Nature上领先的算法公司DeepMind的几篇重要论文,如下:
- 2016.01.用深度神经网络和树搜索掌握围棋游戏
- 2016.10.使用具有动态外部存储的神经网络进行混合计算
- 2017.10.在没有人类知识的情况下掌握围棋游戏
机器学习步骤框架
- 将数据分为训练集和测试集
- 使用训练集及其特征向量来训练算法
- 将学习到的算法应用于测试集以评估算法(可能涉及参数调整(parameter tuning),使用验证集(validation set))
机器学习
-
机器学习:机器学习是计算机科学的一个分支,在人工智能领域,机器学习逐渐发展成为模式识别和计算科学理论的研究方向。通俗地说,机器学习是一种能够赋予机器学习能力的方法,可以让它完成直接编程无法完成的功能。从实践意义上来说,机器学习是一种通过利用数据训练模型,然后使用模型进行预测的方法。
-
机器学习的应用:机器学习已广泛应用于数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、信用卡欺诈检测、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人等领域。现在让我们开始学习机器学习吧!
深度学习
-
深度学习:深度学习是基于机器学习延伸出来的一个新领域,起源于以人脑结构为启发的神经网络算法,随着模型结构深度的增加而发展,并伴随大数据和计算能力的提高而产生一系列新算法。
-
深度学习的方向:被应用在图像处理与计算机视觉、自然语言处理以及语音识别等领域。
机器学习算法概览

自2016年以来,机器学习取得了新的突破和发展。然而,有效的机器学习仍然具有挑战性,因为机器学习本身是一个跨学科领域,没有科学的方法和一定的积累很难入门。
2017年10月19日,Nature杂志发表了新一代AlphaGo版本AlphaGo Zero的技术论文。该论文指出了一种仅基于强化学习的算法,AlphaGo Zero不使用人类的数据、指导或规则以外的领域知识,成为了自己的老师。DeepMind代表了目前人工智能领域最强的技术,其核心可以用两个字概括:算法。
许多人都想成为AI开发者,不仅是因为AI开发的薪资高,更主要是因为AI这几年的快速发展。但由于AI本身的门槛较高,很多人可能会犹豫不决。因此,我想将自己学习AI的过程写成本书,供大家参考和学习!
- BP神经网络
- RBF算法
- SOM神经网络
- ART神经网络
- 贝叶斯网络
- 粗糙集
- 孤立点分析
- CART
- EM
- FP—tree
- GSP序列
- 协同过滤
- BIRCH
- Prefixspan
- PageRank
- AdaBoost
- CBA
- KNN
- Hopfield神经网络
- 决策树
- 聚类分析
- 关联规则
- 支持向量机(SVM)
我将持续更新和整理后续的算法和算法模型,不断补充新的算法章节。希望这能对刚入门学习AI开发和算法的开发者有所帮助!
算法模型
- 回归算法
- 基于实例的学习算法
- 正则化算法
- 决策树算法
- 贝叶斯算法
- 基于核的算法
- 聚类算法(Cluster analysis)
- 关联规则学习(Association Rule Learning)
- 人工神经网络(Artificial Neural Network)
- 反向传播
- 循环神经网络
- 多层感知器
- 玻尔兹曼机
- 卷积神经网络
- 霍普菲尔德网络
- 径向基函数网络
- 受限玻尔兹曼机
- 自组织映射
- 脉冲神经网络
- 深度学习
- 降维算法
- 集成学习
- 其他算法
大语言模型LLM
随着ChatGPT的诞生,大型语言模型(LLM, Large Language Model)进入了我们的视野。GPT 3.0不仅仅是一项具体技术,更体现了LLM未来发展的理念。
从那时起,差距越拉越大,ChatGPT只是这种发展理念差异的自然结果。
那么什么是大语言模型呢?让我们深入探索和学习一下。
大型语言模型(LLM)是基于海量数据预训练的超大规模深度学习模型。其底层是一组由具有自注意力机制的编码器和解码器组成的神经网络转换器。编码器和解码器从一系列文本中提取含义,并理解其中词语和短语之间的关系。
转换器LLM能够进行无监督训练,更准确地说,转换器可以执行自主学习。通过这个过程,转换器可以学会理解基本的语法、语言和知识。
与早期按顺序处理输入的循环神经网络(RNN)不同,转换器并行处理整个序列。这使得数据科学家能够使用GPU训练基于转换器的LLM,从而大幅缩短训练时间。
借助转换器神经网络架构,可以构建非常大规模的模型,通常具有数千亿个参数。这种大规模模型可以摄取通常来自互联网的海量数据,也可以从包含超过500亿个网页的Common Crawl和拥有约5700万个页面的Wikipedia等来源获取数据。
机器学习的基础
- 机器学习所需的理论基础:数学、线性代数、数理统计、概率论、高等数学、凸优化理论、形式逻辑等
参考书籍
- [同济线性代数教材]
- [同济高等数学第六版上下册]
- [概率论与数理统计同济大学]
- [凸优化理论]
- [机器学习-周志华]
- [面向机器智能的TensorFlow实践]
- [机器学习]
- [数学之美]
- [深度学习]
- [神经网络和深度学习]
- [梯度下降]
- [无监督神经元]
- [Tensorflow实践]
- [人工智能]
- [Tensorflow新手入门]
机器学习
如果您觉得这篇文章不错,可以给我点赞支持,:star:!如果有问题可以加我的微信,也可以加入我们的交流群一起讨论技术!
许可证
本软件按MIT许可证的条款免费分发











