
 访问官网
访问官网 Github
Github 文档
文档 论文
论文




同义词
用于自然语言处理和理解的中文同义词。
更好的中文近义词:聊天机器人、智能问答工具包。
synonyms可用于自然语言理解的多项任务:文本对齐、推荐算法、相似度计算、语义偏移、关键词提取、概念提取、自动摘要、搜索引擎等。
为提供稳定、可靠、长期优化的服务,Synonyms 改为使用春松许可证, v1.0并对机器学习模型的下载收费,详见证书商店。之前的贡献者(有突出贡献的代码贡献者)可与我们联系,讨论收费问题。-- Chatopera Inc. @ 2023年10月
目录:
欢迎
按照以下步骤安装并激活软件包。
1/3 安装源代码包
pip install -U synonyms
当前稳定版本为 v3.x。
2/3 配置许可证ID
Synonyms的机器学习模型包需要从Chatopera许可证商店获取许可证,首先购买许可证并从Chatopera许可证商店的许可证页面获取许可证ID(许可证ID:在证书商店,证书详情页,点击【复制证书标识】)。
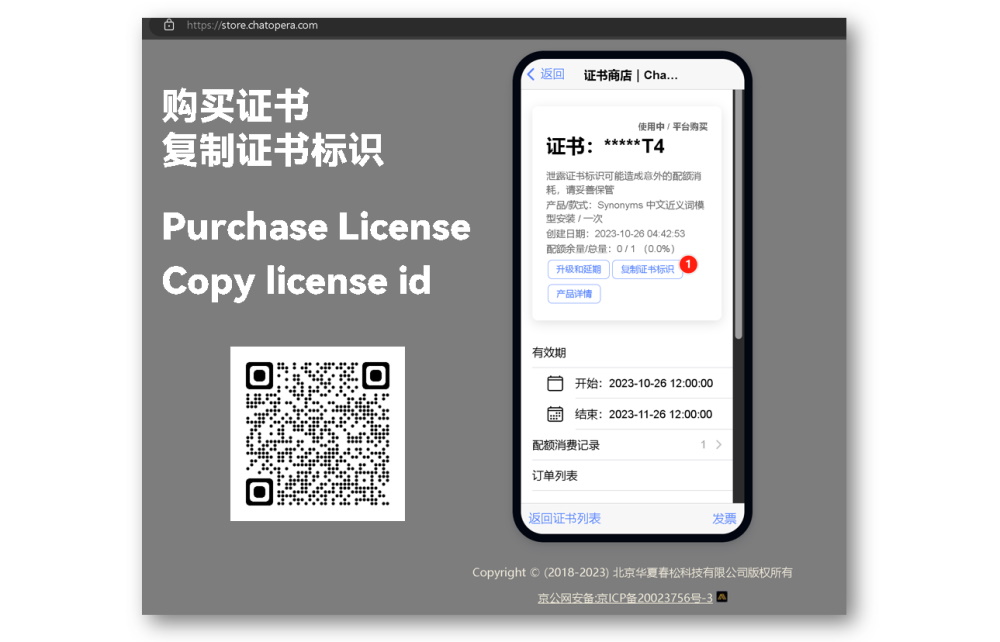
其次,在终端或shell脚本中设置环境变量,如下所示。
- Shell用户
例如Linux、Windows、macOS上的Shell、CMD脚本。
# Linux / macOS
export SYNONYMS_DL_LICENSE=YOUR_LICENSE
## 例如,如果您的许可证ID为`FOOBAR`,运行`export SYNONYMS_DL_LICENSE=FOOBAR`
# Windows
## 1/2 命令提示符
set SYNONYMS_DL_LICENSE=YOUR_LICENSE
## 2/2 PowerShell
$env:SYNONYMS_DL_LICENSE='YOUR_LICENSE'
- Python代码用户
Jupyter Notebook等。
import os
os.environ["SYNONYMS_DL_LICENSE"] = "YOUR_LICENSE"
_licenseid = os.environ.get("SYNONYMS_DL_LICENSE", None)
print("SYNONYMS_DL_LICENSE=", _licenseid)
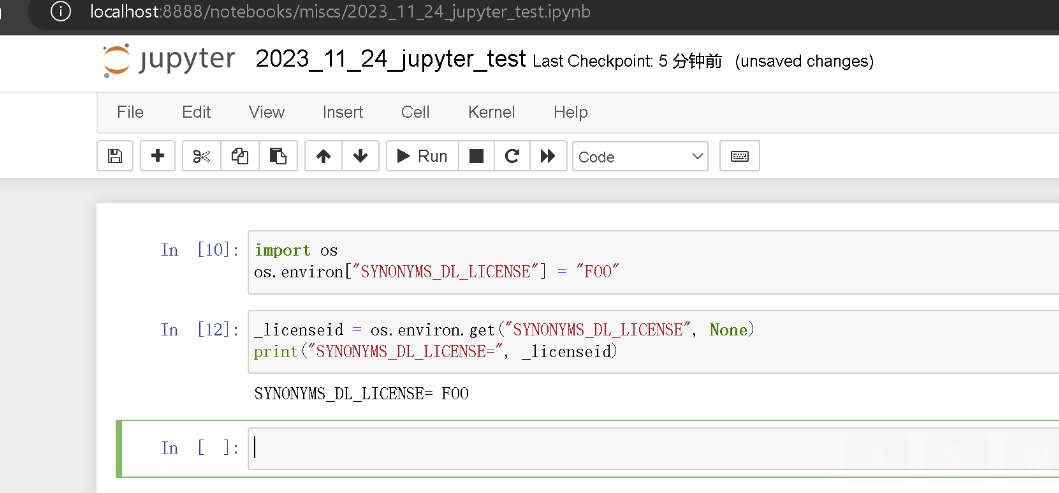
提示:安装后首次使用会下载词向量文件,下载速度取决于网络情况。
3/3 下载模型包
最后,通过命令或脚本下载模型包 -
python -c "import synonyms; synonyms.display('能量')" # 下载词向量文件
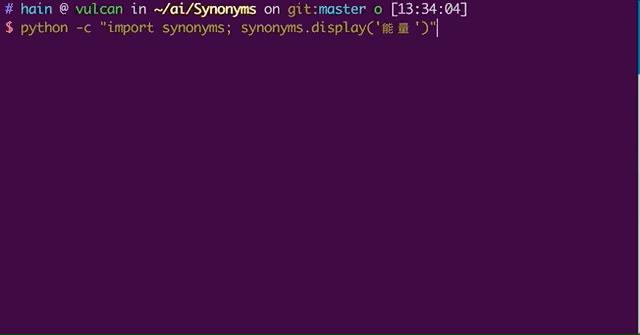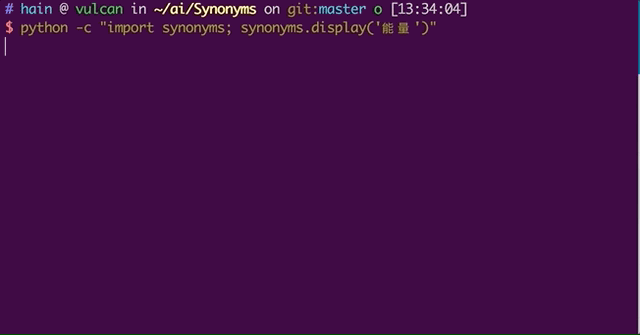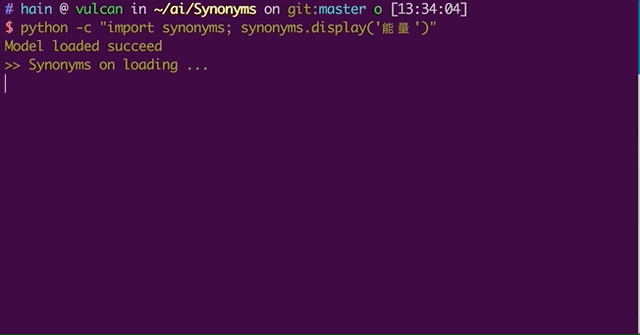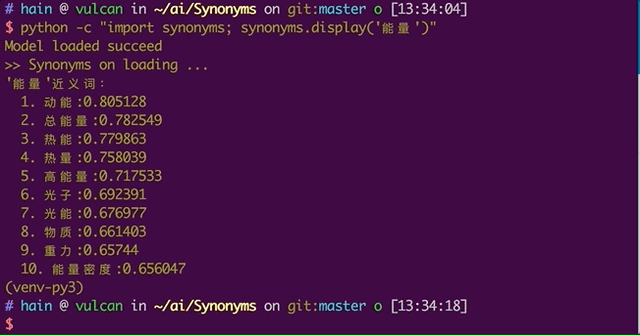
使用
支持使用环境变量配置分词词表和word2vec词向量文件。
| 环境变量 | 描述 |
|---|---|
| SYNONYMS_WORD2VEC_BIN_MODEL_ZH_CN | 使用word2vec训练的词向量文件,二进制格式。 |
| SYNONYMS_WORDSEG_DICT | 中文分词主字典,格式和使用参考 |
| SYNONYMS_DEBUG | ["TRUE"|"FALSE"],是否输出调试日志,设置为"TRUE"输出,默认为"FALSE" |
synonyms#nearby(word [, size = 10])
import synonyms
print("人脸: ", synonyms.nearby("人脸"))
print("识别: ", synonyms.nearby("识别"))
print("NOT_EXIST: ", synonyms.nearby("NOT_EXIST"))
synonyms.nearby(WORD [,SIZE])返回一个元组,元组中包含两项:([nearby_words], [nearby_words_score]),nearby_words是WORD的近义词,以list形式存储,并按距离由近及远排列,nearby_words_score是nearby_words中对应位置词的距离分数,分数在(0-1)区间内,越接近1表示越相近;SIZE是返回词汇数量,默认为10。例如:
synonyms.nearby(人脸, 10) = (
["图片", "图像", "通过观察", "数字图像", "几何图形", "脸部", "图象", "放大镜", "面孔", "Mii"],
[0.597284, 0.580373, 0.568486, 0.535674, 0.531835, 0.530
095, 0.525344, 0.524009, 0.523101, 0.516046])
在OOV(词汇表外)的情况下,返回([], []),目前的字典大小:435,729。
synonyms#compare(sen1, sen2 [, seg=True])
比较两个句子的相似度
sen1 = "发生历史性变革"
sen2 = "发生历史性变革"
r = synonyms.compare(sen1, sen2, seg=True)
其中,参数seg表示synonyms.compare是否对sen1和sen2进行分词,默认为True。返回值:[0-1],越接近1表示两个句子越相似。
旗帜引领方向 vs 道路决定命运: 0.429
旗帜引领方向 vs 旗帜指引道路: 0.93
发生历史性变革 vs 发生历史性变革: 1.0
synonyms#display(word [, size = 10])
以友好的方式打印近义词,方便调试,display(WORD [, SIZE])调用了 synonyms#nearby 方法。
>>> synonyms.display("飞机")
'飞机'近义词:
1. 飞机:1.0
2. 直升机:0.8423391
3. 客机:0.8393003
4. 滑翔机:0.7872388
5. 军用飞机:0.7832081
6. 水上飞机:0.77857226
7. 运输机:0.7724742
8. 航机:0.7664748
9. 航空器:0.76592904
10. 民航机:0.74209654
SIZE 是打印词汇表的数量,默认 10。
synonyms#describe()
打印当前包的描述信息:
>>> synonyms.describe()
词向量模型中的词汇量: 435729
模型路径: /Users/hain/chatopera/Synonyms/synonyms/data/words.vector.gz
版本: 3.18.0
{'vocab_size': 435729, 'version': '3.18.0', 'model_path': '/chatopera/Synonyms/synonyms/data/words.vector.gz'}
synonyms#v(word)
获得一个词语的向量,该向量为 numpy 的 array,当该词语是未登录词时,抛出 KeyError 异常。
>>> synonyms.v("飞机")
array([-2.412167 , 2.2628384 , -7.0214124 , 3.9381874 , 0.8219283 ,
-3.2809453 , 3.8747153 , -5.217062 , -2.2786229 , -1.2572327 ],
dtype=float32)
synonyms#sv(sentence, ignore=False)
获得一个分词后句子的向量,向量以 BoW 方式组成
sentence: 句子是分词后通过空格联合起来
ignore: 是否忽略OOV,False时,随机生成一个向量
synonyms#seg(sentence)
中文分词
synonyms.seg("中文近义词工具包")
分词结果,由两个 list 组成的元组,分别是单词和对应的词性。
(['中文', '近义词', '工具包'], ['nz', 'n', 'n'])
该分词不去停用词和标点。
synonyms#keywords(sentence [, topK=5, withWeight=False])
提取关键词,默认按照重要程度提取关键词。
keywords = synonyms.keywords("9月15日以来,台积电、高通、三星等华为的重要合作伙伴,只要没有美国的相关许可证,都无法供应芯片给华为,而中芯国际等国产芯片企业,也因采用美国技术,而无法供货给华为。目前华为部分型号的手机产品出现货少的现象,若该形势持续下去,华为手机业务将遭受重创。")
贡献
获取更多调试日志,设置环境变量。
SYNONYMS_DEBUG=TRUE
PCA
以"人脸"为例主要成分分析:

快速开始
$ pip install -r Requirements.txt
$ python demo.py
更新日志
更新情况说明。
用户评价
用户怎么说:
数据
数据基于wikidata-corpus构建。
评估
同义词词林
《同义词词林》是梅家驹等人于1983年编纂而成,现在使用广泛的是哈工大社会计算与信息检索研究中心维护的《同义词词林扩展版》,它精细的将中文词汇划分成大类和小类,梳理了词汇间的关系,同义词词林扩展版包含词语7万余条,其中3万余条被以开放数据形式共享。
知网, HowNet
HowNet,也被称为知网,它并不只是一个语义字典,而是一个知识系统,词汇之间的关系是其一个基本使用场景。知网包含词语8余条。
国际上对词语相似度算法的评价标准普遍采用Miller&Charles发布的英语词对集的人工判定值。该词对集由十对高度相关、十对中度相关、十对低度相关共30个英语词对组成,然后让38个受试者对这30对进行语义相关度判断,最后取他们的平均值作为人工判定标准。然后不同近义词工具也对这些词汇进行相似度评分,与人工判定标准做比较,比如使用皮尔森相关系数。在中文领域,使用这个词表的翻译版进行中文近义词比较也是常用的办法。
对比
Synonyms的词表容量是435,729,下面选择一些在同义词词林、知网和Synonyms都存在的几个词,给出其近似度的对比:
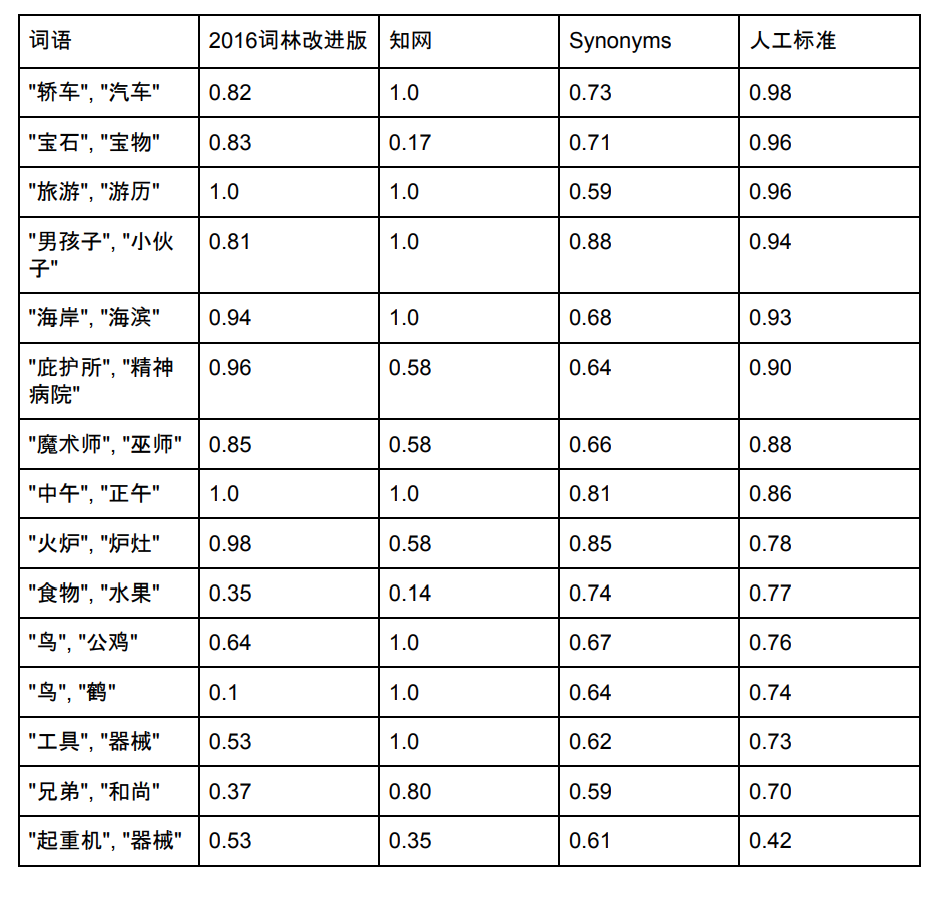
注:同义词林及知网数据、分数来源。Synonyms也在不断优化中,新的分数可能和上图不一致。
更多比对结果。
使用者
基准测试
使用 py3 在 MacBook Pro 上测试。
python benchmark.py
++++++++++ 操作系统名称和版本 ++++++++++
平台: Darwin
内核: 16.7.0
架构: ('64bit', '')
++++++++++ CPU 核心数 ++++++++++
核心数: 4
CPU 负载: 60
++++++++++ 系统内存 ++++++++++
内存信息 8GB
synonyms#nearby: 100000 次循环,3 个周期中最佳: 0.209 微秒/循环
在线分享
线上分享实录:Synonyms 中文近义词工具包 @ 2018-02-07
声明
Synonyms采用MIT许可证发布。数据和程序可用于研究和商业产品,必须注明引用和地址,例如在发布的任何媒体、期刊、杂志或博客等内容中。
@online{Synonyms:hain2017,
author = {Hai Liang Wang, Hu Ying Xi},
title = {中文近义词工具包Synonyms},
year = 2017,
url = {https://github.com/chatopera/Synonyms},
urldate = {2017-09-27}
}
参考文献
常见问题(FAQ)
- 是否支持添加单词到词表中?
不支持,欲了解更多请看 #5
- 词向量的训练是用哪个工具?
Google 发布的word2vec,该库由 C 语言编写,内存使用效率高,训练速度快。gensim 可以加载 word2vec 输出的模型文件。
- 相似度计算的方法是什么?
作者
自然语言处理推荐入门&工具书
本书由 Synonyms 作者参与著作。
快速购书链接

《智能问答与深度学习》 这本书面向准备入门机器学习和自然语言处理的学生和软件工程师,在理论上介绍了许多原理和算法,同时也提供了大量示例程序以增加实践性。这些程序被汇总到示例程序代码库中,主要用于帮助大家理解原理和算法,欢迎大家下载和执行。代码库的地址是:
https://github.com/l11x0m7/book-of-qna-code
致谢
许可证
项目赞助商
Chatopera 云服务
Chatopera 云服务是一站式实现聊天机器人的云服务,按接口调用次数计费。Chatopera 云服务是 Chatopera 机器人平台的软件即服务实例。在云计算基础上,Chatopera 云服务属于聊天机器人即服务的云服务。
Chatopera 机器人平台包括知识库、多轮对话、意图识别和语音识别等组件,标准化聊天机器人开发,支持企业 OA 智能问答、HR 智能问答、智能客服和网络营销等场景。企业 IT 部门、业务部门借助 Chatopera 云服务快速让聊天机器人上线!











