
 访问官网
访问官网 Github
Github Huggingface
Huggingface 文档
文档 论文
论文





**PolyFuzz**执行模糊字符串匹配、字符串分组,并包含广泛的评估功能。PolyFuzz旨在将模糊字符串匹配技术整合到单一框架中。
目前,方法包括各种编辑距离度量、基于字符的n-gram TF-IDF、词嵌入技术(如FastText和GloVe),以及🤗 transformers嵌入。
相关的Medium文章可以在这里找到。
安装
您可以通过pip安装**PolyFuzz**:
pip install polyfuzz
根据您将使用的transformers和语言后端,您可能需要安装更多内容。可能的安装选项有:
pip install polyfuzz[sbert]
pip install polyfuzz[flair]
pip install polyfuzz[gensim]
pip install polyfuzz[spacy]
pip install polyfuzz[use]
如果您想在使用嵌入模型时加快余弦相似度比较并减少内存使用,可以使用sparse_dot_topn,通过以下方式安装:
pip install polyfuzz[fast]
安装问题
您可能会遇到sparse_dot_topn的安装问题。如果是这样,对许多人有效的一种解决方案是先通过conda安装它,然后再安装PolyFuzz:
conda install -c conda-forge sparse_dot_topn
如果这不起作用,我建议您查看他们的问题页面或继续使用不含sparse_dot_topn的PolyFuzz。
入门
要深入了解PolyFuzz的可能性,您可以查看这里的完整文档,或者跟随这个笔记本学习。
快速开始
PolyFuzz的主要目标是允许用户使用不同的方法来匹配字符串。我们首先定义两个列表,一个用于映射源,一个用于映射目标。我们将使用TF-IDF在字符级别创建n-gram,以比较字符串之间的相似性。然后,我们通过计算向量表示之间的余弦相似度来计算字符串之间的相似性。
我们只需要用TF-IDF实例化PolyFuzz并匹配列表:
from polyfuzz import PolyFuzz
from_list = ["apple", "apples", "appl", "recal", "house", "similarity"]
to_list = ["apple", "apples", "mouse"]
model = PolyFuzz("TF-IDF")
model.match(from_list, to_list)
可以通过model.get_matches()访问结果匹配:
>>> model.get_matches()
From To Similarity
0 apple apple 1.000000
1 apples apples 1.000000
2 appl apple 0.783751
3 recal None 0.000000
4 house mouse 0.587927
5 similarity None 0.000000
注意1:如果您想比较单个列表内的距离,可以简单地传递该列表:model.match(from_list)
注意2:在实例化PolyFuzz时,我们也可以使用"EditDistance"或"Embeddings"来快速访问Levenshtein和FastText(英语)。
生产环境
.match函数允许您快速提取相似的字符串。然而,在选择了正确的模型后,您可能希望在生产环境中使用PolyFuzz来匹配传入的字符串。为此,我们可以使用熟悉的fit、transform和fit_transform函数。
假设我们有一个已知正确的单词列表train_words。我们希望将任何传入的单词映射到train_words中的一个单词。换句话说,我们在train_words上fit,并在任何传入的单词上使用transform:
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer
from polyfuzz import PolyFuzz
train_words = ["apple", "apples", "appl", "recal", "house", "similarity"]
unseen_words = ["apple", "apples", "mouse"]
# 拟合
model = PolyFuzz("TF-IDF")
model.fit(train_words)
# 转换
results = model.transform(unseen_words)
在上面的例子中,我们在train_words上使用fit来计算这些单词的TF-IDF表示,这些表示被保存以便在transform中再次使用。这大大加快了transform的速度,因为在应用fit时所有TF-IDF表示都被存储。
然后,我们按如下方式保存和加载模型以在生产环境中使用:
# 保存模型
model.save("my_model")
# 加载模型
loaded_model = PolyFuzz.load("my_model")
分组匹配
我们可以对To匹配进行分组,因为我们的to_list中可能存在显著的字符串重叠。为此,我们计算to_list中字符串之间的相似性,并使用单链接来对具有高相似性的字符串进行分组。
当我们提取新的匹配时,我们可以看到一个额外的Group列,其中所有To匹配都被分组到:
>>> model.group(link_min_similarity=0.75)
>>> model.get_matches()
From To Similarity Group
0 apple apple 1.000000 apples
1 apples apples 1.000000 apples
2 appl apple 0.783751 apples
3 recal None 0.000000 None
4 house mouse 0.587927 mouse
5 similarity None 0.000000 None
如上所示,我们将apple和apples分组到apple,这样当一个字符串映射到apple时,它将落入[apples, apple]集群,并被映射到集群中的第一个实例,即apples。
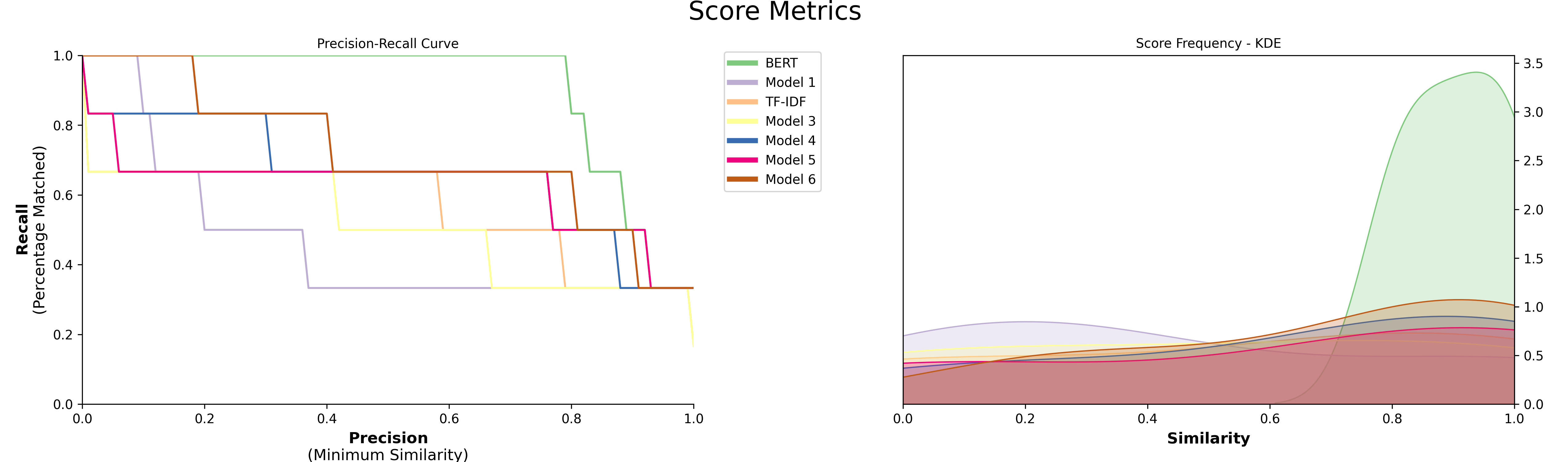
精确度-召回率曲线
接下来,我们想看看我们的模型在数据上表现如何。我们将结果表示为**精确度和召回率**,其中精确度定义为匹配正确的最小相似度分数,召回率是在特定最小相似度分数下找到的匹配百分比。
创建可视化非常简单:
model.visualize_precision_recall()

模型
目前,PolyFuzz中实现了以下模型:
- TF-IDF
- EditDistance(您可以使用任何距离度量,请参阅文档)
- FastText和GloVe
- 🤗 Transformers
使用Flair,我们可以使用所有🤗 Transformers 模型。我们只需实例化任何Flair WordEmbedding方法并通过PolyFuzzy传递即可。
上面列出的所有模型都可以在polyfuzz.models中找到,可以用来创建和比较不同的模型:
from polyfuzz.models import EditDistance, TFIDF, Embeddings
from flair.embeddings import TransformerWordEmbeddings
embeddings = TransformerWordEmbeddings('bert-base-multilingual-cased')
bert = Embeddings(embeddings, min_similarity=0, model_id="BERT")
tfidf = TFIDF(min_similarity=0)
edit = EditDistance()
string_models = [bert, tfidf, edit]
model = PolyFuzz(string_models)
model.match(from_list, to_list)
要访问结果,我们同样可以调用get_matches,但由于我们有多个模型,所以会得到一个字典形式的数据框。
要访问特定模型的结果,请使用正确的id调用get_matches:
>>> model.get_matches("BERT")
From To Similarity
0 apple apple 1.000000
1 apples apples 1.000000
2 appl apple 0.928045
3 recal apples 0.825268
4 house mouse 0.887524
5 similarity mouse 0.791548
最后,可视化结果以比较各个模型:
model.visualize_precision_recall(kde=True)
自定义分组器
我们甚至可以使用polyfuzz.models中的一个作为分组器,以防你想使用标准TF-IDF模型以外的其他模型:
model = PolyFuzz("TF-IDF")
model.match(from_list, to_list)
edit_grouper = EditDistance(n_jobs=1)
model.group(edit_grouper)
自定义模型
尽管上述选项是比较不同模型的绝佳解决方案,但如果你开发了自己的模型怎么办?
如果你遵循PolyFuzz的BaseMatcher结构,
你可以快速实现任何你想要的模型。
下面,我们正在实现RapidFuzz中的比率相似度度量。
import numpy as np
import pandas as pd
from rapidfuzz import fuzz
from polyfuzz.models import BaseMatcher
class MyModel(BaseMatcher):
def match(self, from_list, to_list, **kwargs):
# 计算距离
matches = [[fuzz.ratio(from_string, to_string) / 100 for to_string in to_list]
for from_string in from_list]
# 获取最佳匹配
mappings = [to_list[index] for index in np.argmax(matches, axis=1)]
scores = np.max(matches, axis=1)
# 准备数据框
matches = pd.DataFrame({'From': from_list,'To': mappings, 'Similarity': scores})
return matches
然后,我们可以简单地创建MyModel的实例并将其传递给PolyFuzz:
custom_model = MyModel()
model = PolyFuzz(custom_model)
引用
要在你的工作中引用PolyFuzz,请使用以下bibtex引用:
@misc{grootendorst2020polyfuzz,
author = {Maarten Grootendorst},
title = {PolyFuzz: Fuzzy string matching, grouping, and evaluation.},
year = 2020,
publisher = {Zenodo},
version = {v0.2.2},
doi = {10.5281/zenodo.4461050},
url = {https://doi.org/10.5281/zenodo.4461050}
}
参考文献
以下是在开发PolyFuzz时使用或受到启发的几个资源:
编辑距离算法:
这些算法主要关注编辑距离度量,可以在polyfuzz.models.EditDistance中使用:
- https://github.com/jamesturk/jellyfish
- https://github.com/ztane/python-Levenshtein
- https://github.com/seatgeek/fuzzywuzzy
- https://github.com/maxbachmann/rapidfuzz
- https://github.com/roy-ht/editdistance
其他有趣的仓库:
- https://github.com/ing-bank/sparse_dot_topn
- 在PolyFuzz中用于快速计算稀疏矩阵之间的余弦相似度











