
 访问官网
访问官网 Github
Github 论文
论文TurnVoice
一个命令行工具,可以转换(YouTube)视频中的声音,并具有额外的翻译功能。1
提示: 对最先进的语音解决方案感兴趣的人也请看看Linguflex。它让你通过说话来控制你的环境,是目前可用的最强大和复杂的开源助手之一。
https://github.com/KoljaB/TurnVoice/assets/7604638/e0d9071c-0670-44bd-a6d5-4800e9f6190c
功能
-
声音转换
使用免费的Coqui TTS转换声音,无运营成本 (支持声音克隆,包含58种声音 -
多样化声音
支持流行的TTS引擎,如Elevenlabs、OpenAI TTS或Azure,提供更多声音选择。2 -
翻译
以零成本翻译视频,例如从英语翻译成中文。由免费的deep-translator提供支持 -
改变说话风格 (AI驱动)
通过提示使每个口语句子以自定义说话风格传递,营造独特风格。3 -
完全渲染控制
通过自定义句子文本、时间和声音选择实现精确的渲染控制。💡 提示:Renderscript编辑器让这一步变得简单
-
本地视频处理
处理任何本地视频文件。 -
保留背景音频
保持原始背景音频不变。
在发布说明中了解更多。
先决条件
推荐使用Nvidia显卡,VRAM大于8 GB,在Python 3.11.4 / Windows 10上测试通过。
-
安装NVIDIA CUDA Toolkit:
- 访问NVIDIA CUDA Toolkit存档。
- 选择操作系统和版本。
- 下载并安装软件。
-
安装NVIDIA cuDNN。
安装NVIDIA cuDNN:
- 访问NVIDIA cuDNN存档。
- 下载并安装软件。
(测试版本为v8.7.0,更新版本也应该可以工作)
-
安装Rubberband命令行工具 4
-
使用包管理器安装ffmpeg:
-
在Ubuntu或Debian上:
sudo apt update && sudo apt install ffmpeg -
在Arch Linux上:
sudo pacman -S ffmpeg -
在MacOS上使用Homebrew (https://brew.sh/):
brew install ffmpeg -
在Windows上使用Chocolatey (https://chocolatey.org/):
choco install ffmpeg -
在Windows上使用Scoop (https://scoop.sh/):
scoop install ffmpeg
-
-
在环境变量HF_ACCESS_TOKEN中设置Huggingface访问令牌 6
[!提示] 使用
setx HF_ACCESS_TOKEN "your_token_here"设置你的HF令牌
安装
pip install turnvoice
[!提示] 为了使用GPU加快渲染速度,安装后准备你的CUDA环境:
对于CUDA 11.8
pip install torch==2.1.2+cu118 torchaudio==2.1.2+cu118 --index-url https://download.pytorch.org/whl/cu118对于CUDA 12.1
pip install torch==2.1.2+cu118 torchaudio==2.1.2+cu211 --index-url https://download.pytorch.org/whl/cu211
使用方法
turnvoice [-i] <YouTube URL|ID|本地文件> [-l] <翻译语言> -e <引擎> -v <声音> -o <输出文件>
为每个你想使用的说话人声音向'voice'参数提交一个字符串。如果你指定了引擎,声音将按列出的顺序分配给这些引擎。如果声音多于引擎,多出的声音将使用第一个引擎。如果没有指定引擎,将默认使用Coqui引擎。如果没有定义声音,将为每个引擎选择一个默认声音。
命令示例:
Arthur Morgan讲解一个烹饪教程:
turnvoice -i AmC9SmCBUj4 -v arthur.wav -o cooking_with_arthur.mp4
[!注意] 需要克隆声音文件(如arthur.wav或.json)在同一目录下(你可以在tests目录中找到一个)。
工作流程
准备
使用以下命令准备带有转录、说话人分离(以及可选的翻译或提示)的脚本:
turnvoice https://www.youtube.com/watch?v=cOg4J1PxU0c --prepare
翻译和提示应该在这个准备步骤中应用。引擎或声音将在之后的渲染步骤中使用。
Renderscript编辑器
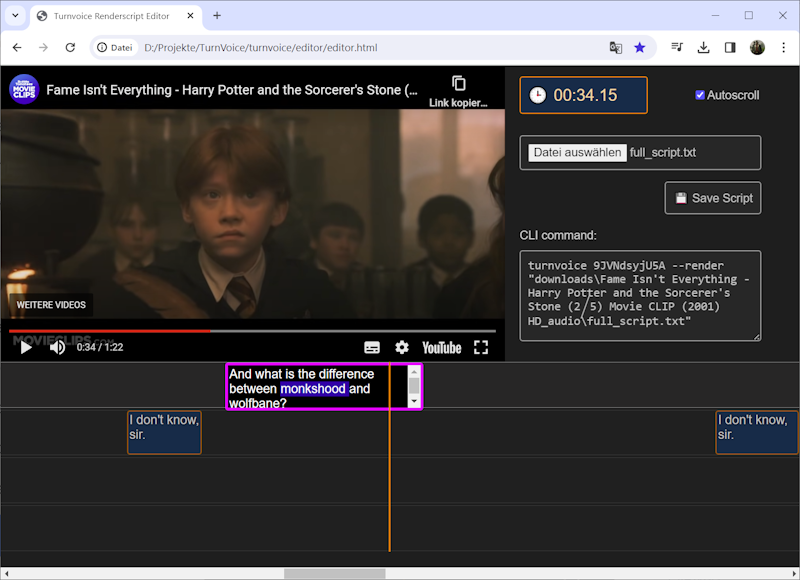
- 打开脚本
打开editor.html文件。点击文件打开按钮,导航到你启动turnvoice的文件夹。打开下载文件夹。打开与视频名称相同的文件夹。打开full_script.txt文件。 - 编辑
编辑器将可视化显示转录和说话人分离结果,并开始播放原始视频。在播放过程中,验证文本、开始时间和说话人分配,如果检测有误,请进行调整。 - 保存
保存脚本。记住文件的路径。
渲染
使用以下命令渲染精细的脚本以生成最终视频:
turnvoice https://www.youtube.com/watch?v=cOg4J1PxU0c --render <脚本路径>
调整显示的CLI命令中的路径(编辑器无法从浏览器读取该信息)。
使用-e和-v命令为每个说话人轨道分配引擎和声音。
参数
-i,--in: 输入视频。接受YouTube视频URL或ID,或本地视频文件路径。-l,--language: 翻译语言。Coqui合成支持:en, es, fr, de, it, pt, pl, tr, ru, nl, cs, ar, zh, ja, hu, ko。省略以保留原始视频语言。-il,--input_language: 转录的语言代码,如果自动检测失败则设置。-v,--voice: 用于合成的声音。接受多个值以替换多个说话人。-o,--output_video: 最终输出视频的文件名(默认:'final_cut.mp4')。-a,--analysis: 打印转录和说话人分析,不进行合成或渲染视频。-from: 开始处理视频的时间。-to: 停止处理视频的时间。-e,--engine: 用于合成的引擎。可以是coqui, elevenlabs, azure, openai或system。接受多个值,与提交的声音相关联。-s,--speaker: 要转换的说话人编号。-snum,--num_speakers: 帮助说话人分离。如果你事先知道视频中确切的说话人数量,请指定。-smin,--min_speakers: 帮助说话人分离。如果你事先知道视频中最少的说话人数量,请指定。-smax,--max_speakers: 帮助说话人分离。如果你事先知道视频中最多的说话人数量,请指定。-dd,--download_directory: 保存下载文件的目录(默认:'downloads')。-sd,--synthesis_directory: 保存合成音频文件的目录(默认:'synthesis')。-ex,--extract: 启用从视频文件中提取音频。否则从互联网下载音频(默认)。-c,--clean_audio: 从最终视频中移除原始音频,得到纯合成结果。-tf,--timefile: 定义用于处理的时间戳文件(功能类似于多个--from/--to命令)。-p,--prompt: 定义一个提示来改变句子的风格,如"杰克船长的说话风格" 3-prep,--prepare: 编写包含说话人分析、句子转换和翻译的完整脚本,但不执行合成或渲染。可以继续。-r,--render: 接受完整脚本并只执行合成和渲染,不进行说话人分析、句子转换或翻译。-faster,--use_faster: 使用faster_whisper进行转录。如果stable_whisper转录出现OOM错误或结果不理想时使用。(可选)-model,--model: 要使用的转录模型。默认为large-v2。可以是'tiny', 'tiny.en', 'base', 'base.en', 'small', 'small.en', 'medium', 'medium.en', 'large-v1', 'large-v2', 'large-v3', 或 'large'。(可选)
-i和-l可以作为位置参数和可选参数使用。
翻译
使用-l参数将视频翻译成另一种语言。
例如,要翻译成中文,你可以使用:
turnvoice https://www.youtube.com/watch?v=ZTH771HIhpg -l zh-CN -v daisy
输出视频
💡 提示: 在tests文件夹中你可以找到一个基于中文音素训练的"chinese.json"语音。
Coqui引擎支持的语言
| 简写 | 语言 |
|---|---|
| ar | 阿拉伯语 |
| cs | 捷克语 |
| de | 德语 |
| en | 英语 |
| es | 西班牙语 |
| fr | 法语 |
| it | 意大利语 |
| hu | 匈牙利语 |
| ja | 日语 |
| ko | 韩语 |
| nl | 荷兰语 |
| pl | 波兰语 |
| pt | 葡萄牙语 |
| ru | 俄语 |
| tr | 土耳其语 |
| zh-cn | 中文 |
其他引擎支持的语言
确保在Azure和系统引擎中选择支持该语言的语音。| 简写 | 语言 |
|---|---|
| af | 南非荷兰语 |
| sq | 阿尔巴尼亚语 |
| am | 阿姆哈拉语 |
| ar | 阿拉伯语 |
| hy | 亚美尼亚语 |
| as | 阿萨姆语 |
| ay | 艾马拉语 |
| az | 阿塞拜疆语 |
| bm | 班巴拉语 |
| eu | 巴斯克语 |
| be | 白俄罗斯语 |
| bn | 孟加拉语 |
| bho | 博杰普尔语 |
| bs | 波斯尼亚语 |
| bg | 保加利亚语 |
| ca | 加泰罗尼亚语 |
| ceb | 宿务语 |
| ny | 齐切瓦语 |
| zh-CN | 中文(简体) |
| zh-TW | 中文(繁体) |
| co | 科西嘉语 |
| hr | 克罗地亚语 |
| cs | 捷克语 |
| da | 丹麦语 |
| dv | 迪维希语 |
| doi | 多格拉语 |
| nl | 荷兰语 |
| en | 英语 |
| eo | 世界语 |
| et | 爱沙尼亚语 |
| ee | 埃维语 |
| tl | 菲律宾语 |
| fi | 芬兰语 |
| fr | 法语 |
| fy | 弗里西语 |
| gl | 加利西亚语 |
| ka | 格鲁吉亚语 |
| de | 德语 |
| el | 希腊语 |
| gn | 瓜拉尼语 |
| gu | 古吉拉特语 |
| ht | 海地克里奥尔语 |
| ha | 豪萨语 |
| haw | 夏威夷语 |
| iw | 希伯来语 |
| hi | 印地语 |
| hmn | 苗语 |
| hu | 匈牙利语 |
| is | 冰岛语 |
| ig | 伊博语 |
| ilo | 伊洛卡诺语 |
| id | 印度尼西亚语 |
| ga | 爱尔兰语 |
| it | 意大利语 |
| ja | 日语 |
| jw | 爪哇语 |
| kn | 卡纳达语 |
| kk | 哈萨克语 |
| km | 高棉语 |
| rw | 卢旺达语 |
| gom | 孔卡尼语 |
| ko | 韩语 |
| kri | 克里奥尔语 |
| ku | 库尔德语(库尔曼吉语) |
| ckb | 库尔德语(索拉尼语) |
| ky | 吉尔吉斯语 |
| lo | 老挝语 |
| la | 拉丁语 |
| lv | 拉脱维亚语 |
| ln | 林加拉语 |
| lt | 立陶宛语 |
| lg | 卢干达语 |
| lb | 卢森堡语 |
| mk | 马其顿语 |
| mai | 迈蒂利语 |
| mg | 马达加斯加语 |
| ms | 马来语 |
| ml | 马拉雅拉姆语 |
| mt | 马耳他语 |
| mi | 毛利语 |
| mr | 马拉地语 |
| mni-Mtei | 梅泰语(曼尼普尔语) |
| lus | 米佐语 |
| mn | 蒙古语 |
| my | 缅甸语 |
| ne | 尼泊尔语 |
| no | 挪威语 |
| or | 奥里亚语 |
| om | 奥罗莫语 |
| ps | 普什图语 |
| fa | 波斯语 |
| pl | 波兰语 |
| pt | 葡萄牙语 |
| pa | 旁遮普语 |
| qu | 克丘亚语 |
| ro | 罗马尼亚语 |
| ru | 俄语 |
| sm | 萨摩亚语 |
| sa | 梵语 |
| gd | 苏格兰盖尔语 |
| nso | 北索托语 |
| sr | 塞尔维亚语 |
| st | 塞索托语 |
| sn | 修纳语 |
| sd | 信德语 |
| si | 僧伽罗语 |
| sk | 斯洛伐克语 |
| sl | 斯洛文尼亚语 |
| so | 索马里语 |
| es | 西班牙语 |
| su | 巽他语 |
| sw | 斯瓦希里语 |
| sv | 瑞典语 |
| tg | 塔吉克语 |
| ta | 泰米尔语 |
| tt | 鞑靼语 |
| te | 泰卢固语 |
| th | 泰语 |
| ti | 提格利尼亚语 |
| ts | 聪加语 |
| tr | 土耳其语 |
| tk | 土库曼语 |
| ak | 契维语 |
| uk | 乌克兰语 |
| ur | 乌尔都语 |
| ug | 维吾尔语 |
| uz | 乌兹别克语 |
| vi | 越南语 |
| cy | 威尔士语 |
| xh | 科萨语 |
| yi | 意第绪语 |
| yo | 约鲁巴语 |
| zu | 祖鲁语 |
Coqui引擎
如果没有使用-e参数指定其他引擎,Coqui引擎是默认引擎。
使用Coqui的语音:
语音(-v参数)
你可以使用预定义的Coqui语音之一,或者克隆自己的语音。
预定义语音
要使用预定义语音,请提交以下语音之一的名称:
'Claribel Dervla', 'Daisy Studious', 'Gracie Wise', 'Tammie Ema', 'Alison Dietlinde', 'Ana Florence', 'Annmarie Nele', 'Asya Anara', 'Brenda Stern', 'Gitta Nikolina', 'Henriette Usha', 'Sofia Hellen', 'Tammy Grit', 'Tanja Adelina', 'Vjollca Johnnie', 'Andrew Chipper', 'Badr Odhiambo', 'Dionisio Schuyler', 'Royston Min', 'Viktor Eka', 'Abrahan Mack', 'Adde Michal', 'Baldur Sanjin', 'Craig Gutsy', 'Damien Black', 'Gilberto Mathias', 'Ilkin Urbano', 'Kazuhiko Atallah', 'Ludvig Milivoj', 'Suad Qasim', 'Torcull Diarmuid', 'Viktor Menelaos', 'Zacharie Aimilios', 'Nova Hogarth', 'Maja Ruoho', 'Uta Obando', 'Lidiya Szekeres', 'Chandra MacFarland', 'Szofi Granger', 'Camilla Holmström', 'Lilya Stainthorpe', 'Zofija Kendrick', 'Narelle Moon', 'Barbora MacLean', 'Alexandra Hisakawa', 'Alma María', 'Rosemary Okafor', 'Ige Behringer', 'Filip Traverse', 'Damjan Chapman', 'Wulf Carlevaro', 'Aaron Dreschner', 'Kumar Dahl', 'Eugenio Mataracı', 'Ferran Simen', 'Xavier Hayasaka', 'Luis Moray', 'Marcos Rudaski'
💡 提示:只需写"-v gracie"即可,因为语音名称的部分也能被识别,并且不区分大小写
克隆语音
提交一个或多个包含16位24kHz单声道源材料作为参考wav的音频文件的路径。
示例:
turnvoice https://www.youtube.com/watch?v=cOg4J1PxU0c -e coqui -v female.wav
选择参考wav的技巧
- 10-30秒的24000、44100或22050 Hz 16位单声道wav文件是你的最佳选择。
- 24k单声道16位是我的默认设置,但我也发现有些语音使用44100 32位效果最佳。
- 我在渲染之前使用这个工具测试语音。
- Audacity是调整采样率的好帮手。尝试不同的帧率以获得最佳结果!
固定TTS模型下载文件夹
保持模型有序!将COQUI_MODEL_PATH设置为你喜欢的文件夹。
Windows示例:
setx COQUI_MODEL_PATH "C:\Downloads\CoquiModels"
Elevenlabs引擎
[!注意] 要使用Elevenlabs语音,你需要将API密钥存储在环境变量ELEVENLABS_API_KEY中
所有语音都使用multilingual-v1模型合成。
[!警告] Elevenlabs是一个昂贵的API。专注于短视频。不要让这样一个正在开发中的脚本在按使用付费的API上无人值守地运行。错误发生在昂贵的长时间渲染过程结束时可能会非常令人恼火。
使用Elevenlabs的语音:
语音(-v参数)
提交生成的或预定义语音的名称。
示例:
turnvoice https://www.youtube.com/watch?v=cOg4J1PxU0c -e elevenlabs -v Giovanni
[!提示] 在使用昂贵的引擎之前,先用免费的引擎如Coqui测试渲染。
OpenAI引擎
[!注意] 要使用OpenAI TTS语音,你需要将API密钥存储在环境变量OPENAI_API_KEY中
使用OpenAI的语音:
语音(-v参数)
提交语音的名称。目前OpenAI只支持一种语音。Alloy、echo、fable、onyx、nova或shimmer。
示例:
turnvoice https://www.youtube.com/watch?v=cOg4J1PxU0c -e openai -v shimmer
Azure引擎
[!注意] 要使用Azure语音,您需要在AZURE_SPEECH_KEY中设置SpeechService资源的API密钥,并在AZURE_SPEECH_REGION中设置区域标识符
使用Azure语音:
语音(-v参数)
提交生成的或预定义的语音名称。
示例:
turnvoice https://www.youtube.com/watch?v=BqnAeUoqFAM -e azure -v ChristopherNeural
系统引擎
使用系统语音:
语音(-v参数)
以字符串形式提交语音名称。
示例:
turnvoice https://www.youtube.com/watch?v=BqnAeUoqFAM -e system -v David
注意事项
- 处于早期alpha/开发中状态,可能会出现错误(请报告,以便我们修复)
- 可能无法总是实现完美的唇形同步,尤其是在翻译成不同语言时
- 说话人检测效果不佳,可能是操作有误或技术7尚未达到可靠水平
- 翻译功能目前处于实验性原型状态(由deep-translate驱动),仍然产生不完美的结果
- 偶尔,合成可能会在音频中引入意外的噪音或失真(我们在新的v0.0.30算法中大大减少了音频伪影)
- 当源音频中同时存在说话声和带有歌唱的背景音乐时,spleeter可能会混淆
源质量
- 对于具有清晰口语内容的YouTube视频(播客、教育视频)效果最佳
- 需要高质量、干净的源WAV文件以实现有效的语音克隆
专业技巧
如何替换单个说话人
首先使用-a参数进行说话人分析:
turnvoice https://www.youtube.com/watch?v=2N3PsXPdkmM -a
然后使用-s参数从列表中选择一个说话人
turnvoice https://www.youtube.com/watch?v=2N3PsXPdkmM -s 2
许可证
TurnVoice自豪地采用Coqui公共模型许可证1.0.0。
联系方式 🤝
与我分享你最有趣或最富创意的TurnVoice作品!
如果你有很酷的功能想法或只是想打个招呼,可以通过以下方式联系我:
如果你喜欢这个仓库,请给个星星
✨ 🌟 ✨
Footnotes
-
目前处于开发中状态(早期预Alpha版)。请预期CLI API可能会发生变化,如果有任何不如预期的情况,我们提前表示歉意。
在Win 10上使用Python 3.11.4开发。 ↩ -
会产生费用。Elevenlabs价格较高,OpenAI TTS和Azure价格较为合理。需要将API密钥存储在环境变量中,详情请参见引擎信息。 ↩
-
会产生费用。使用gpt-4-1106-preview模型,需要将OpenAI API密钥存储在环境变量OPENAI_API_KEY中。 ↩ ↩2
-
需要Rubberband来进行音高保留的时间拉伸,以使合成音频适应时间窗口。 ↩
-
需要ffmpeg将mp3文件转换为wav格式。 ↩
-
需要Huggingface访问令牌来下载说话人分类模型,以使用pyannote.audio识别说话人。 ↩
-
使用pyannote.audio默认的HF实现在从原始音频分离出的人声轨道上进行说话人分类。 ↩











