
 Github
Github 论文
论文基于框架场学习的多边形建筑物分割
我们在图像分割神经网络中添加了一个框架场输出,以提高分割质量并为后续的多边形化步骤提供结构信息。

图1:测试图像上我们额外的框架场输出的特写。

图2:给定一张俯视图,模型输出建筑物的边缘掩码、内部掩码和框架场。总损失包括将掩码和框架场与地面真实数据对齐的项,以及强制框架场平滑和输出之间一致性的正则化项。
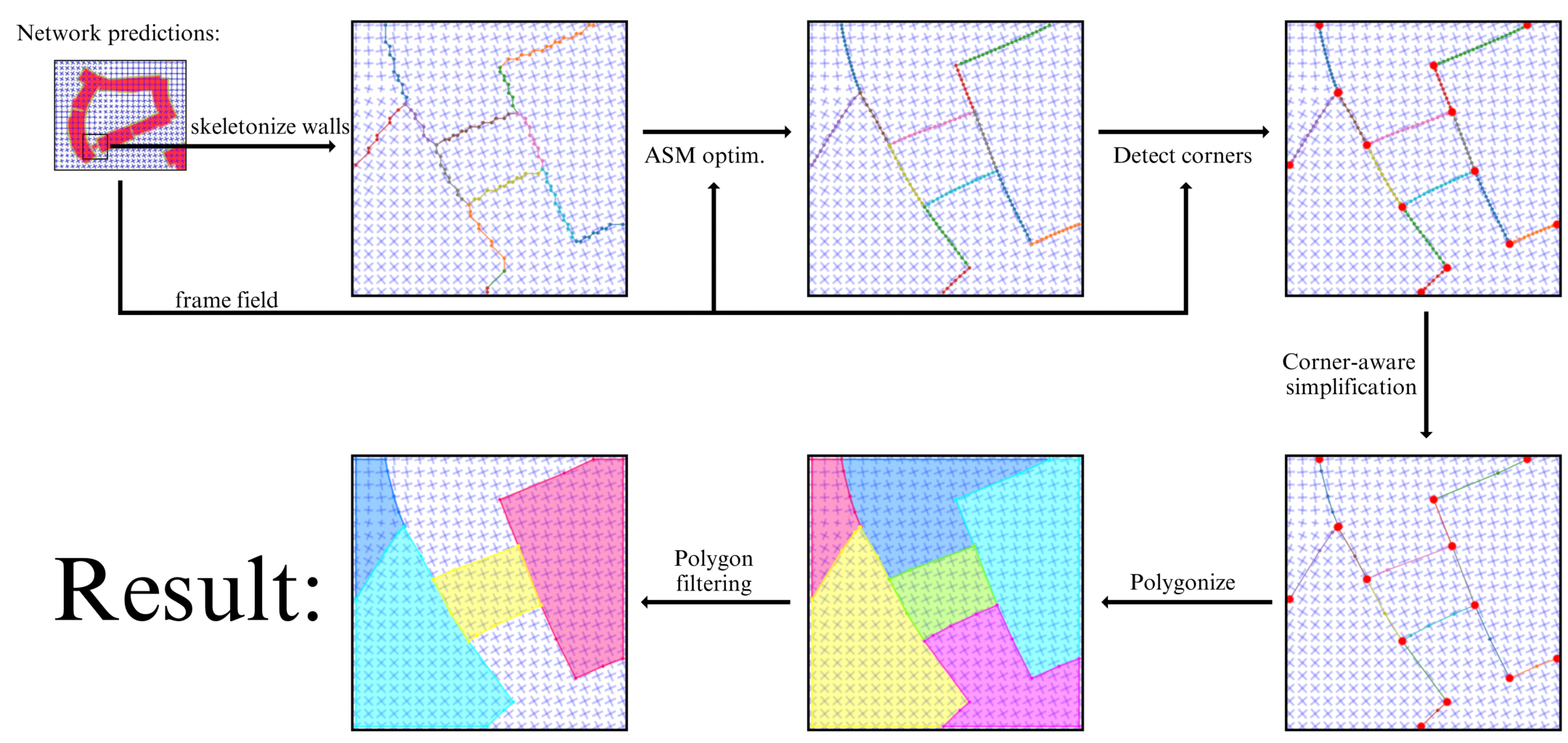
图3:给定分类图和框架场作为输入,我们使用主动骨架模型(ASM)优化骨架多段线以与框架场对齐,并使用框架场检测角点,简化非角点顶点。
本仓库包含以下论文的官方代码:
基于框架场学习的多边形建筑物分割
Nicolas Girard,
Dmitriy Smirnov,
Justin Solomon,
Yuliya Tarabalka
CVPR 2021
[论文, 视频]
设置
Git子模块
本项目使用了多个需要一同克隆的git子模块。
要克隆包含其子模块的仓库,请执行:
git clone --recursive --jobs 8 <Git仓库的URL>
如果你已经克隆了仓库,现在想要加载其子模块,请执行:
git submodule update --init --recursive --jobs 8
或:
git submodule update --recursive
关于使用子模块和git的更多解释,请参见SUBMODULES.md。
虚拟环境
截至2022年12月,venv可能是使用提供的requirements.txt安装包含所有必需依赖项的虚拟环境的最佳解决方案。我使用Python 3.10和PyTorch 1.13。
Docker
旧解决方案:使用我在这里提供的旧Docker镜像:docker(请参阅文件夹内的README)。 然而,它构建了一个不能保证与更新后的代码兼容的旧环境。
一旦Docker容器构建并启动,在内部执行setup.sh脚本以安装所需的包。
容器中的环境现在已准备就绪。
Conda环境
旧解决方案:在conda环境中安装所有依赖项。 我在environment.yml中提供了我的环境规格,你可以用它来创建自己的环境:
conda env create -f environment.yml
数据
本工作使用了几个数据集。
我们通常将所有数据集放在一个"data"文件夹中,并将其链接到容器中的"/data"文件夹(使用运行容器时的-v参数)。
每个数据集都有自己的子文件夹,通常以该数据集名称的简短版本命名。
每个数据集子文件夹内应该有一个"raw"文件夹,其中包含该数据集的所有原始文件夹和文件。
在预处理数据时,将在"raw"文件夹旁边创建"processed"文件夹。
例如,以下是容器内的一个示例工作文件结构:
/data
|-- AerialImageDataset
|-- raw
|-- train
| |-- aligned_gt_polygons_2
| |-- gt
| |-- gt_polygonized
| |-- images
`-- test
|-- aligned_gt_polygons_2
|-- images
`-- mapping_challenge_dataset
|-- raw
|-- train
| |-- images
| |-- annotation.json
| `-- annotation-small.json
`-- val
`-- ...
但是,如果你想为数据集使用不同的文件夹(例如在不使用Docker时), 你可以在配置文件中更改数据集的路径。 你可以修改配置中的"data_dir_candidates"列表,使其只包含你的路径。 训练脚本会逐一检查此路径列表,并选择第一个存在的路径。 然后它会附加"data_root_partial_dirpath"目录以到达数据集。
你可以在这个共享的"data"文件夹中找到我们使用的一些数据:https://drive.google.com/drive/folders/19yqseUsggPEwLFTBl04CmGmzCZAIOYhy?usp=sharing。
Inria航空图像标记数据集
数据集链接:https://project.inria.fr/aerialimagelabeling/
对于Inria数据集,原始的地面真实数据只是一组光栅掩码。 由于我们的方法需要注释为多边形以计算框架场的地面真实角度,我们制作了该数据集的两个版本:
Inria OSM数据集具有从OpenStreetMap拉取的对齐注释。
Inria多边形化数据集具有通过在原始光栅掩码上使用我们的框架场多边形化算法获得的多边形注释。
这是通过运行polygonize_mask.py脚本完成的,如下所示:
python polygonize_mask.py --run_name inria_dataset_osm_mask_only.unet16 --filepath ~/data/AerialImageDataset/raw/train/gt/*.tif
你可以在共享的"data"文件夹中找到这两种情况的新地面真实数据(https://drive.google.com/drive/folders/19yqseUsggPEwLFTBl04CmGmzCZAIOYhy?usp=sharing)。
运行main.py脚本
执行main.py脚本来训练模型、测试模型或在你自己的图像上使用模型。 使用以下命令查看主脚本的帮助:
python main.py --help
该脚本可以在多个GPU上启动,以进行多GPU训练和评估。
只需将--gpus参数设置为您想使用的GPU数量即可。
但是,在特定数据集上首次启动脚本时(预处理数据时),最好将其保持为1,因为我没有在预处理数据集时实现多GPU同步。
使用示例是用特定配置文件训练模型,如下所示:
python main.py --config configs/config.mapping_dataset.unet_resnet101_pretrained
这将在CrowdAI Mapping Challenge数据集上训练Unet-Resnet101。
可以按如下方式调整批量大小:
python main.py --config configs/config.mapping_dataset.unet_resnet101_pretrained -b <新的批量大小>
训练完成后,可以在评估模式下启动脚本,以评估训练好的模型:
python main.py --config configs/config.mapping_dataset.unet_resnet101_pretrained --mode eval。
根据配置文件的评估参数,运行此命令将输出测试数据集的结果。
最后,如果您希望使用COCO API计算AP和AR指标,可以运行:
python main.py --config configs/config.mapping_dataset.unet_resnet101_pretrained --mode eval_coco。
在单张图像上进行推理
确保运行文件夹具有正确的结构:
Polygonization-by-Frame-Field-Learning
|-- frame_field_learning
| |-- runs
| | |-- <run_name> | <yyyy-mm-dd hh:mm:ss>
| | `-- ...
| |-- inference.py
| `-- ...
|-- main.py
|-- README.md (本文件)
`-- ...
执行[main.py]脚本,如下所示(填写run_name和in_filepath参数的值):
python main.py --run_name <run_name> --in_filepath <您的图像文件路径>
输出将保存在输入图像旁边
下载训练好的模型
我们提供了已经训练好的模型,您可以立即进行推理。
在此下载:https://drive.google.com/drive/folders/1poTQbpCz12ra22CsucF_hd_8dSQ1T3eT?usp=sharing。
每个模型都是在一个"运行"中训练的,您可以在提供的链接中下载其文件夹(名称格式为<run_name> | <yyyy-mm-dd hh:mm:ss>)。
然后,您应该将这些运行文件夹放在"frame_field_learning"文件夹内名为"runs"的文件夹中,如下所示:
Polygonization-by-Frame-Field-Learning
|-- frame_field_learning
| |-- runs
| | |-- inria_dataset_polygonized.unet_resnet101_pretrained.leaderboard | 2020-06-02 07:57:31
| | |-- mapping_dataset.unet_resnet101_pretrained.field_off.train_val | 2020-09-07 11:54:48
| | |-- mapping_dataset.unet_resnet101_pretrained.train_val | 2020-09-07 11:28:51
| | `-- ...
| |-- inference.py
| `-- ...
|-- main.py
|-- README.md (本文件)
`-- ...
由于Google Drive会重新格式化文件夹名称,您需要按上述方式重命名运行文件夹。
引用:
如果您在自己的研究中使用此代码,请引用
@InProceedings{Girard_2021_CVPR,
author = {Girard, Nicolas and Smirnov, Dmitriy and Solomon, Justin and Tarabalka, Yuliya},
title = {Polygonal Building Extraction by Frame Field Learning},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021},
pages = {5891-5900}
}











