
 Github
Github 文档
文档 论文
论文CamLiFlow 和 CamLiRAFT
![]()
![]()
这是我们两篇论文的官方 PyTorch 实现:
-
会议版本:CamLiFlow:用于联合光流和场景流估计的双向相机-激光雷达融合。(CVPR 2022 口头报告)
-
扩展版本(CamLiRAFT):通过双向相机-激光雷达融合学习光流和场景流。(TPAMI 2023)
中文解读:https://zhuanlan.zhihu.com/p/616384758
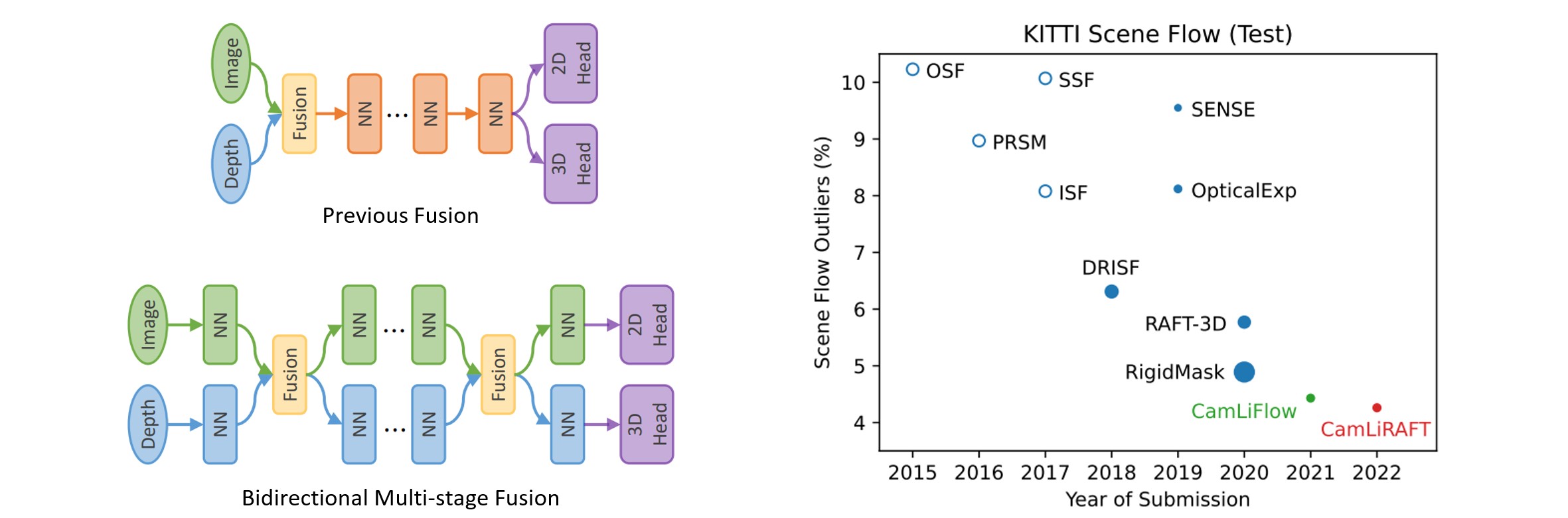
相对于会议论文的改进
在这个扩展版本中,我们基于递归全对场变换实例化了双向融合管道的新类型,即 CamLiRAFT。CamLiRAFT 相比原始基于 PWC 的 CamLiFlow 获得了显著的性能提升,并在多个数据集上创造了新的最先进记录。
-
与立体场景流方法的比较:在 FlyingThings3D 上,CamLiRAFT 达到了 1.73 EPE2D 和 0.049 EPE3D,比 CamLiFlow 降低了 21% 和 20% 的误差。在 KITTI 上,即使是非刚性的 CamLiRAFT 也与之前最先进的方法 RigidMask 表现相当(SF-all:4.97% vs. 4.89%)。通过使用刚性先验细化背景场景流,CamLiRAFT 进一步将误差降低到 4.26%,在排行榜上排名第一。
-
与仅使用激光雷达的场景流方法的比较:我们方法的仅使用激光雷达的变体,称为 CamLiRAFT-L,在精度和速度方面也优于所有以前仅使用激光雷达的场景流方法(见论文中的表 5)。因此,CamLiRAFT-L 也可以作为仅使用激光雷达的场景流估计的强有力基准。
-
在 MPI Sintel 上的比较:在未对 Sintel 进行微调的情况下,CamLiRAFT 在 Sintel 训练集的 final pass 上达到了 2.38 AEPE,比 RAFT 和 RAFT-3D 分别降低了 12% 和 18% 的误差。这表明我们的方法具有良好的泛化性能,并且可以处理非刚性运动。
-
训练计划:原始的 CamLiFlow 需要复杂的训练计划:Things(L2 损失)-> Things(鲁棒损失)-> Driving -> KITTI,训练需要约 10 天。CamLiRAFT 将计划简化为 Things -> KITTI,训练仅需约 3 天。(在 4 个 RTX 3090 GPU 上测试)
新闻
- 2023-11-05:CamLiRAFT 被 TPAMI 接受。感谢审稿人的宝贵建议!
- 2023-09-20:我们为 CamLiRAFT 提供了一个演示,详情请参见
demo.py。 - 2023-03-22:我们发布了 CamLiFlow 的扩展版本 CamLiRAFT,地址为 https://arxiv.org/abs/2303.12017。
- 2022-03-29:我们的论文被选为口头报告。
- 2022-03-07:我们发布了代码和预训练权重。
- 2022-03-03:我们的论文被 CVPR 2022 接受。
- 2021-11-20:我们的论文可在 https://arxiv.org/abs/2111.10502 获取。
- 2021-11-04:我们的方法在 KITTI 场景流 排行榜上排名第一。
预训练权重
| 模型 | 训练集 | 权重 | 备注 |
|---|---|---|---|
| CamLiRAFT | Things (80轮) | camliraft_things80e.pt | 最佳泛化性能 |
| CamLiRAFT | Things (150轮) | camliraft_things150e.pt | Things上的最佳性能 |
| CamLiRAFT | Things (150轮) -> KITTI (800轮) | camliraft_things150e_kitti800e.pt | KITTI上的最佳性能 |
| CamLiRAFT-L | Things-Occ (100轮) | camliraft_l_best_things_occ.pt | Things-Occ上的最佳性能 |
| CamLiRAFT-L | Things-Occ (100轮) | camliraft_l_best_kitti_occ.pt | KITTI-Occ上的最佳泛化性能 |
| CamLiRAFT-L | Things-Noc (100轮) | camliraft_l_best_things_noc.pt | Things-Noc上的最佳性能 |
| CamLiRAFT-L | Things-Noc (100轮) | camliraft_l_best_kitti_noc.pt | KITTI-Noc上的最佳泛化性能 |
Things-Occ表示"有遮挡的FlyingThings3D",Things-Noc表示"无遮挡的FlyingThings3D"。KITTI-Occ和KITTI-Noc同理。
预计算结果
这里,我们提供了提交到KITTI场景流在线基准测试的预计算结果。*表示使用刚性先验对背景场景流进行优化。
| 模型 | D1-all | D2-all | Fl-all | SF-all | 链接 |
|---|---|---|---|---|---|
| CamLiFlow | 1.81% | 3.19% | 4.05% | 5.62% | camliflow-wo-refine.zip |
| CamLiFlow * | 1.81% | 2.95% | 3.10% | 4.43% | camliflow.zip |
| CamLiRAFT | 1.81% | 3.02% | 3.43% | 4.97% | camliraft-wo-refine.zip |
| CamLiRAFT * | 1.81% | 2.94% | 2.96% | 4.26% | camliraft.zip |
环境配置
使用conda创建PyTorch环境:
conda create -n camliraft python=3.7
conda activate camliraft
conda install pytorch==1.10.2 torchvision==0.11.3 cudatoolkit=11.3 -c pytorch
安装mmcv和mmdet:
pip install openmim
mim install mmcv-full==1.4.0
mim install mmdet==2.14.0
安装其他依赖:
pip install opencv-python open3d tensorboard hydra-core==1.1.0
编译CUDA扩展以加快训练和评估:
cd models/csrc
python setup.py build_ext --inplace
下载在ImageNet-1k上预训练的ResNet-50:
wget https://download.pytorch.org/models/resnet50-11ad3fa6.pth
mkdir pretrain
mv resnet50-11ad3fa6.pth pretrain/
如果您想在KITTI上进行评估,还需要NG-RANSAC。请按照https://github.com/vislearn/ngransac的说明安装该库。
演示
然后,运行以下脚本来启动一个从一对图像和点云估计光流和场景流的演示:
python demo.py --model camliraft --weights /path/to/camliraft/checkpoint.pt
请注意,CamLiRAFT对距离较远的物体不太稳健,因为网络仅在深度小于35m的数据上进行了训练。如果您在自己的数据上得到了不好的结果,请尝试将点云的深度缩放到5~35m的范围内。
评估CamLiFlow和CamLiRAFT
FlyingThings3D
首先,下载并预处理数据集(详细说明请参见 preprocess_flyingthings3d_subset.py):
python preprocess_flyingthings3d_subset.py --input_dir /mnt/data/flyingthings3d_subset
然后,下载预训练权重 camliraft_things150e.pt 并保存到 checkpoints/camliraft_things150e.pt。
现在您可以重现表2中的结果(参见扩展论文):
python eval_things.py testset=flyingthings3d_subset model=camliraft ckpt.path=checkpoints/camliraft_things150e.pt
KITTI
首先,下载以下部分:
- 主要数据: data_scene_flow.zip
- 校准文件: data_scene_flow_calib.zip
- 视差估计(来自GA-Net): disp_ganet.zip
- 语义分割(来自DDR-Net): semantic_ddr.zip
解压它们并按如下方式组织目录:
datasets/kitti_scene_flow
├── testing
│ ├── calib_cam_to_cam
│ ├── calib_imu_to_velo
│ ├── calib_velo_to_cam
│ ├── disp_ganet
│ ├── flow_occ
│ ├── image_2
│ ├── image_3
│ ├── semantic_ddr
└── training
├── calib_cam_to_cam
├── calib_imu_to_velo
├── calib_velo_to_cam
├── disp_ganet
├── disp_occ_0
├── disp_occ_1
├── flow_occ
├── image_2
├── image_3
├── obj_map
├── semantic_ddr
然后,下载预训练权重 camliraft_things150e_kitti800e.pt 并保存到 checkpoints/camliraft_things150e_kitti800e.pt。
要重现不利用刚体假设的结果(SF-all: 4.97%):
python kitti_submission.py testset=kitti model=camliraft ckpt.path=checkpoints/camliraft_things150e_kitti800e.pt
要重现使用刚性背景细化的结果(SF-all: 4.26%),您需要进一步细化背景场景流:
python refine_background.py
结果保存在 submission/testing 中。初始的非刚性估计用 _initial 后缀表示。
Sintel
首先,从以下链接下载光流数据集: http://sintel.is.tue.mpg.de 和深度数据集: https://sintel-depth.csail.mit.edu/landing
解压它们并按如下方式组织目录:
datasets/sintel
├── depth
│ ├── README_depth.txt
│ ├── sdk
│ └── training
└── flow
├── bundler
├── flow_code
├── README.txt
├── test
└── training
然后,下载预训练权重 camliraft_things80e.pt 并保存到 checkpoints/camliraft_things80e.pt。
现在您可以重现表4中的结果(参见扩展论文):
python eval_sintel.py testset=sintel model=camliraft ckpt.path=checkpoints/camliraft_things80e.pt
评估 CamLiRAFT-L
FlyingThings3D
数据预处理有两种不同的方式。第一种设置是由HPLFlowNet提出的,在预处理过程中只保留非遮挡点。第二种设置由FlowNet3D提出,保留遮挡点。
# 非遮挡
python eval_things_noc_sf.py testset=flyingthings3d_subset_hpl model=camlipwc_l ckpt.path=checkpoints/camliraft_l_best_things_noc.pt
# 遮挡
python eval_things_occ_sf.py testset=flyingthings3d_subset_flownet3d model=camliraft_l ckpt.path=checkpoints/camliraft_l_best_things_occ.pt
KITTI
与FlyingThings3D一样,数据预处理有两种不同的方式。我们报告了两种设置的结果。
# 非遮挡
python eval_kitti_noc_sf.py testset=kitti model=camliraft_l ckpt.path=checkpoints/camliraft_l_best_kitti_noc.pt
# 遮挡
python eval_kitti_occ_sf.py testset=kitti model=camliraft_l ckpt.path=checkpoints/camliraft_l_best_kitti_occ.pt
训练
FlyingThings3D
在训练之前,您需要预处理FlyingThings3D数据集(详细说明请参见
preprocess_flyingthings3d_subset.py)。
在FlyingThings3D上训练CamLiRAFT(150个epoch):
python train.py trainset=flyingthings3d_subset valset=flyingthings3d_subset model=camliraft
整个训练过程在4个RTX 3090 GPU上大约需要3天。
KITTI
使用在FlyingThings3D上训练的权重在KITTI上微调模型:
python train.py trainset=kitti valset=kitti model=camliraft ckpt.path=checkpoints/camliraft_things150e.pt
整个训练过程在4块RTX 3090 GPU上大约需要0.5天。我们使用最后一个检查点(第800个)来生成提交结果。
引用
如果您在研究中发现它们有用,请引用:
@article{liu2023learning,
title = {Learning Optical Flow and Scene Flow with Bidirectional Camera-LiDAR Fusion},
author = {Haisong Liu and Tao Lu and Yihui Xu and Jia Liu and Limin Wang},
journal = {arXiv preprint arXiv:2303.12017},
year = {2023}
}
@inproceedings{liu2022camliflow,
title = {Camliflow: bidirectional camera-lidar fusion for joint optical flow and scene flow estimation},
author = {Liu, Haisong and Lu, Tao and Xu, Yihui and Liu, Jia and Li, Wenjie and Chen, Lijun},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages = {5791--5801},
year = {2022}
}











