
 访问官网
访问官网 Github
Github 文档
文档 论文
论文






|
Kompute跨供应商显卡(AMD、Qualcomm、NVIDIA及其伙伴)的通用GPU计算框架 |
极速、移动支持、异步,并针对高级GPU加速用例进行了优化。
💬 加入Discord和社区电话会议 🔋 文档 💻 博客文章 ⌨ 示例 💾
Kompute由<LF AI & Data Foundation>作为托管项目,得到Linux基金会的支持。
|
|

|
原则与特性
- 灵活的Python模块 以及 C++ SDK 用于优化
- 通过GPU族队列支持异步和并行处理
- 通过Android NDK在多个架构下的示例实现移动支持
- BYOV: 自带Vulkan设计 以与现有Vulkan应用程序配合良好
- 为GPU和主机显式设定内存所有权和内存管理的关系
- 稳健的代码库,具有90%单元测试代码覆盖率
- 在机器学习 🤖、移动开发 📱 和 游戏开发 🎮 上的高级用例
- 拥有每月会议、Discord 聊天等的活跃社区

使用Kompute的项目 ❤️ 🤖
- GPT4ALL
 - 在CPU和几乎任何GPU上本地运行的开源边缘大型语言模型生态系统。
- 在CPU和几乎任何GPU上本地运行的开源边缘大型语言模型生态系统。 - llama.cpp
 - Facebook的LLaMA模型的C/C++移植。
- Facebook的LLaMA模型的C/C++移植。 - tpoisonooo/how-to-optimize-gemm
 - 行优先顺序矩阵乘法优化。
- 行优先顺序矩阵乘法优化。 - vkJAX
 - 对Vulkan的JAX解释器。
- 对Vulkan的JAX解释器。
入门
下面是一个使用C++和Python Kompute接口的GPU乘法示例。
您可以加入Discord以提问/讨论,打开github问题,或阅读文档。
您的第一个Kompute(C++)
C++接口提供了对Kompute本机组件的低级访问,支持高级优化以及扩展组件。
void kompute(const std::string& shader) {
// 1. 使用默认设置创建Kompute Manager(设备0,第一队列,无扩展)
kp::Manager mgr;
// 2. 通过管理器创建并初始化Kompute张量
// 默认张量构造函数简化了浮点值的创建
auto tensorInA = mgr.tensor({ 2., 2., 2. });
auto tensorInB = mgr.tensor({ 1., 2., 3. });
// 显式类型构造函数支持uint32, int32, double, float和bool
auto tensorOutA = mgr.tensorT<uint32_t>({ 0, 0, 0 });
auto tensorOutB = mgr.tensorT<uint32_t>({ 0, 0, 0 });
std::vector<std::shared_ptr<kp::Tensor>> params = {tensorInA, tensorInB, tensorOutA, tensorOutB};
// 3. 基于着色器创建算法(支持缓冲区和推送/规范常量)
kp::Workgroup workgroup({3, 1, 1});
std::vector<float> specConsts({ 2 });
std::vector<float> pushConstsA({ 2.0 });
std::vector<float> pushConstsB({ 3.0 });
auto algorithm = mgr.algorithm(params,
// 参见文档中的着色器部分以编译源代码
compileSource(shader),
workgroup,
specConsts,
pushConstsA);
// 4. 使用序列同步运行操作
mgr.sequence()
->record<kp::OpTensorSyncDevice>(params)
->record<kp::OpAlgoDispatch>(algorithm) // 绑定默认的推送常量
->eval() // 评估两条记录的操作
->record<kp::OpAlgoDispatch>(algorithm, pushConstsB) // 覆盖推送常量
->eval(); // 仅评估最后记录的操作
// 5. 异步从GPU同步结果
auto sq = mgr.sequence();
sq->evalAsync<kp::OpTensorSyncLocal>(params);
// ... 在GPU完成时异步执行其他工作
sq->evalAwait();
// 打印第一个输出:{ 4, 8, 12 }
for (const float& elem : tensorOutA->vector()) std::cout << elem << " ";
// 打印第二个输出:{ 10, 10, 10 }
for (const float& elem : tensorOutB->vector()) std::cout << elem << " ";
} // 管理 / 释放所有CPU和GPU内存资源
int main() {
// 定义一个原始字符串着色器(或使用Kompute工具编译为SPIRV / C++头文件
//)。此着色器展示了一些主要组件,包括常量、缓冲区等
std::string shader = (R"(
#version 450
layout (local_size_x = 1) in;
// 输入张量绑定索引相对于参数中传递索引
layout(set = 0, binding = 0) buffer buf_in_a { float in_a[]; };
layout(set = 0, binding = 1) buffer buf_in_b { float in_b[]; };
layout(set = 0, binding = 2) buffer buf_out_a { uint out_a[]; };
layout(set = 0, binding = 3) buffer buf_out_b { uint out_b[]; };
// Kompute支持调度时更新的推送常量
layout(push_constant) uniform PushConstants {
float val;
} push_const;
// Kompute还支持初始化时的规范常量
layout(constant_id = 0) const float const_one = 0;
void main() {
uint index = gl_GlobalInvocationID.x;
out_a[index] += uint( in_a[index] * in_b[index] );
out_b[index] += uint( const_one * push_const.val );
}
)");
<SOURCE_TEXT>
// 运行上面声明的函数并传入我们的原始字符串着色器
kompute(shader);
}
您的第一个 Kompute (Python)
Python 包 提供了一个高级交互界面,使得在确保高性能和快速开发工作流程的同时进行实验。
from .utils import compile_source # 使用 python/test/utils 中的工具函数
def kompute(shader):
# 1. 使用默认设置(设备 0、第一个队列且无扩展)创建 Kompute 管理器
mgr = kp.Manager()
# 2. 通过管理器创建并初始化 Kompute 张量
# 默认的张量构造函数简化了浮点值的创建
tensor_in_a = mgr.tensor([2, 2, 2])
tensor_in_b = mgr.tensor([1, 2, 3])
# 显式类型构造函数支持 uint32、int32、double、float 和 bool
tensor_out_a = mgr.tensor_t(np.array([0, 0, 0], dtype=np.uint32))
tensor_out_b = mgr.tensor_t(np.array([0, 0, 0], dtype=np.uint32))
params = [tensor_in_a, tensor_in_b, tensor_out_a, tensor_out_b]
# 3. 基于着色器创建算法(支持缓冲区和推送/规格常量)
workgroup = (3, 1, 1)
spec_consts = [2]
push_consts_a = [2]
push_consts_b = [3]
# 参见文档中的着色器部分了解 compile_source
spirv = compile_source(shader)
algo = mgr.algorithm(params, spirv, workgroup, spec_consts, push_consts_a)
# 4. 使用序列同步运行操作
(mgr.sequence()
.record(kp.OpTensorSyncDevice(params))
.record(kp.OpAlgoDispatch(algo)) # 绑定默认的推送常量
.eval() # 执行记录的两个操作
.record(kp.OpAlgoDispatch(algo, push_consts_b)) # 覆盖推送常量
.eval()) # 仅执行最后记录的操作
# 5. 异步从 GPU 同步结果
sq = mgr.sequence()
sq.eval_async(kp.OpTensorSyncLocal(params))
# ...... 在 GPU 完成时异步进行其他工作
sq.eval_await()
# 打印第一个输出: { 4, 8, 12 }
print(tensor_out_a)
# 打印第二个输出: { 10, 10, 10 }
print(tensor_out_b)
if __name__ == "__main__":
# 定义原始字符串着色器(或使用 Kompute 工具编译到 SPIRV / C++ 头文件)。
# 该着色器展示了一些主要组件,包括常量、缓冲区等
shader = """
#version 450
layout (local_size_x = 1) in;
// 输入张量绑定索引相对于传递参数的索引
layout(set = 0, binding = 0) buffer buf_in_a { float in_a[]; };
layout(set = 0, binding = 1) buffer buf_in_b { float in_b[]; };
layout(set = 0, binding = 2) buffer buf_out_a { uint out_a[]; };
layout(set = 0, binding = 3) buffer buf_out_b { uint out_b[]; };
// Kompute 支持在调度时更新推送常量
layout(push_constant) uniform PushConstants {
float val;
} push_const;
// Kompute 还支持在初始化时设置规格常量
layout(constant_id = 0) const float const_one = 0;
void main() {
uint index = gl_GlobalInvocationID.x;
out_a[index] += uint( in_a[index] * in_b[index] );
out_b[index] += uint( const_one * push_const.val );
}
"""
kompute(shader)
交互式笔记本和动手视频
您可以尝试使用免费的 GPU 进行交互式 Colab 笔记本。可用的示例包括以下 Python 和 C++ 示例:
尝试 C++ Colab 的交互式 博客文章 |
尝试 Python Colab 的交互式 博客文章 |
|
|
您还可以观看在 FOSDEM 2021 会议上展示的以下两个演讲。
两个视频都有时间戳,可以让您跳到最相关的部分——两者的介绍和动机几乎相同,所以您可以跳到更多的具体内容。
观看 C++ 爱好者 的视频 |
观看 Python 和机器学习 爱好者的视频 |
|
|
架构概述
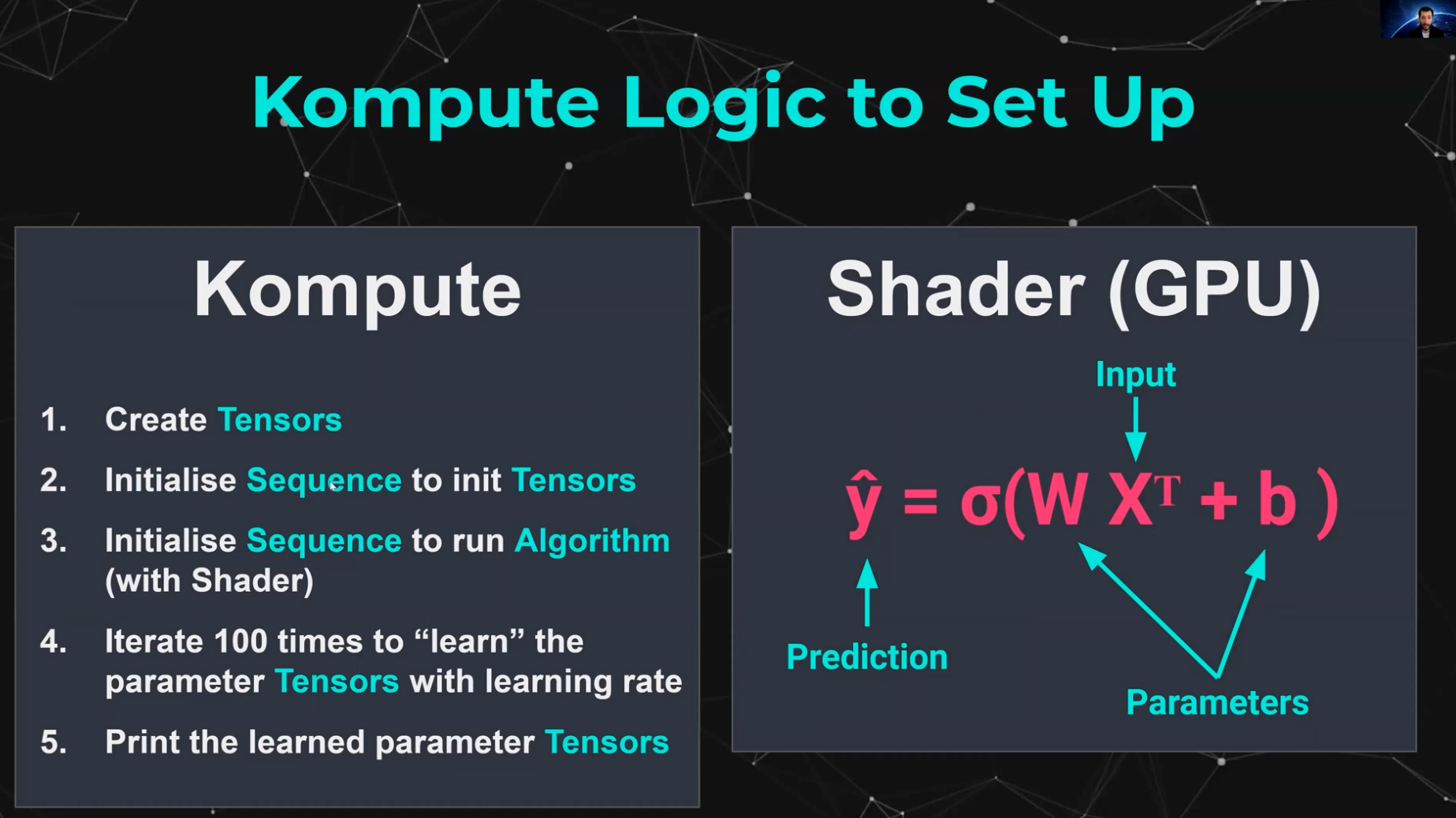
Kompute 的核心架构包括以下内容:
- Kompute 管理器 - 基础协调器,创建并管理设备和子组件
- Kompute 序列 - 可以作为批次发送到 GPU 的操作容器
- Kompute 操作(基础) - 所有操作继承的基类
- Kompute 张量 - 用于 GPU 操作的张量结构数据
- Kompute 算法 - 在 GPU 中执行的(着色器)逻辑抽象
欲了解详细信息,请参阅C++ 类参考。
| 全架构 | 简化的 Kompute 组件 |
|---|---|
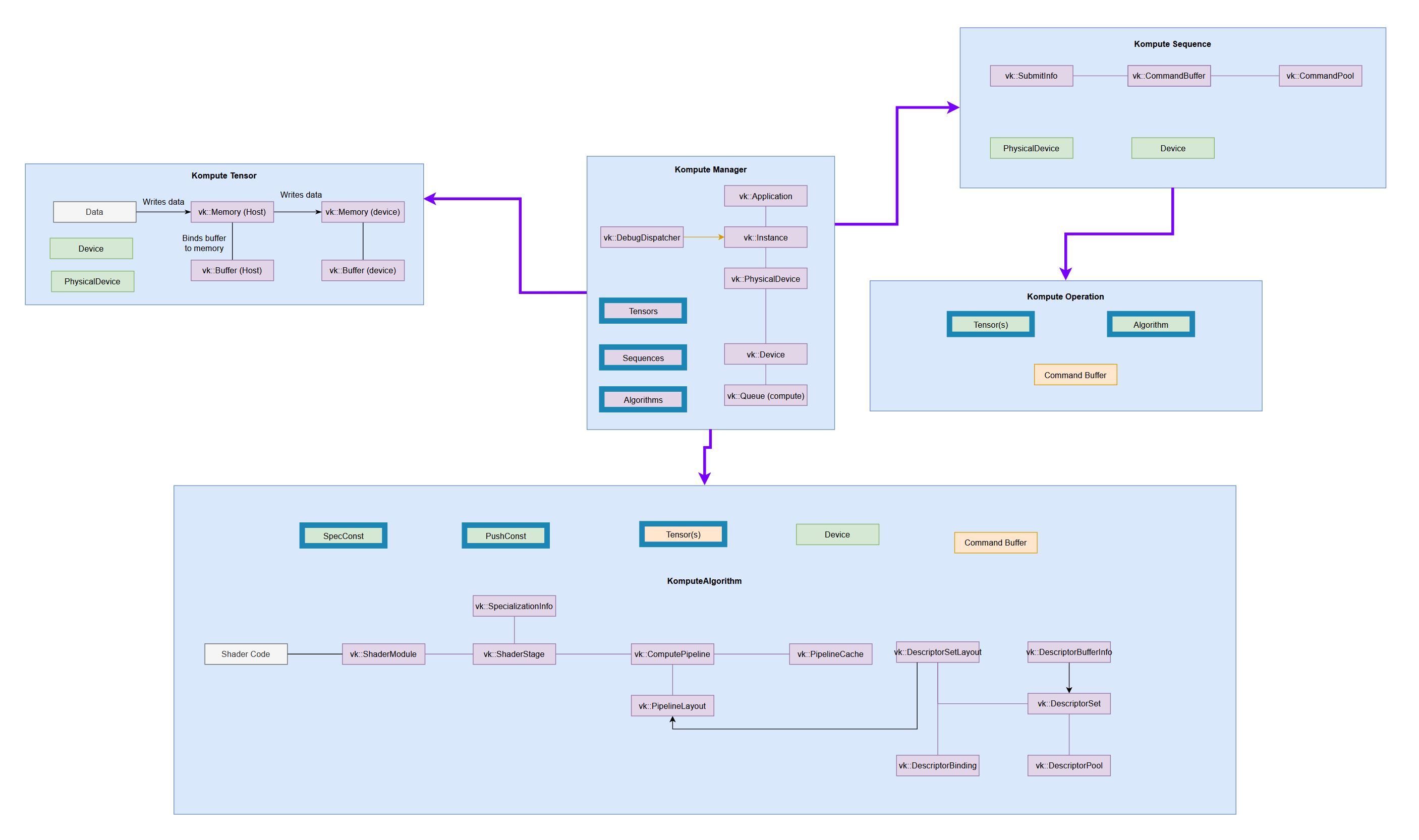
(很小,查看文档中的完整参考图以了解详情) |

|
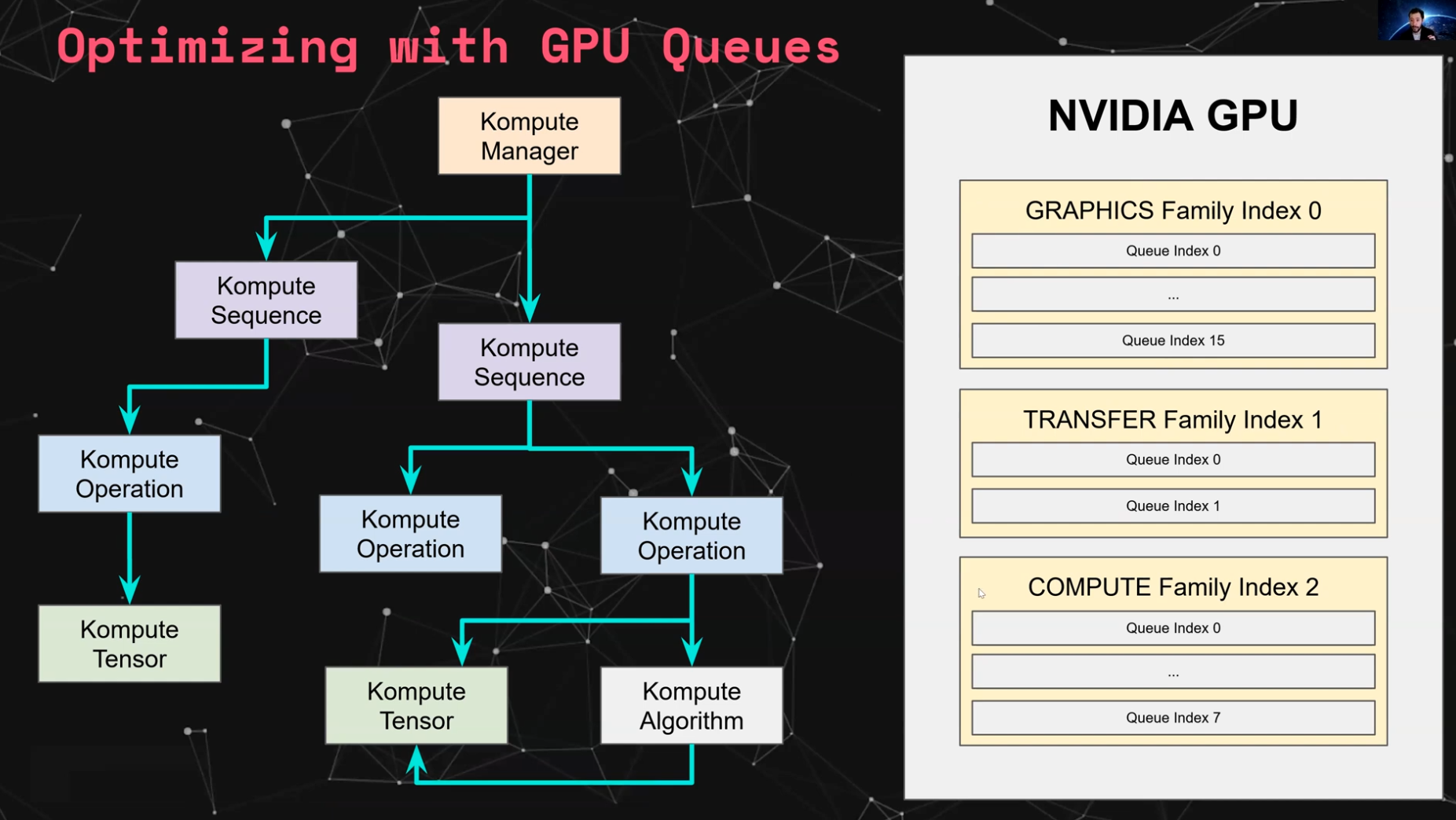
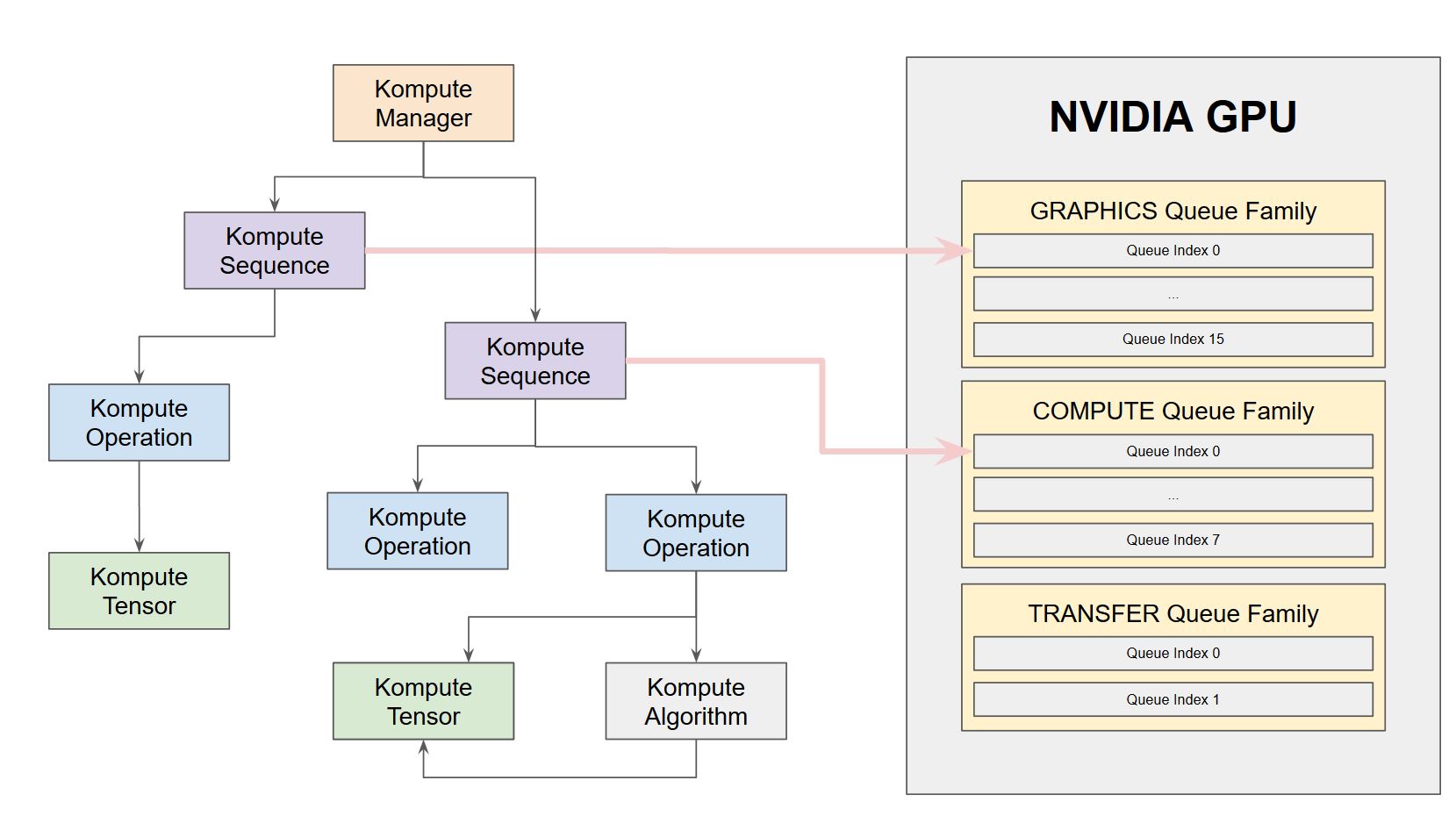
异步和并行操作
Kompute 通过 vk::Fences 提供了异步运行操作的灵活性。此外,Kompute 还支持队列的显式分配,允许在不同的队列族之间并行执行操作。
下图为 Kompute 序列分配到不同队列以启用基于硬件的并行执行提供了直观说明。您可以查看动手示例,以及描述其如何使用 NVIDIA 1650 作为示例的详细文档页面。
移动设备支持
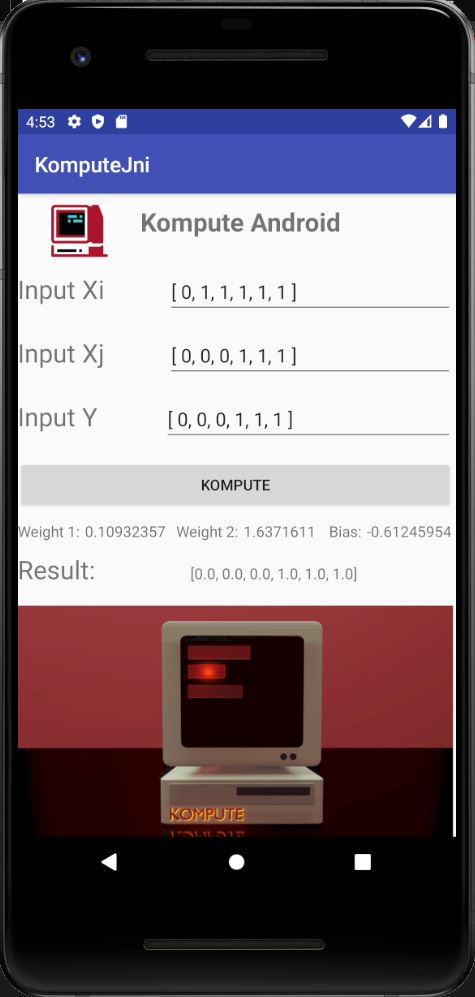
Kompute 已针对移动环境进行了优化。构建系统支持在 Android 环境中动态加载 Vulkan 共享库,以及一个工作的Android NDK 包装器用于 CPP 头文件。
```|
如果想要深入了解,您可以阅读博客文章 "用流设备GPU加速机器学习来提升您的移动应用"。 您还可以在储存库中访问 端到端示例代码,该代码可以使用安卓工作室运行。 
|
|
更多示例
简单示例
端到端示例
Python包
除了C++核心SDK,您还可以使用Kompute的Python包,该包提供相同的核心功能,并支持与Python对象(如Lists、Numpy Arrays等)的互操作性。
唯一的依赖项是Python 3.5+和Cmake 3.4.1+。您可以使用以下命令从Python pypi包中安装Kompute。
pip install kp
您还可以从master分支安装:
pip install git+git://github.com/KomputeProject/kompute.git@master
有关更多详细信息,您可以阅读Python包文档或Python类参考文档。
C++构建概述
提供的构建系统使用cmake,允许跨平台构建。
顶层的Makefile提供了一组针对开发和docker镜像构建的优化配置,但您可以使用以下命令开始构建:
cmake -Bbuild
您还可以使用add_subdirectory将Kompute添加到您的repo中,安卓示例CMakeLists.txt文件展示了如何完成这项工作。
有关构建配置的更高级概述,请参阅构建系统深度剖析文档。
Kompute开发
我们欢迎PR和Issue贡献。如果您想贡献代码,请尝试查看“好第一个问题”标签,但即便是使用Kompute并报告问题也是极大的贡献!
贡献
开发依赖项
- 测试
- GTest
- 文档
- Doxygen(带Dot)
- Sphynx
开发
- 遵循Mozilla C++风格指南 https://www-archive.mozilla.org/hacking/mozilla-style-guide.html
- 使用post-commit hook来运行linter,您可以设置它在提交前运行linter
- 所有依赖项都定义在vcpkg.json中
- 使用cmake作为构建系统,并提供了带推荐命令的顶层makefile
- 使用xxd(或xxd.exe windows 64位端口)将shader spirv转换为头文件
- 使用doxygen和sphinx进行文档和自动文档生成
- 使用vcpkg查找依赖项,它是检索库的推荐设置
如果您想使用debug层运行,您可以通过以下参数添加它们:
export KOMPUTE_ENV_DEBUG_LAYERS="VK_LAYER_LUNARG_api_dump"
更新文档
要更新文档,您需要:
- 在构建系统中运行gendoxygen目标
- 在构建系统中运行gensphynx目标
- 使用
make push_docs_to_ghpages推送到github页面
运行测试
对于贡献者来说,运行单元测试已经大大简化。
测试在CPU上运行,可以使用ACT命令行界面触发(https://github.com/nektos/act) - 一旦您安装了命令行(并启动了Docker守护程序),您只需键入:
$ act
[Python Tests/python-tests] 🚀 Start image=axsauze/kompute-builder:0.2
[C++ Tests/cpp-tests ] 🚀 Start image=axsauze/kompute-builder:0.2
[C++ Tests/cpp-tests ] 🐳 docker run image=axsauze/kompute-builder:0.2 entrypoint=["/usr/bin/tail" "-f" "/dev/null"] cmd=[]
[Python Tests/python-tests] 🐳 docker run image=axsauze/kompute-builder:0.2 entrypoint=["/usr/bin/tail" "-f" "/dev/null"] cmd=[]
...
储存库包含C++和Python代码的单元测试,可以在test/和python/test文件夹下找到。
这些测试目前通过Github Actions在CI中运行。它使用docker-builders/文件夹中的镜像。
为了减少硬件要求,测试可以直接在CPU上运行,无需GPU,使用Swiftshader。
有关CI和测试设置的更多信息,您可以访问文档中的CI、Docker和测试部分。
动机
在看到许多新的和知名的机器学习和深度学习项目(如Pytorch、Tensorflow、阿里巴巴DNN、腾讯NCNN等)已经或正在考虑将Vulkan SDK集成以增加移动设备(和跨供应商)的GPU支持后,该项目启动。
Vulkan SDK提供了一个优秀的低级接口,使得高度专业化的优化成为可能——然而它的代价是高度冗长的代码,需要500-2000行代码才能开始编写应用程序代码。这导致每个项目都必须实现相同的基线来抽象与计算无关的Vulkan SDK特性。这大量的非标准化样板代码可能导致知识转移有限,以及引入独特框架实现错误的机会更大等问题。
我们目前正在开发Kompute并不是为了隐藏Vulkan SDK接口(因为它设计得非常好),而是为了增强其以直接专注于Vulkan SDK的GPU计算能力。这篇文章提供了Kompute动机的高层概述,并介绍了一系列实际操作示例,这些示例介绍了GPU计算以及核心Kompute架构。











