
 Github
Github 文档
文档TensorOp矩阵乘法教程
这是一个CUDA矩阵乘法实现的示例仓库。该仓库旨在为CUDA初学者提供高性能内核设计的一些见解。目前,我只在
examples/matmul/this中提供了一些实现示例。 欢迎贡献更多的内核和其他矩阵乘法实现。
关于
这里有一个详细的解释,介绍了examples/matmul/this中不同版本的矩阵乘法内核。
内容
-
examples:-
matmul: 矩阵乘法实现this-sm90: Hopper版本的矩阵乘法this-sm80: 本仓库实现的矩阵乘法cublas: 调用CuBLAS进行性能测试cutlass: 调用CUTLASS进行性能测试mlir-gen: 由MLIR生成的CUDA代码triton: 调用Triton进行性能测试tvm: 调用Relay+CUTLASS/CuBLAS或TensorIR进行性能测试
-
atom: 单个内部指令/指令的使用 -
reduction: 用于后处理的一些归约内核
-
性能结果
H800 GPU上的性能
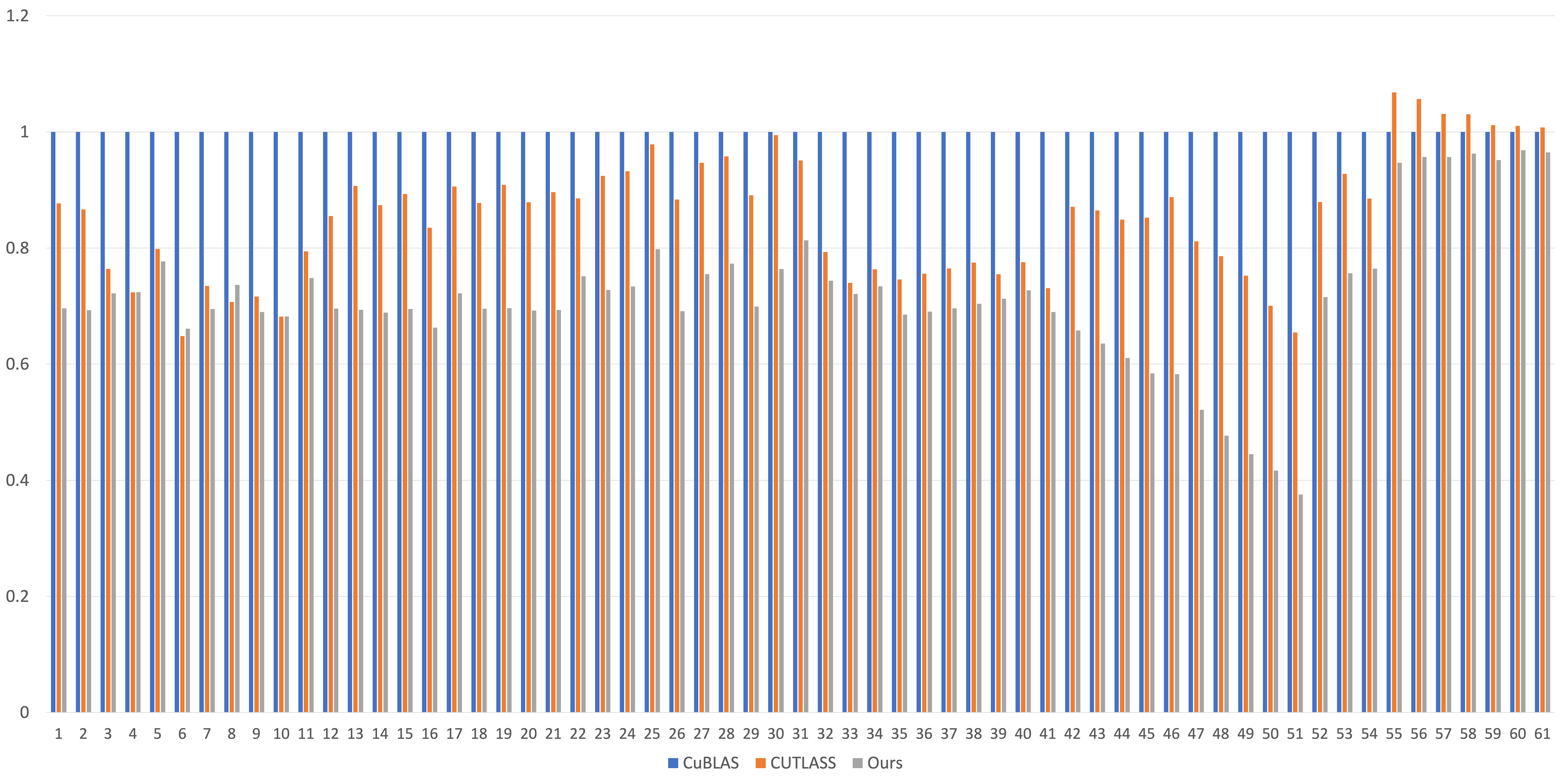 当前版本平均只达到CuBLAS性能的70%。我仍在努力提高性能。
当前版本平均只达到CuBLAS性能的70%。我仍在努力提高性能。
A100 GPU上的性能
<img src=static/this.png alt="A100-GEMM-perf" width="2000" height="600"> Relay、CuBLAS、CUTLASS、TensorIR、Triton和我们实现之间的整体性能比较。y轴是相对于Relay+CUTLASS的加速比。
总体而言,相对于Relay+CUTLASS的几何平均加速比为1.73倍,相对于TensorIR(每个案例使用MetaSchedule进行1000次调优尝试)为1.22倍,相对于CuBLAS为1.00倍,相对于CUTLASS为0.999倍,相对于Triton为1.07倍。 61种形状如下:
| 编号 | M | N | K |
|---|---|---|---|
| 1 | 5376 | 5376 | 2048 |
| 2 | 5376-128 | 5376 | 2048 |
| 3 | 5376-2*128 | 5376 | 2048 |
| ... | ... | ... | ... |
| 11 | 5376-10*128 | 5376 | 2048 |
| 12 | 5376+128 | 5376 | 2048 |
| 13 | 5376+2*128 | 5376 | 2048 |
| ... | ... | ... | ... |
| 21 | 5376+10*128 | 5376 | 2048 |
| 22 | 5376 | 5376-128 | 2048 |
| 23 | 5376 | 5376-2*128 | 2048 |
| ... | ... | ... | ... |
| 31 | 5376 | 5376-10*128 | 2048 |
| 32 | 5376 | 5376+128 | 2048 |
| 33 | 5376 | 5376+2*128 | 2048 |
| ... | ... | ... | ... |
| 41 | 5376 | 5376+10*128 | 2048 |
| 42 | 5376 | 5376 | 2048-128 |
| 43 | 5376 | 5376 | 2048-2*128 |
| ... | ... | ... | ... |
| 51 | 5376 | 5376 | 2048-10*128 |
| 52 | 5376 | 5376 | 2048+128 |
| 53 | 5376 | 5376 | 2048+2*128 |
| ... | ... | ... | ... |
| 61 | 5376 | 5376 | 2048+10*128 |
MLIR生成的CUDA内核
我还使用MLIR生成矩阵乘法内核。生成的内核位于examples/matmul/mlir-gen中。与手写内核(examples/matmul/this)相比的性能如下所示。由于MLIR生成的内核只实现了手写内核使用的部分优化,我们将MLIR生成的内核称为部分,将手写内核称为完整。
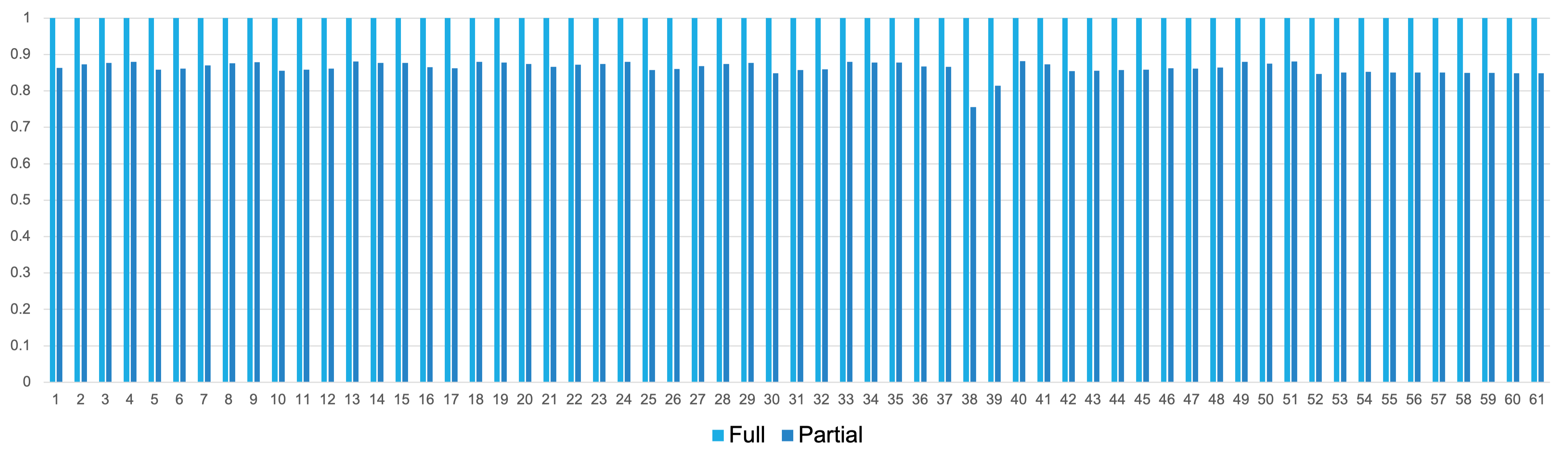 总体而言,MLIR生成的版本达到了手写内核性能的86%。
总体而言,MLIR生成的版本达到了手写内核性能的86%。
计划
更多内核
我计划在未来实现其他运算符(如softmax)的内核。
在实现中使用CUTLASS
计划使用CUTLASS的CuTe接口来实现高性能内核。











